1. AST 제안 배경 (vs CNN)
CNNs는 spatial locality 와 translation equivariance 에서 도움이 된다고 여겨지기 때문에, end-to-end 모델링을 위한 raw spectrogram에서 표현을 학습하는 데 널리 사용되었다. long-range global context를 capture 하기 위해 최근 트렌드는 CNN 가장 위에 self-attention 메커니즘을 추가하여 CNN-attention hybrid 모델을 형성하는 것이다. CNN-attention hybrid model은 audio event classification, speech command recognition, emotion recognition와 같은 오디오 분류에서 SOTA 결과를 달성하였다. 그러나 vision 영역의 purely attention-based 모델의 성공을 보았을 때, CNN이 오디오 분류에 필수적인지 의문이 든다.
2. AST vs ViT
Vit와 AST는 유사한 architecture를 가지고 있으나 동일하지는 않다.
1. ViT의 input은 3-channel image 반면 AST의 input은 single-channel spectrogram이며 ViT patch embedding layer의 input channel 각각에 해당하는 weight을 평균하여 AST patch embedding layer의 weight으로 사용한다.
2. ViT의 input 모양은 고정되어 있으나(224x224 or 384x384) 이는 일반적인 audio spectrogram와 다르다. audio spectrogram의 길이는 가변적이다. Transfrormer은 input 길이를 지원하고 ViT에서 AST로 직접 transfer할 수 있으나 postional embedding은 ImageNet train 중 공간 정보를 encode하기 때문에 신중하게 처리해야 한다. 따라서 positional embedding adaption을 위해 cut and bi-linear interpolate 방법을 제안한다.
3. ViT의 마지막 분류 layer을 버리고 AST를 위한 새로운 분류 layer으로 다시 초기화한다. 이 adaption framework를 통해 AST는 초기화를 위해 pretrain된 다양한 ViT weights를 사용할 수 있다. 이때, 저자는 pretrained weights of a data-efficient image Transformer (DeiT)를 사용한다.
3. AST 특징
- ImageNet pretraining으로 인한 성능 향상은 데이터 규모가 작을수록 뛰어나다.
- DeiT model with distillation의 weights를 사용한 AST가 ImageNet2012와 AudioSet에 가장 뛰어난 성능을 보인다. (ViT model weights 재사용)
- 공간 지식 전달의 중요성 (ViT → AST 공간 지식 전달할 때 positional embedding adaptation을 위해 cut and bi-linear interpolation approach를 사용한다)
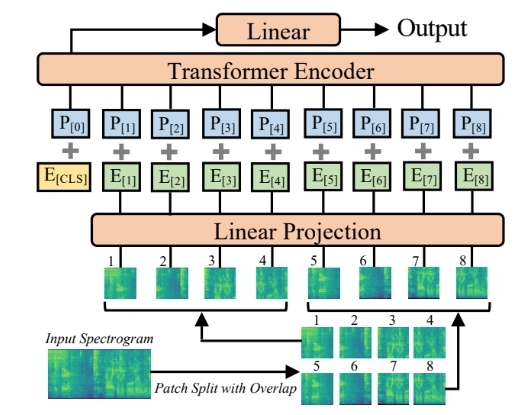
- overlap 크기가 증가하면 성능이 향상된다. (patch split overlap이 없더라도 AST는 여전히 이전 최고 시스템을 능가한다. )
- 128x2 직사각형 patch를 사용하는 것이 16x16 정사각형 patch를 사용하여 모델을 train하는 것보다 성능이 좋다. 또한 크기가 작은 patch의 성능이 더 좋다.
4. 실험 결과
- ESC-50
ImageNet와 AudioSet pretrain이 모두 있는 AST-P 가 가장 높은 성능을 보인다.
- Speech Commands
AST-S(ImageNet)가 AST-P(ImageNet와 AudioSet pretrain이 모두)보다 성능이 뛰어나기 때문에, Speech Commands V2에서는 AudioSet pretrain이 불필요하다는 것을 알 수 있다.
5. 결론
input audio 길이는 1초(Speech Commands), 5초(ESC-50), 10초(AudioSet)까지 다양하고 콘텐츠는 음성(Speech Commands)부터 비음성(AudioSet 및 ESC-50)까지 다양하지만, 저자는 고정된 AST architecture을 사용하였으며 모든 것들이 SOTA 결과를 달성한다. 이는 AST가 generic audio classifier로 사용될 가능성이 있음을 나타낸다.
