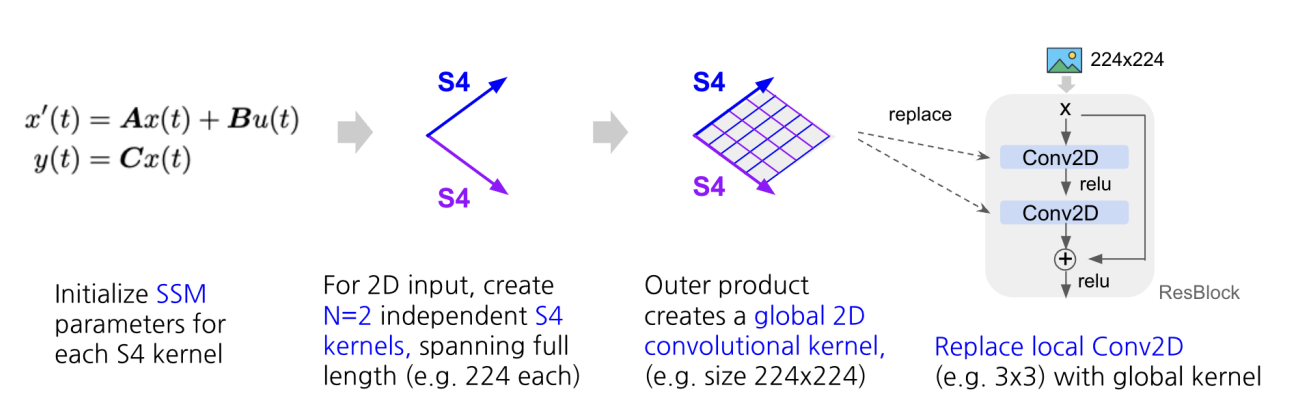
Mamba의 등장 이후, SSMs를 다양한 분야에 적용해보려는 연구들이 다수 등장하고 있고, 하루의 시간차를 가지고 Vision Mamba와 VMamba가 arxiv에 게재되었다.
Vision Mamba는 Bidirectional Mamba를, VMamba는 Cross-Scan Module를 활용하여 ViT가 가진 back-bone 기능을 대체하려고 한다.
이번 리뷰에서는 Vision Mamba와 VMamba를 비교하고, 이전 세대의 S4 모델을 활용했던 비전 모델인 S4ND와의 비교도 수행해보려고 한다.
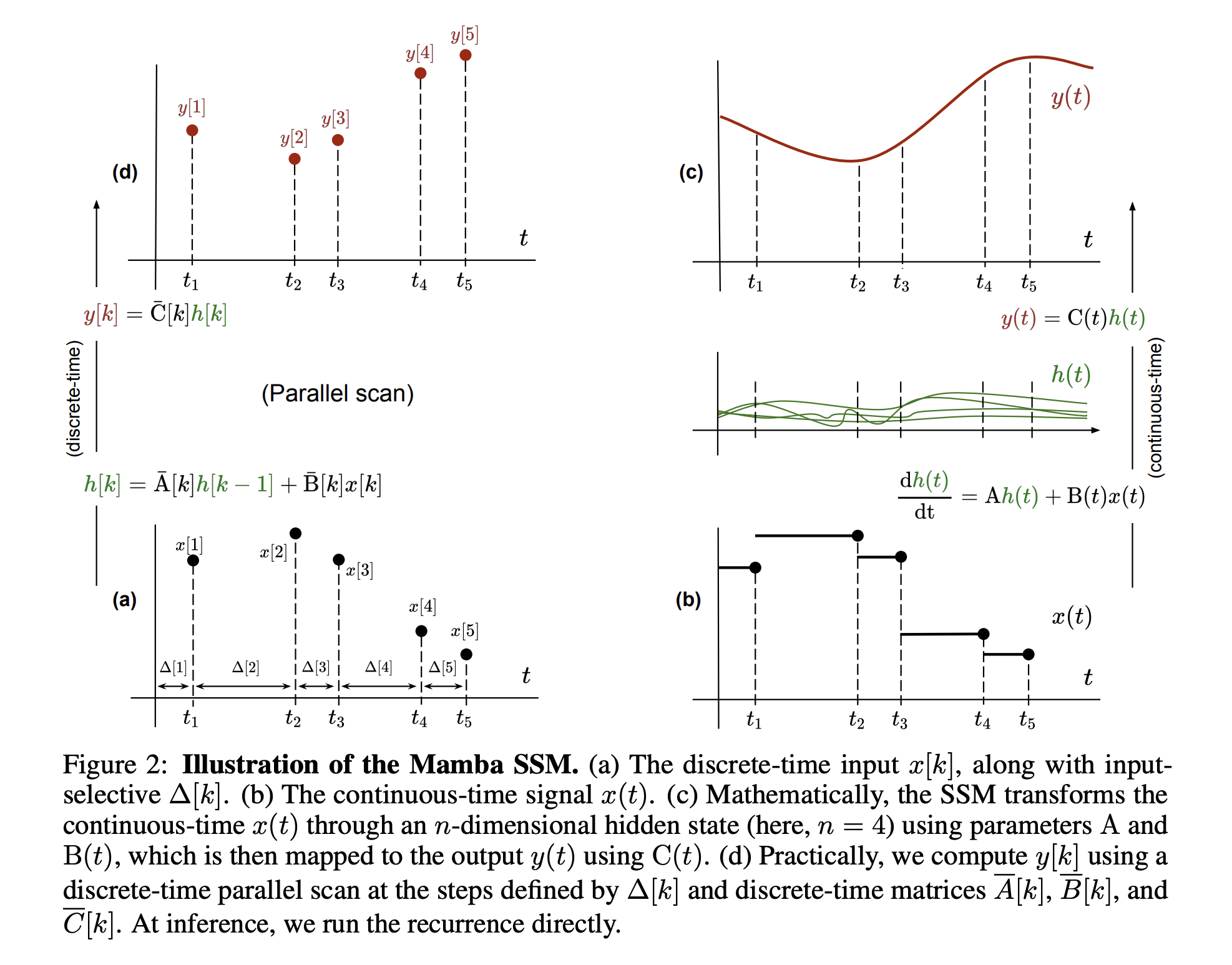
Mamba SSM
- figure from recent paper 'MambaByte: Token-free Selective State Space Model'
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
2024.01.18
Code
Abstract
Recently the state space models (SSMs) with efficient hardware-aware designs, i.e., Mamba, have shown great potential for long sequence modeling. Building efficient and generic vision backbones purely upon SSMs is an appealing direction. However, representing visual data is challenging for SSMs due to the position-sensitivity of visual data and the requirement of global context for visual understanding.
In this paper, we show that the reliance of visual representation learning on self-attention is not necessary and propose a new generic vision backbone with bidirectional Mamba blocks (Vim), which marks the image sequences with position embeddings and compresses the visual representation with bidirectional state space models. On ImageNet classification, COCO object detection, and ADE20k semantic segmentation tasks, Vim achieves higher performance compared to well-established vision transformers like DeiT,
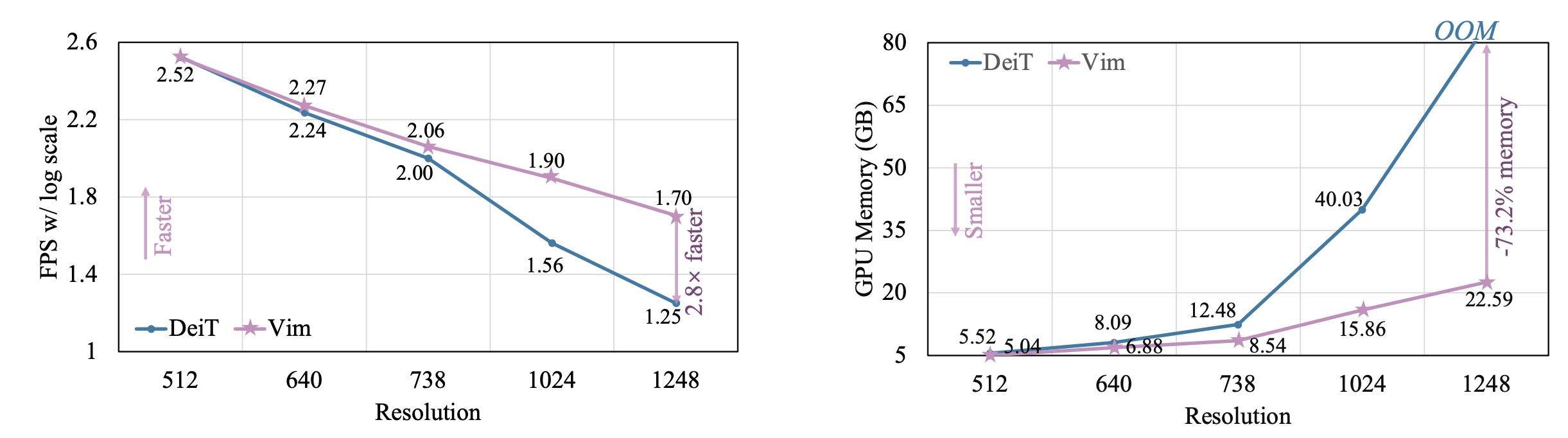
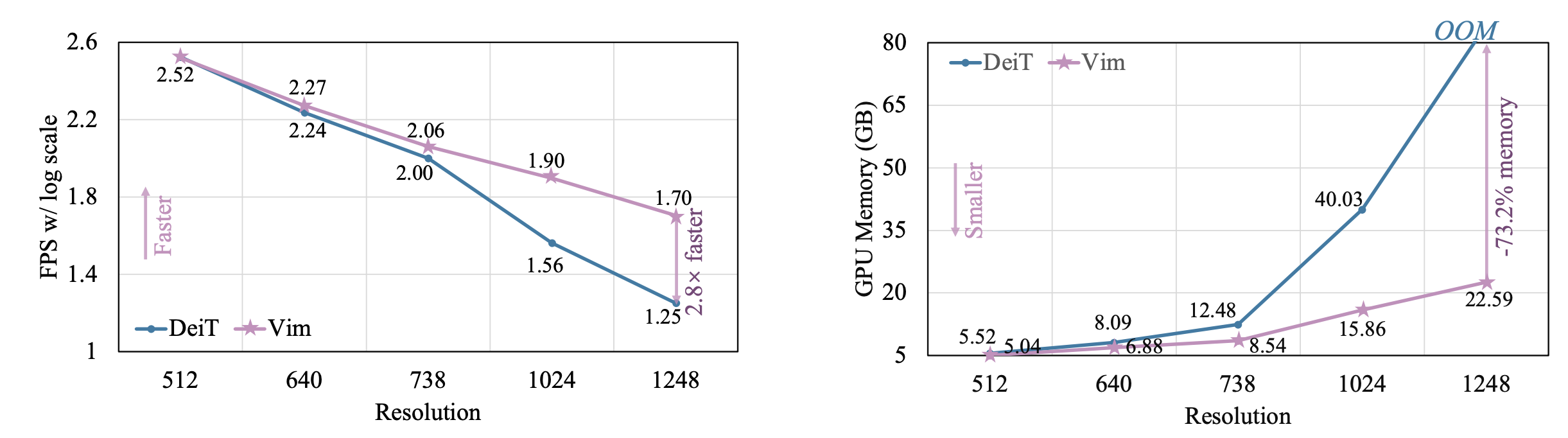
while also demonstrating significantly improved computation & memory efficiency. For example, Vim is 2.8× faster than DeiT and saves 86.8% GPU memory when performing batch inference to extract features on images with a resolution of 1248×1248. The results demonstrate that Vim is capable of overcoming the computation & memory constraints on performing Transformer-style understanding for high-resolution images and it has great potential to become the next-generation backbone for vision foundation models.
Backgrounds
Pure SSM based vision model
- A generic pure-SSM-based backbone has not been explored for vision tasks.
ViT vs CNNs
- ViT can provide each patch with global context through self-attention, while CNN uses same convolutional filters for all positions.
- ViTs can use modality-agnostic modeling by treating an image as a sequence of patches without 2D inductive bias, which makes it the preferred architecture for multimodal applications
Mamba
- Success in language modeling
- Two challenges for Mamba(unidirectional modeling and lack of positional awareness)
- Explore building a pure-SSM-based model as a generic vision backbone without using attention, while preserving the sequential, modality-agnostic modeling merit of ViT.
State space models for long sequence modeling
- Structured State-Space Sequence (S4) model
- S5 (MIMO SSM and efficient parallel scan)
- H3
- Gated State Space layer on S4
- Mamba
State Space models for visual applications
- ViS4mer (long-range temporal dependencies for video classification)
- S4ND (multi-dimensional data handling-2D, 3D)
- TranS4mer (state-of-the-art performance for movie scene detection)
- Selective S4(S5 model- model selectivity mechanism, long-form video understanding)
- U-Mamba (hybrid CNN-SSM for biomedical image segmentation)
=> All of them are hybrid or domain specific
Main Contributions
Vision Mamba(Vim)
- bidirectional SSM
- data-dependant global visual context modeling
- position embeddings for location-aware visual understanding
vs ViT
- Same modeling power without attention
- subquadratic-time computation & linear memory complexity
- 2.8 faster than DeiT, saving 86% GPU memory when performing batch inference to extract features on images at resolution 1248 1248
Vision Mamba
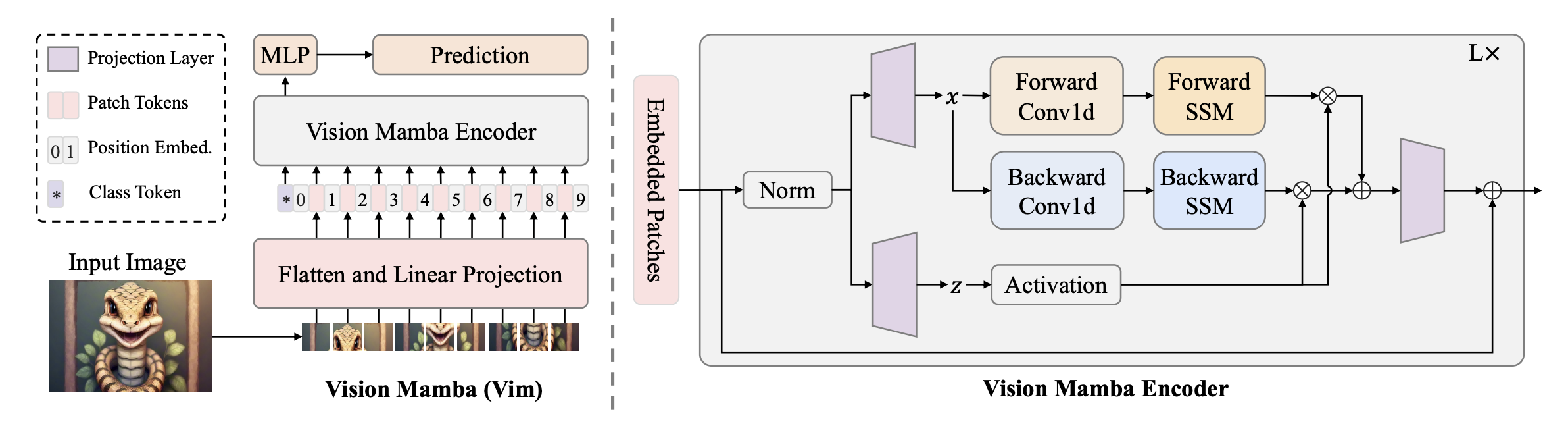
(2D image) => (flattened patch) =[linear projection]=>
( is learnable projection matrix)
Vim Block

Experiment
Image Classification(ImageNet-1K)
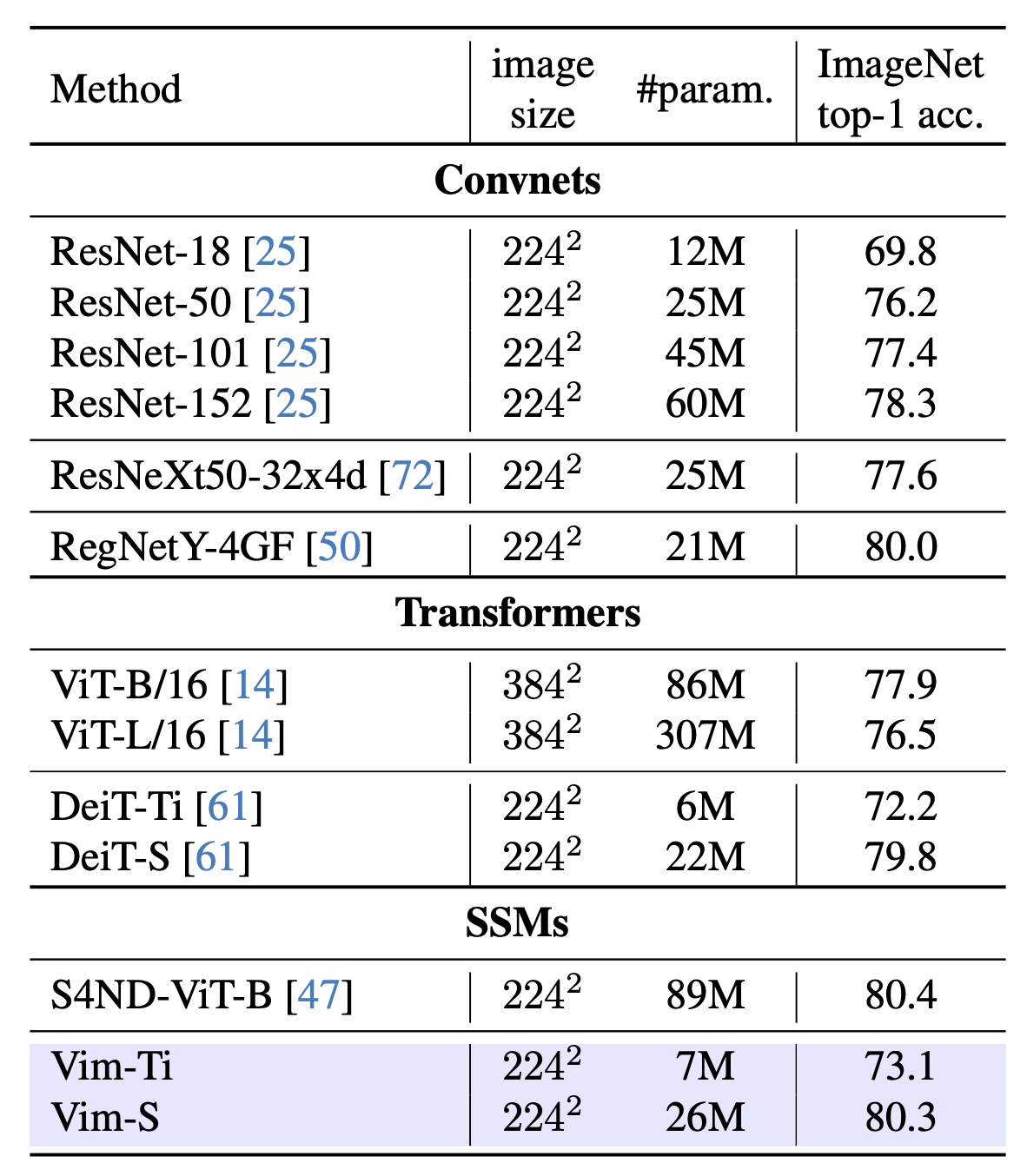
- Shows good result on imagenet data
Semantic Segmentation (ADE20K)
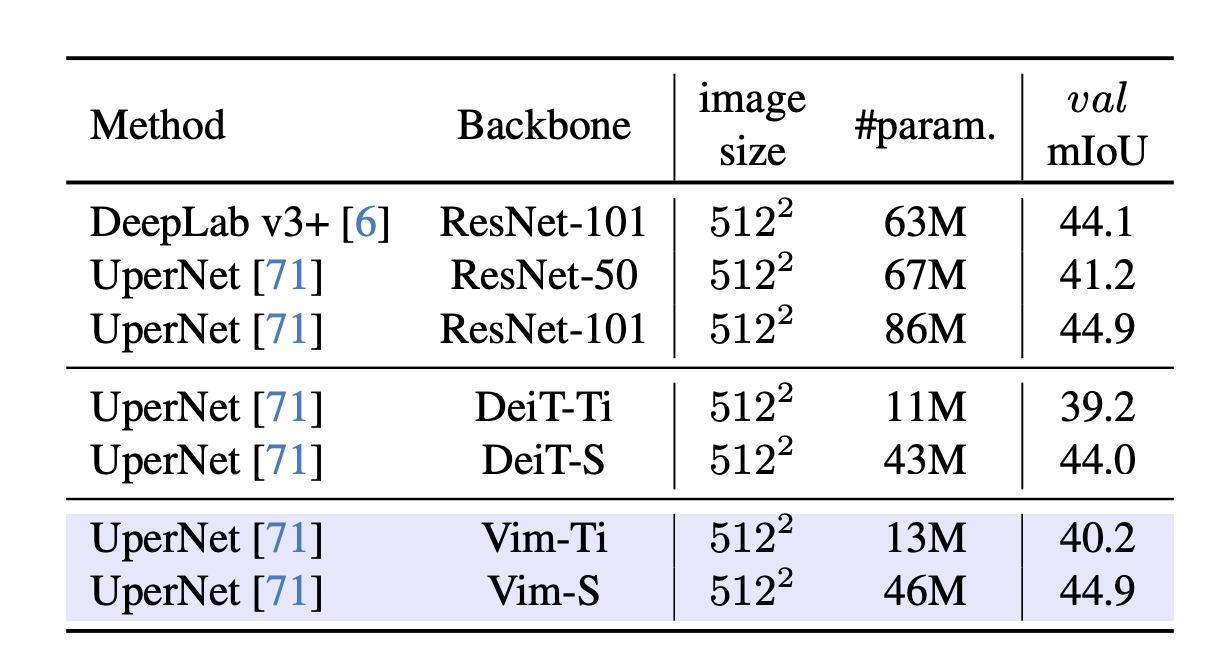
-
Shows strong result in segmentation
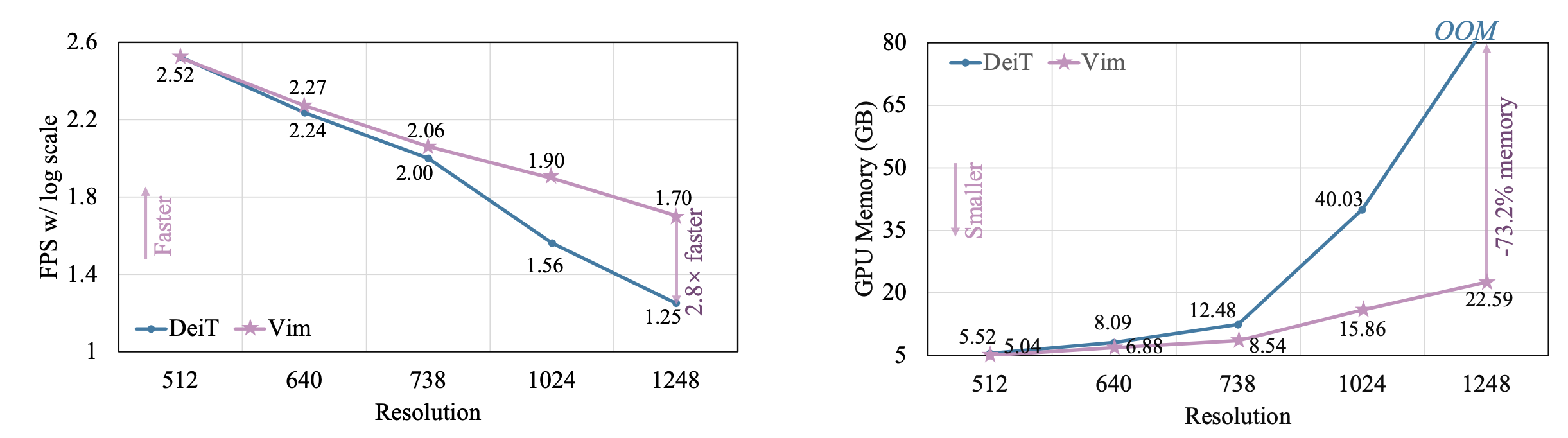
-
Throughput data speed and memory efficiency is great
Object detection and instance segmentation
Ablation Study
- Using naive Mamba lead to best result on image classification, but its performance in segmentation is lower.
- Using bidirectionality made it work better at segmentation, while achieving similar classification accuracy.
Questions
- Too small benchmark results
- Small model size
VMamba: Visual State Space Model
2024.01.19
Code
https://github.com/MzeroMiko/VMamba
Abstract
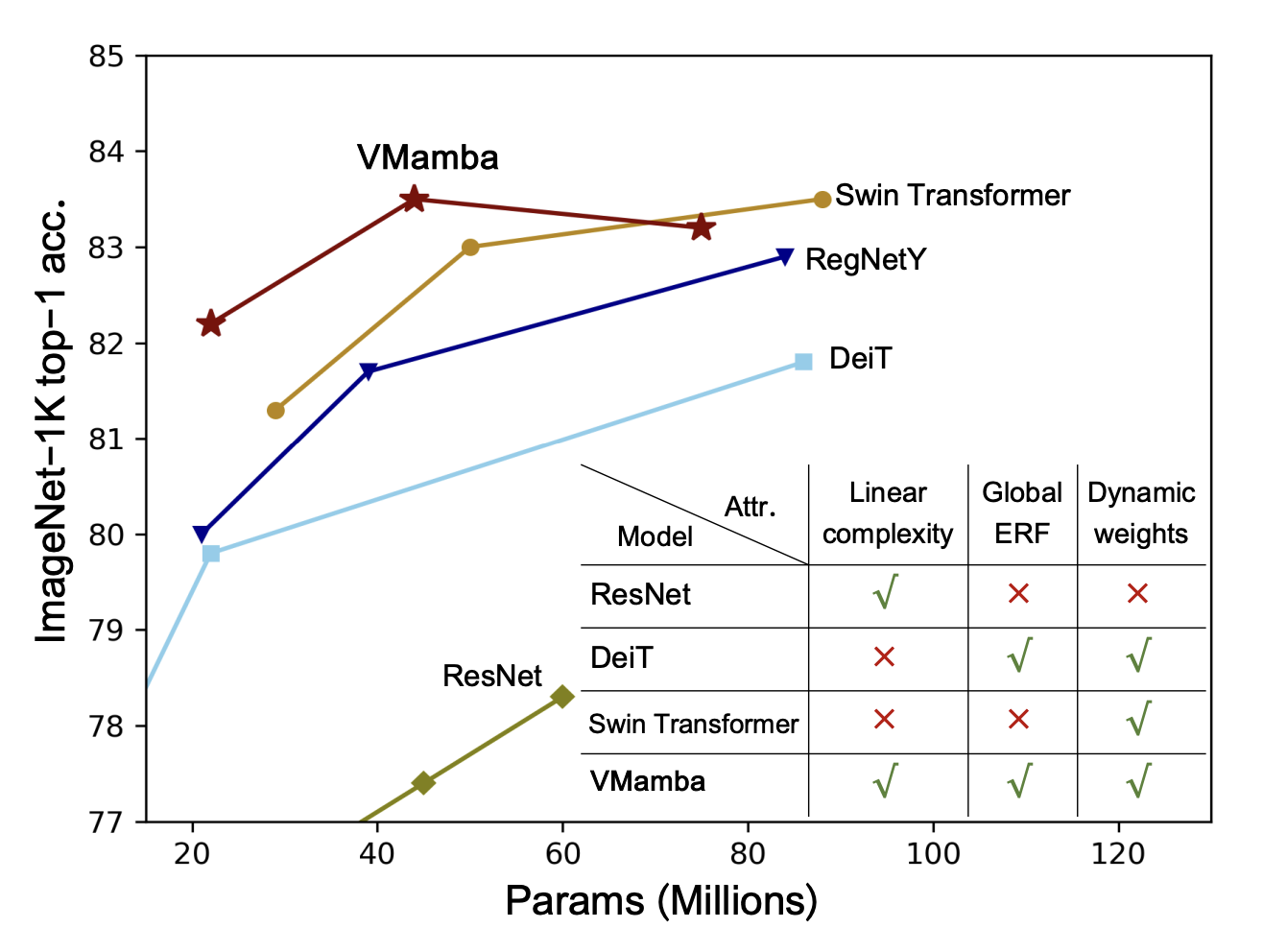
Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) stand as the two most popular foundation models for visual representation learning. While CNNs exhibit remarkable scalability with linear complexity w.r.t. image resolution, ViTs surpass them in fitting capabilities despite contending with quadratic complexity. A closer inspection reveals that ViTs achieve superior visual modeling performance through the incorporation of global receptive fields and dynamic weights. This observation motivates us to propose a novel architecture that inherits these components while enhancing computational efficiency.
To this end, we draw inspiration from the recently introduced state space model and propose the Visual State Space Model (VMamba), which achieves linear complexity without sacrificing global receptive fields.
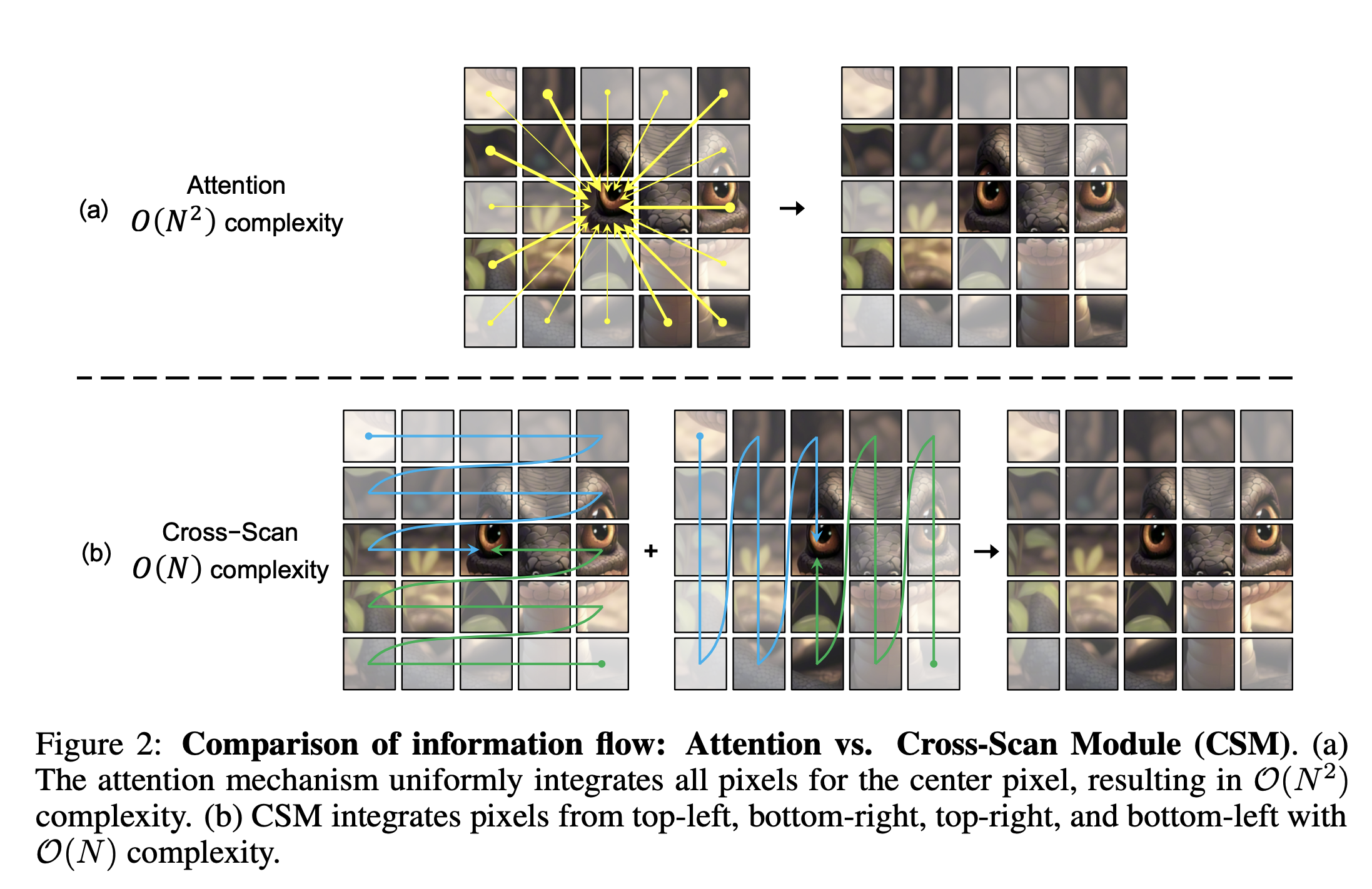
To address the encountered direction-sensitive issue, we introduce the Cross-Scan Module (CSM) to traverse the spatial domain and convert any non-causal visual image into order patch sequences.
Extensive experimental results substantiate that VMamba not only demonstrates promising capabilities across various visual perception tasks, but also exhibits more pronounced advantages over established benchmarks as the image resolution increases.
Introduction & Backgrounds
- Non-causal nature of visual data -> restricted receptive fields
- relation ships against unscanned patches could not be estimated
=> direction-sensitive problem -> address with Cross-Scan Module(CSM)
CSM
- four-way scanning (from four corners all across the feature map to the opposite location)
VMamba Model
2D-Selective-Scan
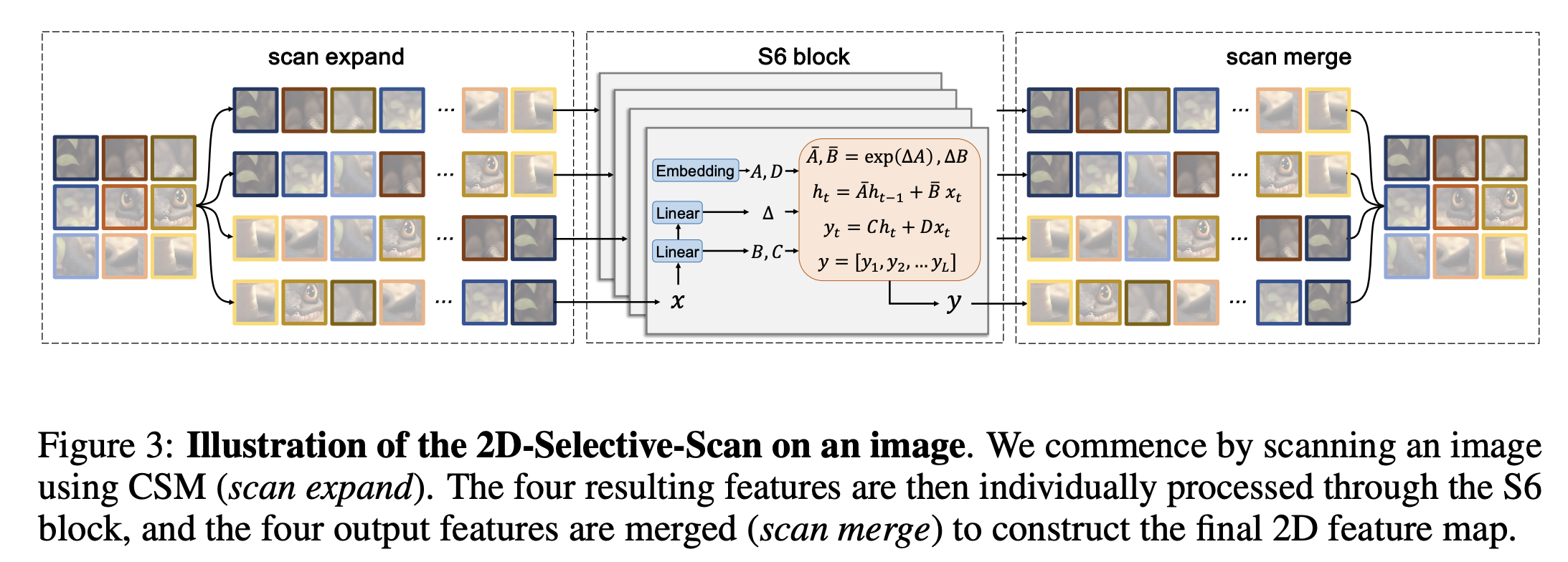
Model architecture
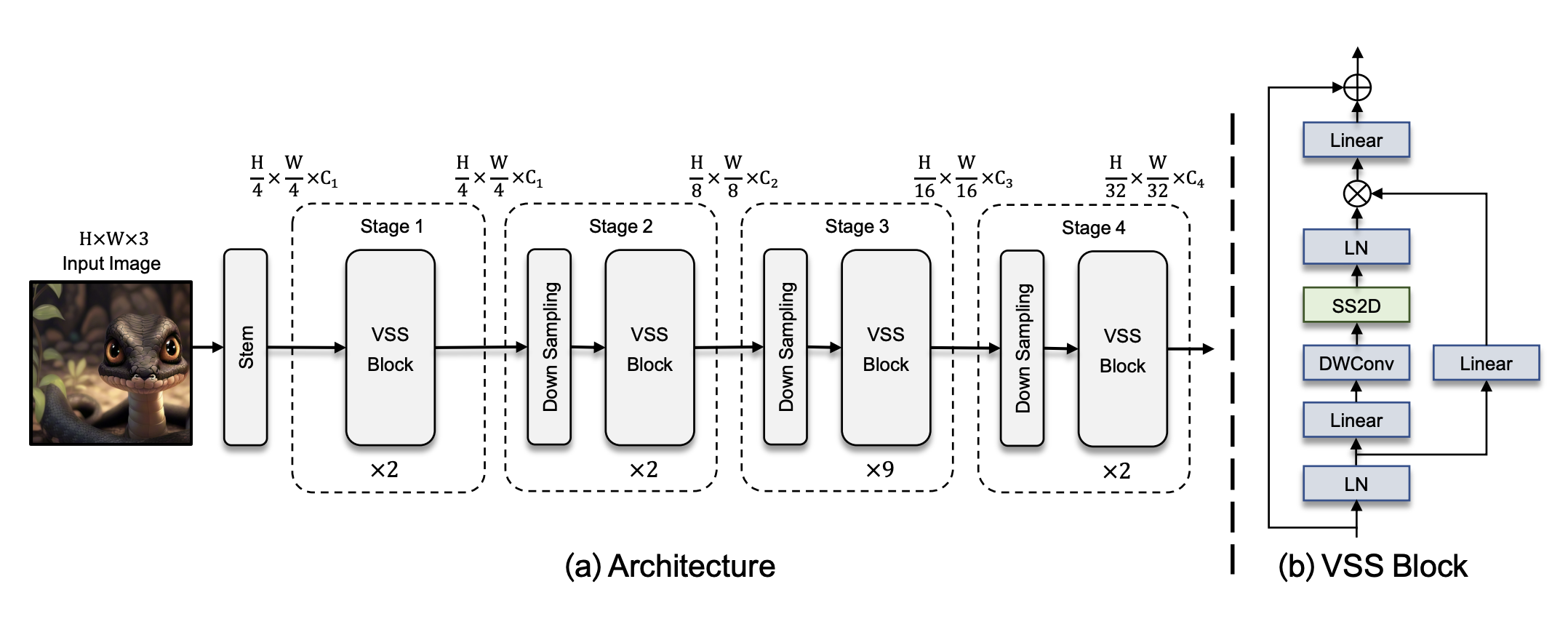
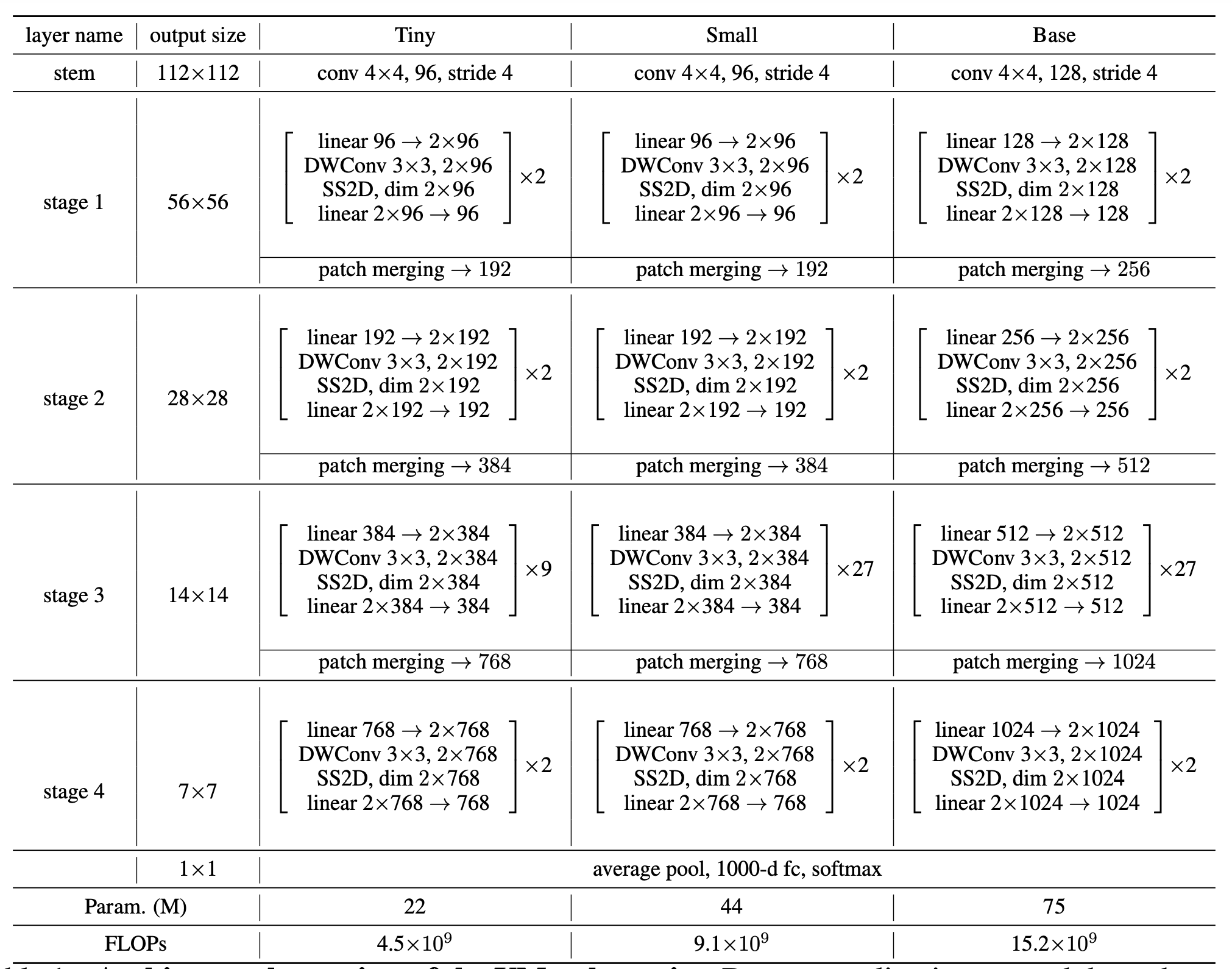
- Architecture of VMamba-Tiny
Steps of Vmamba
- Partitioning input image into patches (without flattening the patches - preserves 2D structure of images)
- Stage1 -> stack of VSS blocks (same dimension)
- Stage2 -> Downsampling through patch merge operation(Swin Transformers v2) + Stack of VSS blocks
- Stage3 & Stage4 -> Downsampling + VSS block
VSS Block
- LN==> LN ==> conv ==> SS2D(CSM) ==> LN ==>
- Refrain from utilizing position embedding bias in VMamba due to its causal nature
- Discarded MLP operation(<-> Norm -> attention -> Norm -> MLP of ViT)
Experiments
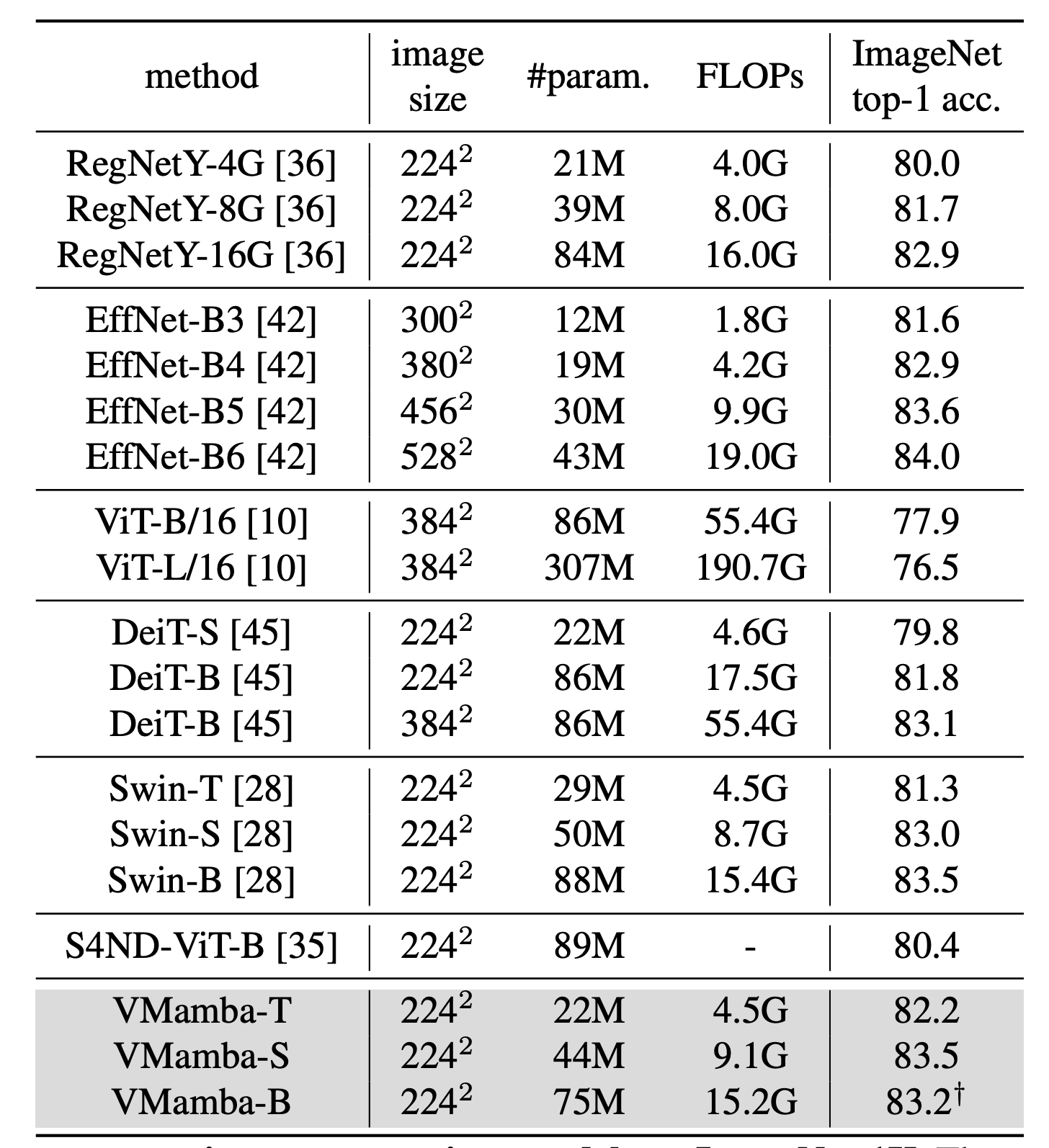
Image Classification on ImageNet-1K
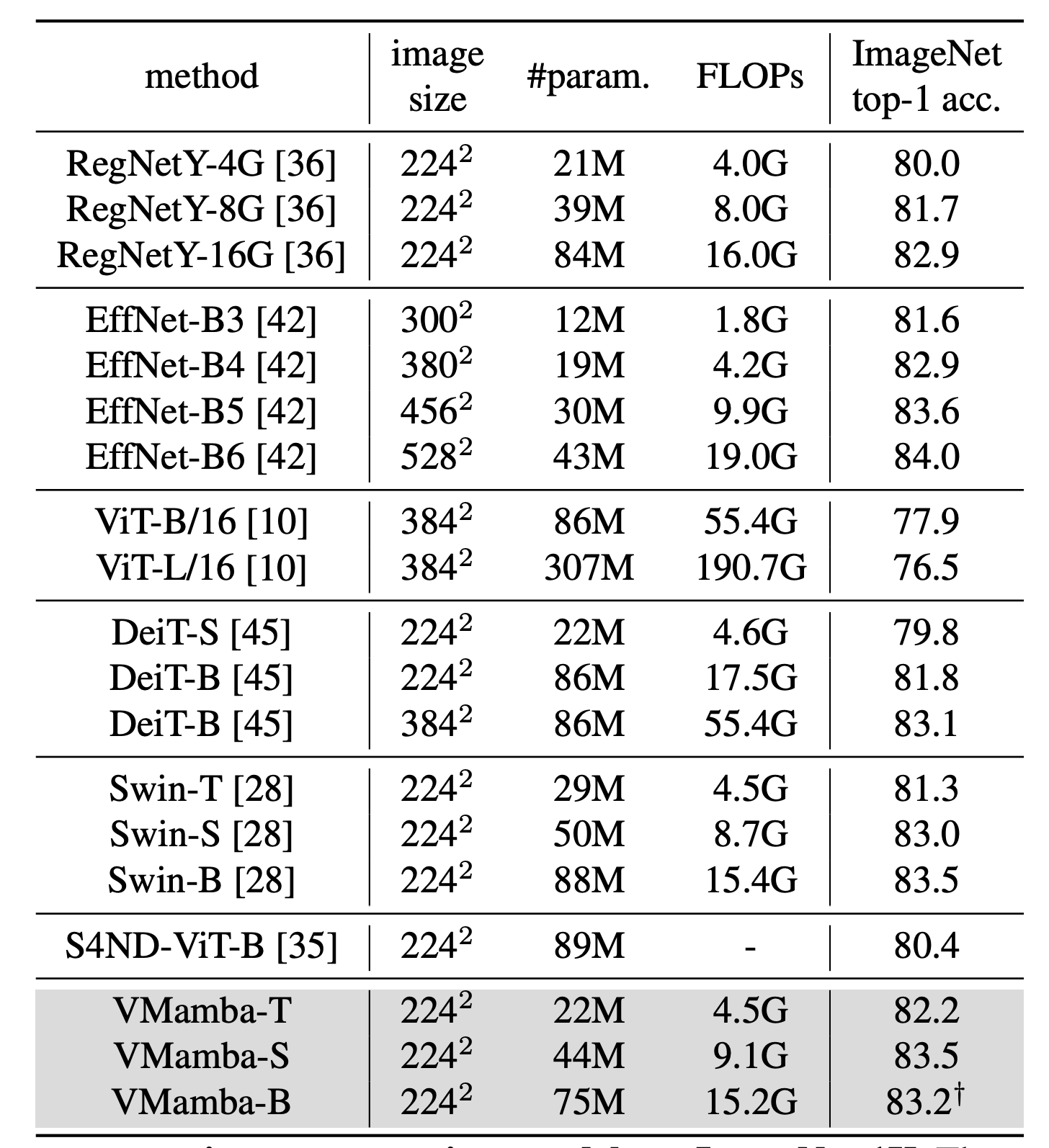
- The authors reported there is a bug in VMamba-B model
Object Detection on COCO
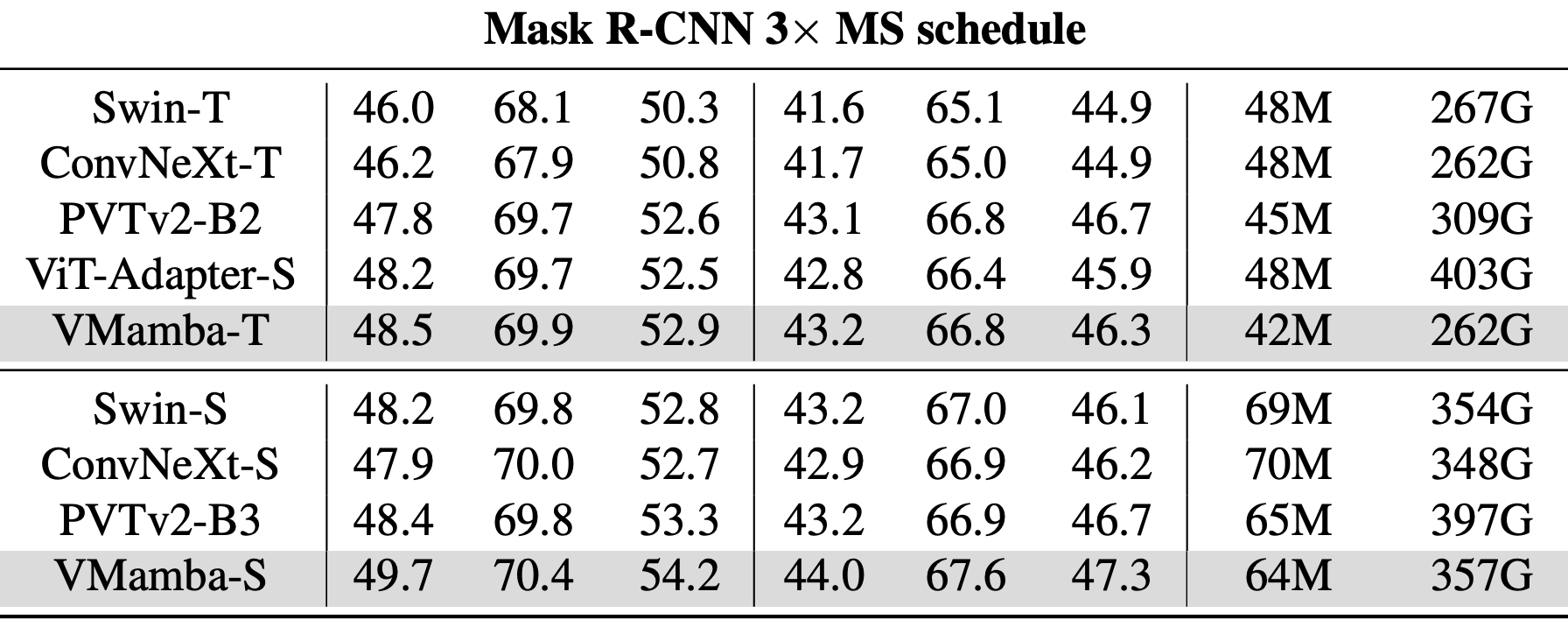
Semantic Segmentation on ADE20K
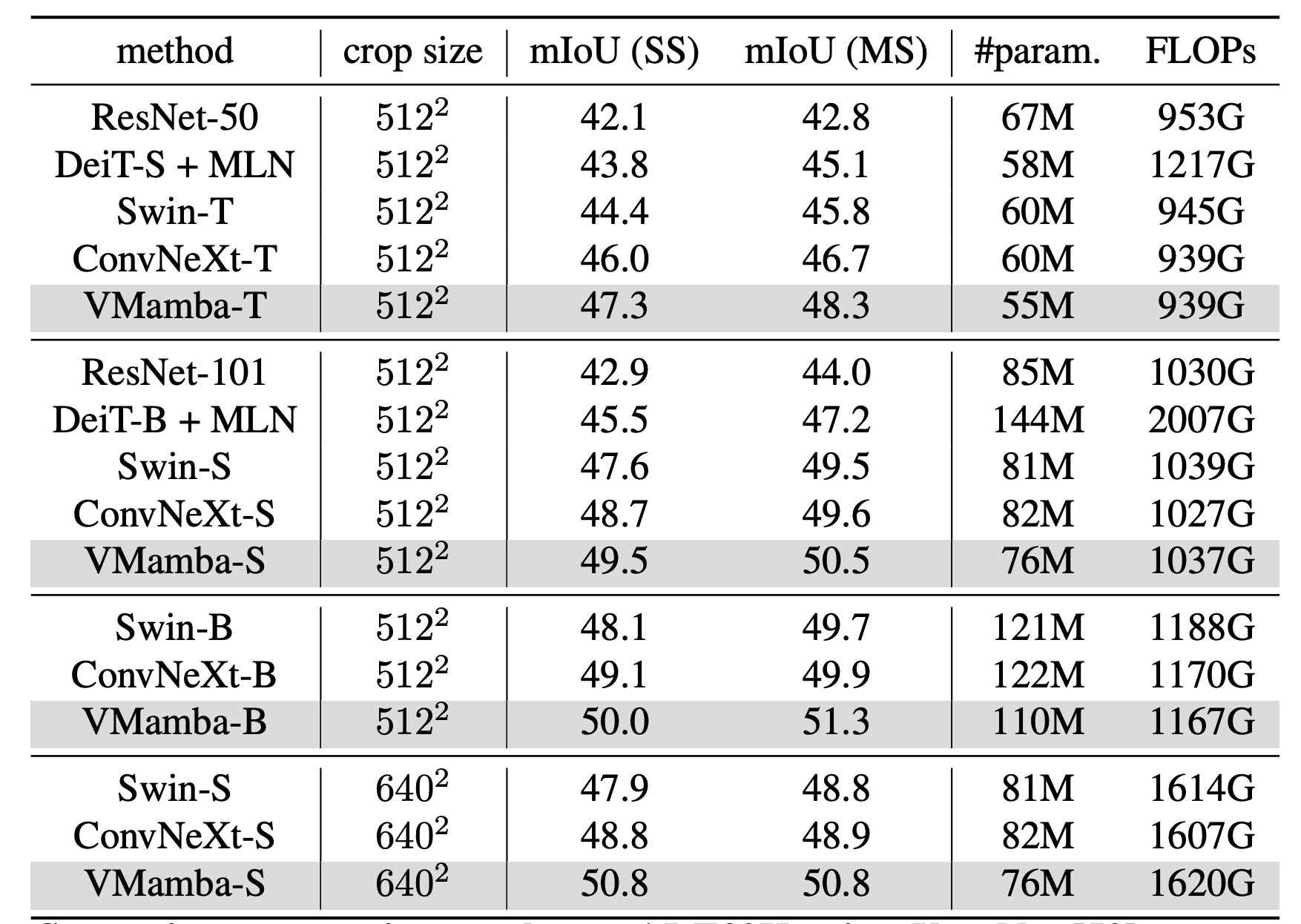
Analysis
Effective Receptive Field(ERFs)
-
measures the significance of model input concerning its output
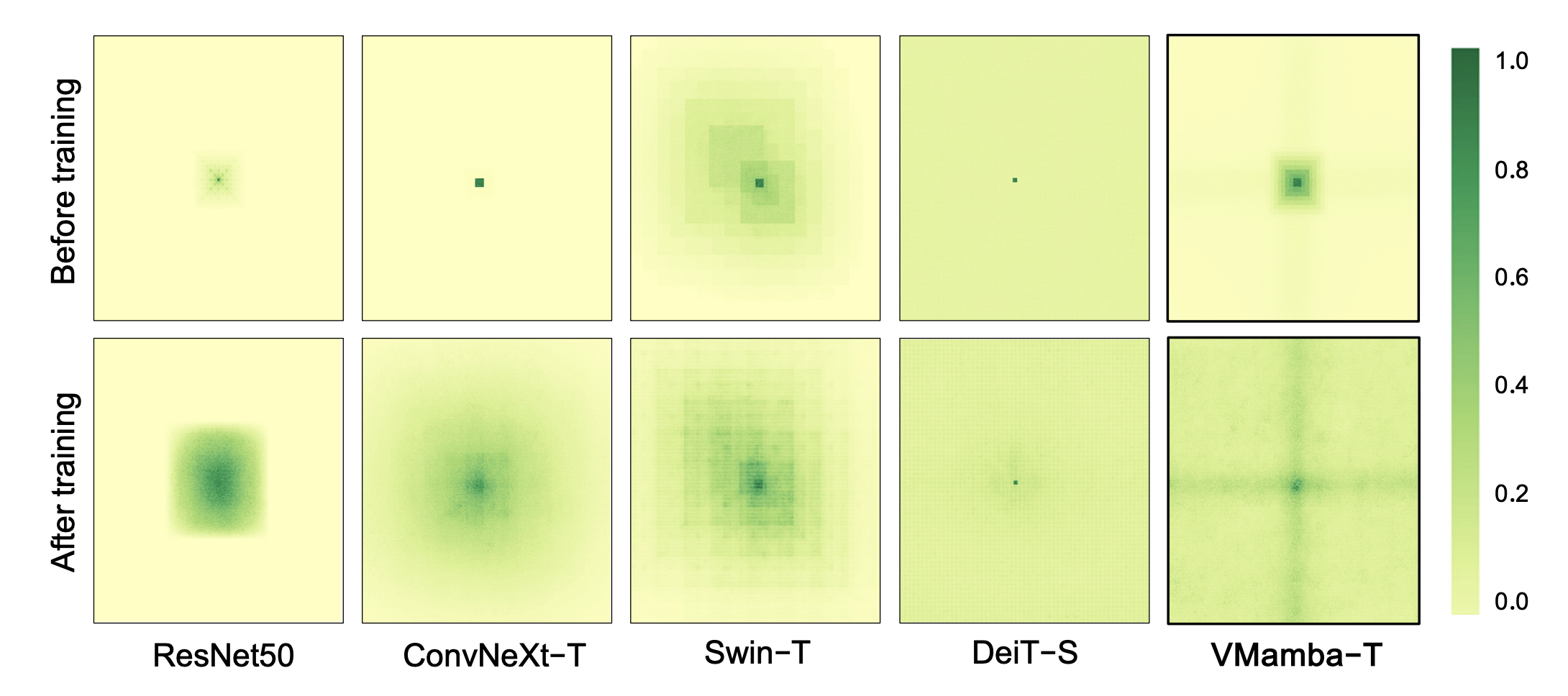
-
Only DeiT(ViT) and VMamba exhibit global ERFs
-
ViT "evenly activates all pixels using attention" vs VMamba activates all pixels and notably emphasizes cross-shaped activations(due to CSM -> central pixel is most influenced by pixels along the corss)
-
VMamba initially exhibits only a local ERF at Before Training, Training transforms the ERF to global (DeiT maintains nearly identical ERFs)
Input Scaling
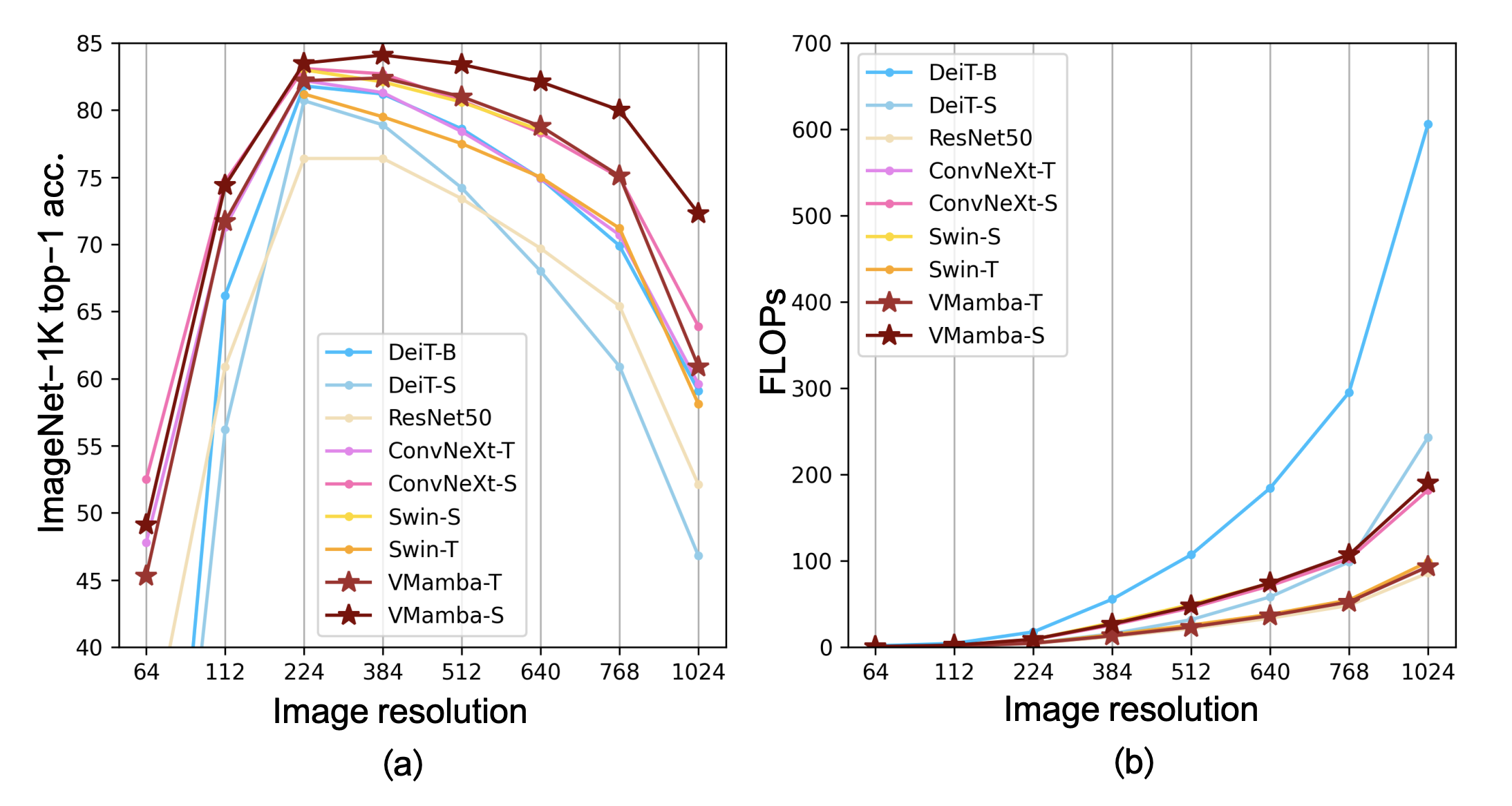
- trained with image => test classification with various image resolution
- VMamba shows most stable performance (*only upward trend in 224 -> 384)
S4ND: Modeling Images and Videos as Multidimensional Signals Using State Spaces