
0. Abstract
최근 Transformer와 Convolution Neural Networks (CNNs) 기반의 모델이 Automatic Speech Recognition (ASR)에서 Recurrent Neural Networks (RNNs)을 능가하는 결과를 보였다. Transformer은 content 기반 global interaction을 capture 하는 반면 CNNs는 local feature을 효과적으로 활용한다. 본 논문에서는 local과 global 모두에서 효율적인 방법인 CNN과 Transformer을 결합하여 Conformer라는 음성 인식을 위한 convolution-augment Transformer를 제안한다. Conformer은 이전의 Transformer 및 CNN 기반 모델들을 능가하며 SOTA를 달성하였다.
1. Introduction
-
Self-attention 기반의 Transformer
- long-range global context에 강함
- 높은 training 효율성
- fine-grained local feature 패턴을 추출하는 능력은 떨어짐 <단점>
-
CNNs
- local 정보를 활용하며 vision에서 computational block으로 사용
- 이 block은 local window에서 공유된 위치 기반 커널을 학습하여 translation 등분산을 유지하고 edges나 shapes와 같은 features를 capture함
- <단점> global 정보를 capture 하기 위해 많은 layer과 parameter가 필요
저자는 parameter의 효율성을 위해서는 global와 local 모두의 interaction이 중요하기 때문에, self-attention와 convolution의 결합은 global & local 모두에서 최고를 달성할 것이라고 제안한다. 본 논
문은 그림 1과 같이 한 쌍의 feed forward 모듈 사이에 낀 self-attention와 convolution의 새로운 결합인 Conformer을 소개한다.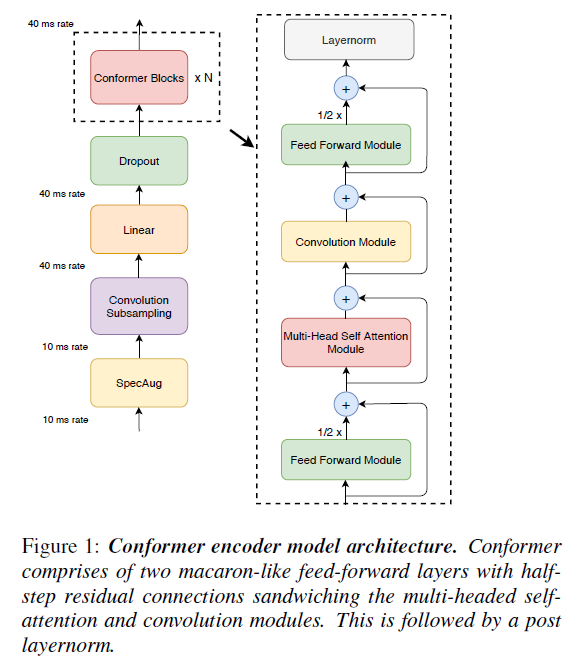
2. Conformer Encoder
2-1. Multi-Headed Self-Attention Module
relative sinusoidal positional 인코딩 방식인 Transformer-XL의 주요 기술을 통합하면서 multi-headed self-attention(MHSA)를 사용한다. realative positional 인코딩을 통해 self-attention 모듈이 다양한 input 길이에 더 잘 일반화할 수 있으며, 결과 인코딩 발화(utterance) 길이의 변화에 더 둔감하다. 저자는 prenorm residual units을 더 깊은 모델을 훈련하고 정규화 할 때 도움이 되는 dropout과 사용한다. 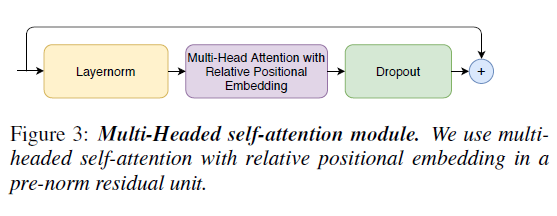
2-2. Convolution Module
Convolution 모듈은 pointwise convolution과 gated linear unit (GLU)인 gating mechanism으로 시작하며 그 뒤에는 단일 1-D depthwise convolution layer이 위치한다. Batch norm은 convolution 직후에 배치되어 심층 모델 훈련을 돕는다. 
2-3. Feed Forward Module
- Transformer는 MHSA 이후에 Feed Forward 모듈이 이어지고, 이는 두 개의 선형 transformation와 비선형 activation 사이에 위치함. Feed Forward layer에 잔차 연결이 추가된 후 layer regulation이 수행됨.
이와 달리 저자는 pre-norm residual units을 따르고 첫번째 linear layer 이전의 input이랑 residual unit 내에서 layer regulation을 적용한다. 또한 network 정규화에 도움이 되는 Swish activation와 dropout을 적용한다.

2-4. Conformer Block
본 논문에서 제안한 Conformer block은 2개의 FFN이 MHSA와 Convolution 사이에 껴있는 구조이다. FFN 모듈에 half-step residule weights를 사용한다. 두번째 FFN 뒤에는 최종 layernorm layer이 따른다.
3. Experiments
3-1. Results
- 단일 neural network에서 Transformer와 convolution의 결합이 효과가 있음을 보인다.
- Convolution sub-block이 가장 중요한 feature이며, 단일 FFN보다 한 쌍의 FFN을 갖는게 더 효과적이다. swish activation을 사용하면 더 빠르게 converge가 가능하다.
- Conformer block에서 MHSA 뒤에 Convolution 모듈을 배치하는 것이 좋다.
- attention head를 최대 16개까지 증가시키면 특히 dev-other dataset에서 accuracy가 향상된다.
- kernel size가 클수록 성능이 향상되며, kernel size가 32인 경우가 가장 성능이 좋다.
4. Conclusion
본 논문에서는 CNN과 Transformer의 구성 요소를 통합하여 end-to-end 음성 인식하는 Conformer을 소개한다. 각 구성 요소의 중요성을 연구하고 Conformer 모델의 성능에 convolution 모듈을 포함하는 것이 매우 중요하다는 것을 증명했다. 이 모델은 LibriSpeech dataset에 대한 이전 작업들보다 적은 수의 parameter로 더 좋은 accuracy를 보이고 test/test-other의 경우 1.9%/3.9%로 SOTA를 달성한다.
