1. Introduction
image vs audio
audio는 image 보다 데이터가 불충분함
image는 보통 2차원인 반면 audio의 원시 파형은 1차원임
image는 순서에 대한 제약이 덜 하지만 audio는 chronological order
2. Methods
2-1. Problem Categorization
오디오의 시계열인 인풋으로부터 예측될 수 있는 타겟의 종류에 따라 태스크를 분류한다. 이 분류는 예측되어야 하는 label의 수와 각 label의 종류를 따른다 . 타겟은 단일 global label, 각 time step 별 local label, 인풋 길이의 함수가 아닌 자유로운 길이의(free-length) sequence label 중 하나이다. 또한, 각 label은 단일 class, class의 집합, 숫자 값 중 하나이다. 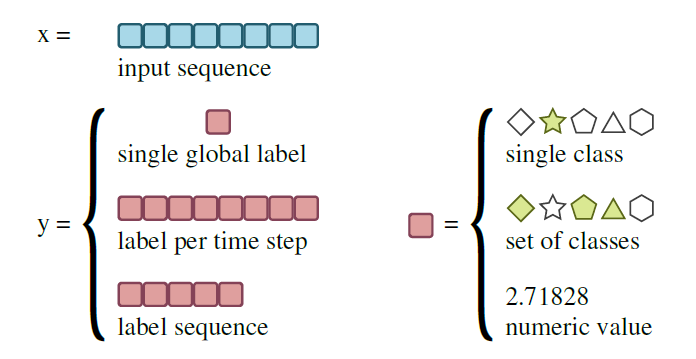
Sequence Classification
Sequence Classfication은 단일 global class label을 예측하는 것이다. 이러한 class label은 사전에 정의된 possible class의 집합에서 가져온 예측된 언어, 화자, 음정, 음향 환경일 수 있다.
Multi-label Sequence Classification
Multi-label Sequence Classfication의 타겟은 possible class의 부분 집합이다. 타겟은 약하게 label이 지정된 AudioSet 데이터셋과 같이 여러 음향 이벤트 구성이거나 음악 피치의 집합일 수 있다. class 간 상호 의존성이 있는 경우 Multi-label 분류는 효율적이다 .
Sequence Regression
Sequence Regression의 타겟은 연속된 범위의 값이다. 음악 템포 추정 혹은 다음 오디오 샘플 예측이 다음의 예시이다. 다만 회귀 문제는 언제든 이산화될 수 있고 분류 문제로 변환될 수 있기 때문에 주의해야 한다. (예로 오디오 샘플이 8비트로 양자화된 경우 샘플 예측은 256()개의 class를 가진 분류 문제로 표현된다.)
Sequence Labeling
time step 별로 label을 예측할 때 각 time step은 일정한 수의 오디오 샘플을 포함할 수 있으므로 타겟 시퀀스 길이는 인풋 시퀀스 길이의 일부(fraction)이다. time step별 분류는 Sequence Labeling으로 여겨진다. Chord annotation(코드 표기)와 보컬 활동 탐지 등이 포함된다. time step별 회귀는 연속적인 예측을 생성하며, 그 예로 음성의 피치, 소스 분리 등이 있다.
Event Detection
Event Detection은 화자 변경 혹은 음의 시작과 같은 이벤트 발생 시간 예측을 목표로 한다. 이는 각 단계에서 이벤트 존재의 유무로 이진 Sequence Labeling 태스크로 정의될 수도 있다.
Sequence Transduction
Sequence Transduction에서 타겟 시퀀스의 길이는 인풋 길이의 함수가 아니다. 음성 인식, 음악 전사, 언어 번역 등이 있다.
오디오 신호에서 시작하지 않는 태스크
오디오 합성은 조건 변수의 시퀀스에서 오디오 샘플을 예측하는 Sequence Transduction 또는 Regression이 될 수 있다. 오디오 유사성 평가는 길이가 다른 한 쌍의 오디오 신호에 연속적인 값을 할당하는 회귀 문제이다.
2-2. Audio Features
Deep Neural Networks(DNNs)
Deep Neural Networks(DNNs)는 피처 추출을 분류와 같은 최적화와 함께 수행한다. 예를 들어, 음성 인식에서는 DNN의 하위 레이어의 활성화를 화자 적응된(speaker-adapted) 피처로 간주하며 상위 레이어의 활성화는 class 기반의 구별로 간주된다.
Mel Frequency Cepstral Coefficients(MFCCs)
Mel Frequency Cepstral Coefficients(MFCCs)는 오디오 분석을 위한 주요 음향 피처 표현으로 사용되어 왔다. 이는 magnitude 스펙트라를 감소된 주파수 대역 집합으로 투영한 것으로, 로그 스케일로 변환되며 대략적으로 희게 하고(whitened??) Deiscrete Cosine Transform(DCT)로 압축한다. 그러나 DTC는 정보를 제거하고 공간 관계를 파괴하기 때문에 딥러닝 모델들은 필요하지 않거나 원하지 않는다. 이를 생략하면 오디오 도메인에서 널리 사용되는 log-mel 스펙트럼이 생성된다.
- DCT와 MFCC의 추가적인 이해
-
DCT
DCT는 코사인 함수의 합으로 표현을 변환함
공간 영역에서 주파수 영역으로 압축 → 높은 주파수(AC)보다 낮은 주파수(DC)에 정보(에너지)들이 몰리게 됨 = 앞쪽(low) 코사인 함수의 계수가 변환 전 데이터의 대부분을 갖고 있고 뒤쪽으로 갈수록 0에 근사해 결론적으론 데이터 압축의 효과를 보임
-
MFCC
MFCC는 앞에서 언급한 계수(cepstrum coefficient) 중 주파수가 낮은, 정보와 에너지가 몰려있는 12개의 계수(cepstrum coefficient)와 그들의 에너지의 합을 포함해 총 13개를 피처로 사용함. MFCC 13개의 값의 각 프레임 간 차이를 Deltas(1차 차분)하고 그 Deltas 값의 프레임 간 값 차이를 Delta-deltas(2차 차분)해서 총 39개의 MFCC 피처를 최종적으로 사용함. (=MFCC는 39차원 벡터, 그렇지만 차원이 고정되어 있지는 않음)
*delta를 사용하는 이유? 음성 신호는 time-variant, 따라서 프레임 단위로 보면 정보를 충분히 반영하지 못할 수 있음. 이를 보완하고자 각 프레임 간의 차이를 구해 time-varian한 특징을 반영하고자 피처로 사용함.
MFCC는 스펙트럼을 정량화하여 반영함과 동시에 중요하지 않은(정보가 많지 않은) 스펙트럼을 제거해 유용하게 쓰일 수 있다. 그러나 노이즈에 robust하지 않다.
-
mel filter bank
mel filter bank는 주파수를 투영하기 위해 인간의 청각 체계와 언어 지각에 대한 생리학적 연구에서 영감을 얻었다. 어떤 태스크에서는 이동(transposition)을 번역(translation)으로 포착하는 표현을 사용하는 것이 좋다. 톤을 이동시키는 것은 기본 주파수와 고음파를 공통 요소로 스케일링하는 것으로, 로그 주파수 스케일에서 이동이다. costant-Q 스펙트럼은 적절한 filter bank로 이러한 주파수 스케일을 달성한다.
고조음(harmonics)
음향 생성의 물리학적 특성으로 인해 동일한 기본 주파수의 배수인 주파수(고조음)에 대한 추가적인 상관 관계가 있다. CNN과 같은 local 모델이 이러한 상관 관계를 반영하려면 직접 고조음 시리즈의 magnitude를 제공하는 세 번째 차원을 추가할 수 있다. 또한 이미지와 달리 값 분포가 주파수 대역에서 다르기 때문에 스펙트로그램을 각 대역별로 표준화할 수 있다.
스펙트럼을 계산하기 위한 창 크기는 시간 해상도(짧은 창)와 주파수 해상도(긴 창) 사이의 교환을 나타낸다. log-mel, constant-Q 스펙트로그램 모두 높은 주파수에 대해 더 짧은 창을 사용하는 것이 가능하지만, 이는 지역 모델에 적합하지 않은 흐린(blurred) 스펙트로그램을 초래한다. 다른 방법으로는 서로 다른 창 길이로 스펙트럼을 계산하고 동일한 주파수 대역으로 투영하여 별도의 채널로 처리하는 것이 있다.
그 외의 방법
피처 추출 과정을 단순화하고 데이터 기반 통계 모델 학습에 위임하기 위해, mel 간격의 삼각형 필터 대신 데이터 기반(data-driven) 필터를 사용하는 여러 방법이 제안되었다.
1) 전체 해상도의 magnitude 스펙트럼을 사용한다.
2) 오디오 신호의 원시 파형 표현을 직접 인풋으로 사용하며, 데이터 기반 필터를 타겟 태스크의 남은 네트워크와 함께 학습한다. 이 방식으로 학습된 필터는 직접적으로 최적화된다.
3) 모델의 하위 레이어가 log-mel 스펙트럼 계산을 모방하도록 설계되었지만 모든 필터 파라미터는 데이터에서 학습된다.
4) 필터 뱅크의 개념을 버리고 어떠한 사전 지식 없이 시간 도메인의 파형 샘플의 요인 회귀(causal regression) 모델을 학습한다.
2-3. Models
2-3-1. Convolutional Neural Networks(CNNs)
CNNs는 인풋과 학습 가능한 커널의 컨볼루션(합성곱)을 기반으로 한다.
스펙트럼 인풋 : 1차원 시간 컨볼루션 or 2차원 시간-주파수 컨볼루션
원시 파형 인풋 : 1차원 시간 컨볼루션 적용
convolution layer : 각각의 커널로부터 여러 피처 맵(채널)을 계산
pooling layer : convolution layer 위에 추가되며, 학습된 피쳐 맵을 down sample 함
CNN은 convolution layer과 pooling layer이 번갈아가며 나열된 후 하나 이상의 dense layer이 뒤따르는 구조이다. CNN의 수용 영역(예측에 사용되는 샘플 또는 스펙트라의 수)은 아키텍처에 의해 고정된다. 더 큰 커널을 사용하거나 많은 층을 쌓음으로써 이를 증가시킬 수 있다.
높은 sample rate을 가진 원시 파형 인풋의 경우, 충분한 수용 영역 크기에 도달하기 위해 CNN의 파라미터 수가 많아지고 계산 복잡도가 높아진다. 이를 해결하기 위해 확장된 컨볼루션을 사용할 수 있다. 확장된 컨볼루션이 쌓이면 적은 수의 layer으로도 매우 큰 수용 영역을 얻을 수 있으며 입력 해상도와 계산 효율성을 보존할 수 있다.
현재 CNN의 아키텍처는 대부분 실험을 통한 validation error를 기반으로 선택되며 몇몇 가이드라인을 도출했다. 예를 들면 데이터가 적을수록 더 적은 파라미터를 사용하는 것, 연속적인 convolution layer에서 피처 맵 크기를 줄이면서 채널 수를 늘리는 것, 시간적 context의 필요한 크기를 고려하는 것, 태스와 연관된 설계(예로 분석/합성/변환) 등이 있다.
2-3-2. Recurrent Neural Networks(RNNs)
CNN 모델링 시 context 크기의 제약을 극복하고자 다른 접근 방식을 사용하는 RNN을 제안한다.
RNNs은 해당 단계의 인풋과 숨겨진 상태인 이전 단계 모두에서 아웃풋을 계산한다. 이는 인풋의 시간 종속성을 모델링하며 수용 영역을 과거로 무한 확장할 수 있게 한다. all-to-all 커널을 사용한 RNNs에서 숨겨진 유닛 수가 선형으로 증가하고, 표현 가능한 상태 수는 기하급수적으로 증가하는 반면 훈련 or 추론 시간은 최대로 제곱만큼 증가한다. RNNs는 훈련 중에 기울기 소실/폭주 문제를 겪을 수 있다. 이를 해결하기 위해 다양한 변형이 개발되었다.
다양한 변형
LSTM(Long Short-Term Memory) 은 gating 메커니즘과 메모리 셀을 사용하여 정보 흐름을 완화하고 기울기 문제를 완화한다. LSTMs는 시간 및 주파수 도메인에서 오디오 신호를 모델링하는 데 확장되었다. Frequency LSTMs(F-LSTM) 및 Time-Frequency LSTMs(TF-LSTM)는 주파수 상의 상관 관계를 모델링하기 위한 CNN의 대안으로 소개되었다. CNN과는 달리 F-LSTMs는 지역 필터와 순환 연결을 통해 translational 불변성을 포획한다. 이들은 pooling 작업이 요구되지 않으며 다양한 종류의 인풋 피처가 적용될 수 있다. TF-LSTMs는 시간 및 주파수에 걸쳐 펼쳐지며, 지역 필터와 순환 연결을 통해 스펙트럼 및 시간적 변화를 모델링하는 데 사용될 수 있다. TF-LSTMs는 특정 태스크에서는 CNN보다 우수한 성능을 보이지만 병렬화하기 어려워 느리다. RNN은 CNN의 아웃풋을 처리하는 Convolutional Recurrent Neural Network (CRNN)도 방법이다. 이는 convolution layer으로 지역 정보를 추출하고 recurrent layer으로 더 긴 시간 context를 결합한다.
2-3-3. Sequence-to-Sequence Models
오디오 처리는 대부분 본질적으로 sequence to sequence 변환 작업이다. Sequence-to-Sequence 모델은 인풋 시퀀스를 직접 아웃풋 시퀀스로 변환한다.
음성 인식을 예로 들면, 궁극적인 태스크는 인풋 시간 오디오 신호를 단어 시퀀스로 변환하는 것이다. 그러나 전통적인 ASR 시스템은 음향, 발음 및 언어 모델링 구성 요소가 별도로 훈련되어 구성된다. Sequence to Sequence 모델은 fully 신경망 기반으로, 유한 상태 변환기, 사전, 또는 텍스트 정규화 모듈을 사용하지 않는다. 음향, 발음 및 언어 모델링 구성 요소는 단일 시스템에서 훈련된다. 따라서 이는 전통적인 시스템에 비해 훈련을 크게 단순화시킨다. 이는 별도의 시스템에서 생성된 의사 결정 트리 또는 시간 정렬을 bootstrap할 필요가 없다. 또한 모델이 직접 대상 시퀀스를 예측하도록 훈련되기 때문에 디코딩 과정도 간소화된다.
다양한 모델
CTC(connectionist temporal classification)는 아웃풋 시퀀스의 길이와 인풋 시퀀스를 매치하기 위해 비어 있는(blank) 심볼을 도입하고, 아웃풋 시퀀스를 최적화하는 모든 가능한 방법(insert blank)을 통합한다. 기본 CTC 모델은 확장되어 Recurrent Neural Network Transducer(RNNT)를 포함한다. 또한 인풋 및 아웃풋 시퀀스 간의 정렬을 학습하는 attention 기반 모델이 유명해졌다. 다양한 sequence to sequence 모델 중에서는 listen, attend and spell(LAS)가 다른 모델에 비해 개선된 결과를 제공한다.
2-3-4. Generative Adversarial Networks(GANs)
GANs 저차원의 랜덤 잠재 벡터에서 주어진 데이터셋으로부터 현실적인 샘플을 생성하는 방법을 학습하는 비지도 생성 모델이다. GAN은 생성자(generator)와 식별자(discriminator) 두 개의 네트워크로 구성된다. 생성자는 알려진 샘플에서 추출한 잠재 벡터를 매핑하고, 식별자는 주어진 샘플이 실제인지 가짜인지를 결정한다. 두 모델은 적대적인 프레임워크에서 서로 경쟁한다. GAN은 소스 분리, 음악 악기 변환, 음성 개선(노이즈 제거)에 사용된다.
2-3-5. Loss Functions
딥러닝 시스템 설계에서 중요하고 창의적인 부분 중 하나는 손실 함수의 선택이다. 손실 함수는 훈련에 경사 하강법이 사용될 때 시스템의 훈련 가능한 파라미터에 대해 미분 가능해야 한다.
log-mel 스펙트라 간의 평균 제곱 오차(MSE)는 두 오디오 프레임 간의 차이를 측정하는 데 사용된다. 시간 구조를 고려하기 위해 log-mel 스펙트로그램을 이용하지만 시간 도메인의 샘플 간의 MSE를 비교하는 것은 견고한 측정이 아니다. 예를 들어, 동일한 주파수를 가진 두 사인파 신호의 경우, 손실은 그들의 위상 차이에 의존한다. 비선형으로 약하게 왜곡된 신호도 유사하게 들리는 사실을 고려하기 위해서는 미분 가능한 동적 시간 정렬 거리나 Wasserstein GANs의 지구 이동자 거리를 사용하는 것이 적절하다.
손실 함수는 특정 응용 프로그램에 맞게 설계된다. 예를 들어, 소스 분리에서는 심리음향학적 음성 인지 실험을 기반으로 한 목적 미분 가능 손실 함수를 설계한다. 다양한 손실 함수를 결합할 수도 있다. 통제된 오디오 합성에서는 하나의 손실 함수가 Variational autoencoder(VAE)의 잠재 변수가 정의된 범위 내에 남도록 하고, 다른 손실 함수는 제어 공간의 변화가 생성된 오디오에 반영되도록 한다.
2-3-6. Phase modeling
1) 위상은 Griffin-Lim 알고리즘을 사용하여 magnitude 스펙트럼에서 추정될 수 있다. 그러나 추정된 위상의 정확도는 소스 분리, 오디오 향상, 오디오 생성에서 원하는 고음질 오디오를 얻기에 충분하지 않다.
2) WaveNet과 같은 신경망을 훈련하여 log-mel 스펙트럼에서 시간 도메인 신호를 생성할 수 있다.
3) 딥러닝 아키텍처는 magnitude와 위상 스펙트럼을 모두 인풋 피처로 포함하거나 complex 타겟을 사용함으로써 complex 스펙트럼을 직접 처리하도록 훈련된다.
4) DNN의 모든 작업 (convolution, pooling, 활성화 함수)이 complx 도메인으로 확장될 수 있다.
위상 불변성
원시 파형을 인풋으로 사용할 때, 인지적으로나 의미적으로 동일한 소리가 서로 다른 위상 변화로 나타날 수 있으므로 작은 위상 변화에 불변한 표현을 사용하는 것이 중요하다. 위상 불변성을 달성하기 위해 일반적으로 시간에서 pooling하는 convolution layer 또는 overcomplete한 hidden 유닛을 가진 DNN layer를 사용한다. 이러한 layer는 다양한 위상에서 동일한 filter 모양을 캡처할 수 있다. 주로 합성에서 사용되며 자기 회귀(autoregressive) 모델이 대표적인 예시이다.
2-4. Data
전이 학습(transfer learning)
딥러닝은 대규모 훈련 데이터셋에서 가장 잘 적용된다. 그러나 음성, 음악 및 환경 소리를 포함한 도메인 간에 공유될 수 있는 label된 데이터셋은 없다. label된 데이터의 제한을 극복하고자 이미지 처리에서 제안된 방법인 전이 학습은 label된 대량의 유사한 데이터를 사용하여 학습한 후 그 지식을 타겟 도메인에 적용시키는 것이다. 예로, 음성 인식에서는 전사된 데이터가 많은 언어에서 사전 훈련한 후 낮은 리소스 언어 또는 도메인에 적용시키는 방법으로 전이 학습을 활용한다.
데이터 생성
실제 데이터와 유사한 데이터를 알려진 합성 파라미터와 label을 사용하여 생성할 수 있다. 생성된 데이터의 복잡도를 점차 증가시킴으로써 기계 학습 방법을 이해하고 디버깅하며 개선하는 것이 수월해진다. 그러나 생성된 데이터만을 사용하면 실제 데이터에서의 성능은 떨어질 수 있다.
데이터 증강
데이터 증강은 기존의 예시를 조작하여 가능한 인풋 범위를 확장함으로써 추가적인 훈련 데이터를 생성힌다. ASR에서는 피치 이동(pitch shift)와 시간 늘이기(time stretch)로 화자 변환을 할 수 있다. 피치 이동은 코드 인식(chord recognition)에 유용하게 사용되었고, 시간 늘이기와 스펙트럼 필터링과 결합하여 보컬 목소리 탐지 및 악기 인식에도 사용된다. 환경 소리의 경우 훈련 예시와 그 label을 선형으로 결합하면 일반화가 향상된다. 소스 분리에서는 분리된 트랙을 섞어 합성된 데이터셋을 사용하여 성공적인 훈련이 가능하다.
2-5. Evaluation
음성 인식
음성 인식에서 주로 사용되는 평가 지표는 WER(Word Error Rate)이다. WER은 문자열을 정렬한 후 단어 오류 비율을 계산하는 것이다.
음악 및 음향 장면 분류
음악 및 음향 장면 분류에서 일반적으로 사용되는 지표는 정확도(accuracy), AUROC(Area Under the Receiver Operating Characteristic Curve)이다.
Event Detection
EER(Equal Error Rate), F-score를 사용하여 성능을 측정한다.
소스 분리
Singal-to-Distortion-Ratio, Singal-to-Interference-Ratio, Singal-to-Artifacts-Ratio를 주로 사용한다.
합성
합성된 오디오의 품질을 평가하기 위한 주관적인 평가로 MOS(Mean Opinion Score)가 사용된다.
3. Applications
3-1. Analysis
3-1-1. Speech
음성 인식 모델 연대기
- 1990
수십 년 동안 음성 모델링에는 GMM(Gaussian Mixture Model), HMM(Hidden Markov Model)이 사용되었다. 이러한 모델은 화자나 태스크 적응과 같은 실제 문제에 대한 다양한 원칙적인 해결책을 제공했다.
- 1990
- 1990 1990년경에는 최대 우도를 사용하여 훈련된 모델보다 변별적 훈련이 성능이 더 우수하다는 사실이 발견되었다. GMM을 대체하기 위해 신경망 기반 하이브리드 모델이 제안되었다.
- 2012 - 2012년, 수천 시간의 데이터로 훈련된 수백만 개의 파라미터를 갖는 DNN이 다양한 음성 인식 태스크에서 WER을 현저하게 감소시켰다. 깊은 feedforward 및 convolution network의 큰 성공에 더해, LSTM 및 GRU가 feedforward DNN보다 우수한 성능을 발휘하는 것이 입증되었다. 이후에는 convolution + LSTM + DNN인 CLDNN 모델이 LSTM만을 사용하는 모델보다 우수한 성능을 보였다.
- CLDNN CLDNN에서는 인풋 프레임의 창이 먼저 두 개의 convolution layer와 최대 pooling layer로 처리되어 신호의 주파수 변동을 감소시킨 후, 다음 LSTM layer에서 시간 상관 관계를 모델링하기 위해 저차원의 피처 공간으로 투영되며, 마지막으로 몇 개의 feedforward layer와 아웃풋 softmax layer을 통과한다.
- CLDNN CLDNN에서는 인풋 프레임의 창이 먼저 두 개의 convolution layer와 최대 pooling layer로 처리되어 신호의 주파수 변동을 감소시킨 후, 다음 LSTM layer에서 시간 상관 관계를 모델링하기 위해 저차원의 피처 공간으로 투영되며, 마지막으로 몇 개의 feedforward layer와 아웃풋 softmax layer을 통과한다.
- 현재 RNN을 음성 모델링에 도입함으로써 연구 분야는 purely 신경만 기반 sequence to sequence 모델인 CTC, LAS가 관심을 받았다.
- CTC 기반 모델로 단어 아웃풋 타겟으로 훈련시킨 것은 YouTube 비디오 자막 작업에서 SOTA CD-phoneme 베이스라인을 능가했다.
- LAS(Listen, attend, and spell) 모델은 인코더, 정렬 모델로 작용하는 attention 모듈, 디코더를 포함하는 단일 신경망이다.
음성 인식의 적용
Google Home, Amazon Alexa, Microsoft Cortana와 같은 가상 비서는 음성을 주요 상호 작용 방식으로 채택한다. 음성 전사(speech transcription)는 YouTube 음성 자막과 같은 다양한 응용 프로그램에서 멀티미디어에서 정보를 검색하는 데 사용된다. ASR에서의 딥러닝 모델의 성공으로 음성 활동 감지, 화자 인식, 언어 인식, 음성 번역과 같은 다른 딥러닝 음성 관련 작업도 포용하고 있다.
3-1-2. Music
음악 녹음은 일반적으로 더 다양한 소리 소스를 포함하고 있다. 많은 종류의 음악에서 그들의 발생은 시간 및 주파수에 관한 제약을 따르며, 소스 간에 복잡한 종속성을 만든다. 이러한 과정에서 다양한 작업이 있다 : low-level 분석 (onset, offset 감지, 기본 주파수 추정), 리듬 분석 (비트 추적, meter 식별, 다운비트 추적, 템포 추정), harmonic 분석 (key 감지, 멜로디 추출, 코드 추정), high-level 분석 (악기 감지, 악기 분리, 전사, 구조적 분할, 아티스트 인식, 장르 분류, 분위기 분류), high-level 비교 (반복된 테마 발견, 커버 곡 식별, 음악 유사성 추정, 악보 정렬)
Event Detection
다양한 작업들이 이진 이벤트 감지 문제로 정의된다. 가장 low-level의 작업 중 하나는 노트의 시작 지점을 추가적인 분류 없이 예측하는 *onset 감지*이다. 2006년 Constant-Q 로그 magnitude 스펙트로그램의 200ms 조각에 대해 작은 MLP를 훈련시켜 중앙이나 근처에 onset이 있는지 예측했다. 이 방법을 개선하기 위해 다양한 연구가 진행됐다 : 시간 차이 필터를 사용하여 처리된 스펙트로그램에 양방향 LSTM을 적용, 동일한 데이터셋의 15프레임 log-mel 음성을 처리하는 CNN을 사용. onset 감지는 비트와 다운비트 추적의 기반을 형성하는 데 사용한다. 최근 연구에선 CNN 또는 RNN으로 훈련하여 직접적으로 비트와 다운비트를 추적한다. 두 연구 모두 장기 일관성을 보장하기 위한 시간 모델의 추가적인 후처리에 의존한다. 후처리를 필요로하지 않지만 비트 tracker에 의존하는 CRNN이 제안되기도 했다.
high level의 이벤트 감지 작업은 음악 segment 간의 경계를 예측하는 것이다. 이를 CNN으로 해결하였으며 강력하게 다운샘플링된 스펙트로그램에 최대 60초의 수용 필드를 사용했다. 다양한 방법을 비교할 때 고정 크기의 시간 context를 갖는 CNN과 잠재적으로 무한한 context를 갖는 RNN 모두 이벤트 감지에 성공적으로 사용된다.
multi class sequence labeling
multi class sequence labeling의 대표적인 예시는 코드 인식이다. 코드 인식은 서양 음악 녹음의 각 시간 단계에 root note와 코드 class를 할당하는 작업이다. 전형적인 수동 설계 방법은 스펙트럼 표현의 여러 옥타브를 12개의 semitone chromagram으로 fold 하며, 시간에 따라 평활화하고 사전 정의된 코드와 일치시키는 것이다. 현대 시스템은 시간 모델링을 통합하며 구별 가능한 코드의 집합을 확장한다. 최근에는 CRNN을 적용하고 side 타겟을 사용하여 170개 코드 class의 상세 집합 간 관계를 포함한다. 다른 방법으로는 코드를 예측하는 데 CNN을 훈련시키고 코드 추정 이상의 작업에 유용한 개선된 크로마그램 표현을 도출한다.
Sequence classification
sequence classification에 포함되는 low-level 작업은 곡의 global 템포 추정이다. 일반적인 해결책은 비트 및 다운비트 추적을 기반으로 하는 것이다. 다운비트 추적은 주로 템포 추정을 통합하여 다운비트 위치를 제한하는 데 사용된다. 그러나 비트 추적을 할 때 onset 검출 없이 수행될 수 있듯이 CNN을 훈련시켜 12초 스펙트로그램 단편에서 직접 템포를 추정할 수 있음을 보였다. 이를 통해 더 나은 결과를 얻을 수 있으며 녹음 내에서의 템포 변경이나 drift에 대처할 수 있게 된다.
더 넓은 작업으로는 태그 예측이 있다. 이는 한 곡에 제한된 단어의 label을 예측하는 것이 목표이다. 태그는 악기, 템포, 장르 등과 관련될 수 있지만 항상 전체 녹음에 적용되며 타이밍 정보가 없다. 인풋 시퀀스에서 global label의 간극을 줄이기 위해 다양한 방식이 제안됐다.
3-1-3. Enviromental Sounds
음향 장면 분류
다항 분류 문제로 간주되며, 전체 오디오 녹음에 단일 장면에 label 지정하는 것이 목표이다. 가능한 장면 레이블에는 예를 들어 "집", "거리", "자동차 안", "음식점" 등이 있다. 장면 레이블 집합은 사전에 정의되어야 한다.
음향 이벤트 감지
개별 소리 이벤트의(ex. 발자국, 신호등 음향 신호, 개 짖는 소리) 시작 및 종료 시간을 추정하고 이러한 이벤트에 label 지정하는 것이 목표이다. 가능한 이벤트 클래스 집합은 사전에 정의되어야 한다. 감지할 때 지도 분류기를 사용하여 각 이벤트 클래스의 활동을 단기간 동안 예측하는 활동인 지도 학습이 가장 효과적인 방법이다. 지도 분류기는 보통 분류되어야 하는 외부 신호로부터 계산된 음향 특징인 맥락 정보(contextual information)를 사용한다. 이를 위해 타겟 프레임 주변의 여러 context 프레임에서 음향 특징을 연결하는 것이 간단한 방법입니다.
태깅
태깅은 시간 정보 없이 여러 소리 클래스의 활동을 예측하는 것이 목표이다. 태깅과 이벤트 감지 모두 여러 이벤트 클래스를 대상으로 할 수 있어 다중 음향 이벤트 감지(polyphonic event detection)라 부르며, 이들은 동시에 활성화될 수 있다. 각 클래스의 활동은 이진 벡터, 1(활성 클래스)과 0(비활성 클래스)으로 나타난다. 클래스 간 중첩이 허용된다면 이는 다중 레이블 분류(multi-label classfication)가 된다. 이 경우 각 클래스 별로 단일 클랜스 분류기를 사용하는 것보다 다중 레이블 분류기를 사용하여 한 번에 여러 클래스의 활동을 예측하는 것이 개별 더 나은 결과를 얻을 수 있다고 밝혀졌다. 그 이유는 다중 클래스 분류기가 동시에 활동 중인 클래스들 간 상호 작용을 모델링할 수 있기 때문이다.
3-1-4. Localization and Tracking
멀티채널 오디오는 소리 소스의 공간 위치를 결정하고 시간에 따라 추적하는 것을 가능하게 한다. (cf. mono : one channel, stereo : two channel, multi-channel : 2 이상의 channel) 이는 추정된 소스 방향에서 소스를 분리하거나(source separation) 다양한 화자의 활동을 추정하는 diarization 시스템(speech enhancement)에서 사용된다.
딥러닝 기반 localization에 사용되는 인풋 피처는 위상 스펙트럼, magnitude 스펙트럼, 채널 간 일반화된 상호 상관관계 등이 있다. 일반적으로 소스 localization에는 채널 간 정보 사용이 필요하다.
3-2. Synthesis and Transformation
3-2-1. Source Separation
소스 분리는 여러 소스의 혼합물에서 개별 소스에 해당하는 신호를 추출하는 과정이다. 응용 분야는 편곡 및 음악 remixing, robust한 소리 분류를 위한 전처리, 또는 음성 명료도 향상을 위한 전처리 등이 있다.
3-2-2. Audio Enhancement
노이즈 감소를 통해 음성의 품질을 향상시키는 것이 목표이다. 전통적인 노이즈 제거 방법(ex. Wiener)은 일반적으로 정지된 잡음을 가정하지만, 딥러닝 방법은 시간에 따라 변하는 잡음을 모델링할 수 있다. 음성 향상을 위한 다양한 유형의 네트워크는 다음과 같다 : 노이즈 제거 오토인코더, convolution 네트워크, recurrent 네트워크 등. 최근에는 GANs이 부가적인 노이즈가 존재하는 환경에서 음성 향상이 잘 수행된다는 것이 연구됐다.
3-2-3. Generative Models
생성 소리 모델은 소리 데이터베이스에서 학습한 특성을 기반으로 소리를 합성하여 현실적인 소리 샘플을 생성한다.
조건
- 생성된 소리는 모델이 훈련된 소리와 유사해야 하며, 음향 특성(음색, 피치, 리듬)이 비슷해야 한다.
- 소리가 특정 객체/프로세스에서 유래되었다는 것이 인지 가능해야 한다.
- 생성된 소리는 원본이어야 하며, 훈련 셋의 소리를 단순히 복사하는 것이 아니라 훈련 셋의 소리와 현저히 달라야 한다.
- 생성된 소리는 다양성이 있어야 한다. 소리 합성을 조건부로 만드는 것이 좋다.(ex. 화자, 억양, 음악의 고조(harmonic) 또는 환경 소리 생성되는 파라미터)
- 훈련 및 생성 시간이 짧아야 한다. (이상적으로는 실시간으로 생성이 가능해야 함)
소리 합성
소리 합성은 스펙트럼 또는 원시 오디오로부터 수행된다. 스펙트럼의 경우 합성에 필요한 위상 정보가 부족하며, Griffin-Lim 알고리즘과 역 푸리에 변환이 결합되어 사용되는 경우 품질이 높지 않을 수 있다. end-to-end 합성은 블록 단위로 수행되거나 자기 회귀 모델로 수행될 수 있다. 블록 단위 접근 방식에서 VAE 또는 GANs의 경우 소리는 종종 저차원 잠재 표현에서 합성되기 때문에 높은 해상도 소리로 업샘플링해야 한다. 다양한 레이어 해상도에서 유발된 아티팩트는 다른 레이어에서 랜덤 위상 변동을 통해 개선될 수 있습다. 자기 회귀 접근 방식에서는 새로운 샘플이 이전 샘플의 무한한 context를 기반으로 순차적으로 생성된다. RNNs (ex. LSTM or GRU)을 사용하는 경우 훈련 시 연산량은 많지만 한 레이어의 활성이 더 굵은 해상도를 가진 다음 레이어의 활성에 의존하는 방식으로 소리를 처리하도록 레이어를 쌓는다. 희소 RNN을 기반으로 한 오디오 생성 모델은 긴 시퀀스를 짧은 시퀀스로 접는다. WaveNet에서 dilated convolutions를 쌓으면 합리적인 크기의 context 창이 생성된다. WaveNet 기반의 음성 합성 모델은 SOTA를 달성했으나 훈련 시 계산 비용이 많이 든다는 단점이 있다. 병렬 WaveNet은 느린 훈련 문제에 대한 해결책을 제공하여 WaveNet 모델을 다른 응용 프로그램에서 빠르게 적용할 수 있도록 한다.
평가 방법
소리가 정규화된 log-mel 스펙트럼으로 표현되기 때문에 다양성은 소리와 가장 가까운 이웃 사이의 평균 유클리드 거리로 측정된다. 원본성은 생성된 샘플과 실제 훈련 셋의 가장 가까운 이웃 사이의 평균 유클리드 거리로 측정된다. 주관적인 평가 방법은 원본과 합성된 오디오의 인지 가능한 차이가 없다는 것을 평가할 때 사용되며 예시로 MOS를 사용하는 WaveNet이 있다.
4. Discussion and Conclusion
4-1. Features
log-mel 스펙트럼
ASR, MIR, 환경 소리 인식과 같은 분석 작업에서는 log-mel 스펙트럼 더 간단한 표현을 제공한다. 이 경우 일반적으로 더 적은 데이터 및 훈련이 필요하다.
원시 파형 또는 복잡한 스펙트럼
소스 분리, 오디오 강화, TTS, 소리 변형과 같은 고음질 오디오 합성 작업에서는 log-mel 스펙트럼크을 사용하면 위상을 재구성할 수 있다. 따라서 일반적으로 원시 파형 또는 복잡한 스펙트로그램을 인풋으로 사용한다.
향후 질문들
- log-mel 스펙트로그램이 오디오 분석에 가장 적합한 표현인가?
- 어떤 상황에서 원시 파형을 사용하는 것이 더 나은가?
- 원시 파형에서 표현을 학습한다면 태스크 또는 도메인 간에 일반화가 가능한가?
4-2. Models
다양한 도메인에서 CNNs, RNNs, CRNNs이 성공적으로 활용되었다. 세 가지 모두 시간 시퀀스를 모델링할 수 있으며 시퀀스 분류, 시퀀스 라벨링, 시퀀스 변환을 할 수 있다. 따라서 어떤 설정에서 어떤 모델이 가장 우수한지는 여전히 연구되어야 한다.
4-3. Data Requirements
음성 인식을 제외한 모든 오디오 도메인은 상대적으로 작은 데이터셋을 갖는다. 따라서 이러한 데이터셋에서 훈련된 딥러닝 모델의 크기와 복잡성에 제한이 있다. 또한 오디오 도메인은 유사한 작업 및 데이터셋에서 사전 훈련된 모델이 없다.
향후 질문
- 음성, 음악 및 환경 소리를 포함하는 오디오 데이터셋이 전이 학습을 통해 여러 오디오 분류 문제를 해결할 수 있는가?
- 사전 훈련된 오디오 인식 모델이 최소한의 데이터로 새로운 작업에도 유연하게 적용되는 방법은 무엇인가?
4-4. Computational Complexity
CPUs는 딥러닝 모델을 훈련 및 평가하기에 최적의 선택이 아니다. 대규모 딥러닝 모델의 교육 및 평가에는 일반적으로 행렬 연산에 최적화된 프로세서인 GPGPUs 또는 TPUs이 사용된다. 계산 리소스에 엄격한 제한이 있는 응용 프로그램은 더 작은 모델이 필요하다. 최근에는 연구가 최소 계산 예산으로 신경망을 단순화, 압축 또는 훈련시키는 데 집중되어 있지만, 실시간 오디오 신호 처리의 특정 요구 사항을 탐색하는 것이 유용할 수 있다.
4-5. Interpretability and Adaptability
딥러닝에서, 연구자들은 주로 타겟 작업을 위한 layer 블록과 손실 함수를 사용하여 네트워크 구조를 설계한다. 모델의 파라미터는 손실에 대한 기울기 손실을 사용하여 학습된다. layer 파라미터와 실제 작업 간의 연결은 해석하기 어렵기에 연구자들은 network 뉴런의 활동을 타겟 작업과 관련시키려고 노력해왔다. (ex. 예측이 어떤 인풋을 기반으로 하는지)
✔ ref
논문
DCT와 MFCC 추가 설명
