0. Abstract
본 논문은 raw audio 표현으로부터 학습한 음성 인식의 비지도 사전 훈련을 탐구한다. wav2vec은 레이블이 지정되지 않은 대량의 오디오 데이터에서 훈련되며 최종적인 표현은 음향 모델의 향상을 위해 사용된다.
1. Introduction
모델이 좋은 성능을 얻기 위해선 많은 양의 데이터가 필요하다. 신경망의 사전 훈련이 레이블 된 데이터가 부족한 현실을 해결한다. 여기서 아이디어를 얻어 많은 양의 lable/unlabel 데이터에서 일반적인 표현을 학습하고 그 표현을 활용함으로써 데이터 양이 제한된 작업에서도 성능을 향상시키는 방법을 음성 인식에도 적용한다. 본 논문에서는 수집이 용이한 레이블되지 않은 오디오 데이터를 활용하기 위해 원시 오디오를 인풋으로 사용하고 음성 인식에서 사용할 수 있는 일반적인 표현을 계산하는 convolution 신경망인 wav2vec을 제안한다.
2. Pre-training Approach
2-1. Model
원시 오디오 신호를 인풋으로 받은 후 2개의 네트워크를 사용한다.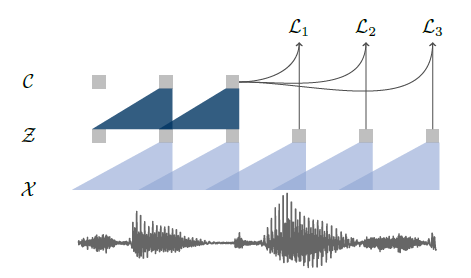
- 첫번째 인코더 네트워크
- 인풋은 원시 오디오 샘플인 의 집합인 임.
- 5개의 convolution 네트워크로 매개변수화 됨.
- 커널 크기 (10, 8, 4, 4, 4)와 스트라이드 (5, 4, 2, 2, 2)
- 아웃풋 표현은 낮은 주파수 피처 표현인 임.
- 두번째 컨텍스트 네트워크
- 는 의 집합임.
- 여러 잠재 표현 을 단일 contextualized 텐서인 로 혼합함. 이때 는 수용 영역 크기임. 총 수용 영역의 크기는 약 210ms임.(=CNN의 단점인 global을 못담는다는걸 해결함)
- 커널 크기가 3, 스트라이드 1인 9개의 layer로 구성됨.
인코더와 컨텍스트 네트워크의 레이어는 모두 512 채널을 가진 casual convolution(특정 시점 이전의 정보만 참조), 그룹 정규화 레이어 및 ReLU 비선형성으로 구성되어 있다. 각 샘플에 대해 피처 및 시간 차원을 모두 정규화한다. ****인풋의 스케일링과 오프셋에 불변인 정규화 체계를 선택하는 것이 중요하며, 이를 통해 데이터셋 간에 잘 일반화되는 표현을 얻을 수 있다.
cf. wav2vec large
wav2vec large는 큰 데이터셋에서 훈련하기 위해 고안한 변형 모델이다. 이는 인코더에 두 개의 선형 변환이 추가적으로 들어 있으며, 컨텍스트 네트워크는 커널 크기가 점점 증가하는 12개의 layer로 구성되어 있다. 이 경우, 수렴을 도울 수 있도록 aggregator에 skip connection을 도입하는 것이 중요하다. 이로 인해 마지막 컨텍스트 네트워크 층의 총 수용 영역이 약 810 ms로 증가한다.
❓ CNN만을 사용하여 global하게 포착할 수 있었던 방법?
여러 layer에서 convolution하면 kernel에 의해 포착되는 범위가 넓어짐. Wav2Vec은 네트워크 내에서 여러 layer의 CNN을 쌓음으로써 global한 피처까지 포착함.
❓ 네트워크 구조를 x→z→c로 한 이유?
데이터 분포 p(x)를 정확히 모델링하는 것은 어려움(= x→c 직접 예측). 따라서 낮은 주파수 표현인 z로 인코딩한 후 모델링 함. x→z로 갈 때 여러번 convolution 되므로 시간 해상도가 낮아지고, 이는 더 낮은 sampling rate으로 샘플링하는 것과 같은 효과임. 따라서 주파수 해상도도 낮아짐.
2-2. Objective
k 단계 미래의 샘플 와 제안 분포 에서 뽑은 샘플 를 구별하고자 각 단계에 대해 contrastive loss를 최소화하며 모델을 훈련시켰다. 
- sigmoid 함수 :
- : 가 true 샘플일 확률
- 각 k 단계에 적용되는 단계별 affine 변환 :
- 각 k 단계에 대한 손실 의 총합( )을 최적화한다.
- 기대값을 추정하기 위해 각 오디오 시퀀스에서 distractor를 균등하게 선택하여 10개의 negative 샘플을 샘플링한다. 이때, 제안 분포인 가 된다. ( 는 시퀀스의 길이, 는 negative 샘플 수)
최종적으로 각 k 단계에서 구해진 손실을 최소화하며 학습되고, 그 과정에서 true 샘플인 표현은 벡터 공간 내에서 가까워지고, negative 샘플은 멀어진다. 즉, negative 샘플로부터 true 샘플을 구별해낸다. 위와 같은 훈련 후 생성된 표현 를 음향 모델의 인풋으로 사용한다.
💡 CPC(Contractive Predictive Coding)
: 고차원 데이터에서 표현 벡터(high-level 정보)를 추출하는 비지도 학습 기법
- 원시 오디오인 x를 latent 벡터 z로 인코딩
- noise 제거하고 압축
- latent 공간의 현재 시점 t 이전의 모든 값에 대해 요약(??) 후 context latent 표현 생성
- (true 샘플)와 사이의 mutual 정보를 보존 → context 벡터가 mutual 정보를 잘 담도록 학습
- contrastive predictive coding
- 비교를 통해 mutual 정보를 최대한으로 추출하고, negative 특성을 최대한 배제
3. Experimental Setup
3-1. Data
TIMIT
음소 인식에서 표준 train, dev, test 분할을 사용하며, train 데이터에는 약 3시간 이상의 오디오 데이터가 포함되어 있다.
Wall Street Journal(WSJ)
약 81시간의 전사된 오디오 데이터로 구성되어 있다. si284에서 훈련하고 nov93dev에서 검증하며 nov92에서 테스트한다.
Librispeech
깨끗한 음성 데이터와 노이즈가 있는 음성 데이터가 총 960시간 있다.
사전 훈련을 위해 WSJ의 81시간, 깨끗한 Librispeech의 80시간, 전체 960시간의 Librispeech 훈련셋 혹은 이들의 조합 중 하나를 사용한다. baseline 음향 모델을 훈련하기 위해 25 ms 슬라이딩 창과 10 ms 간격의 80 log-mel 필터뱅크 계수를 계산한 후 WER과 LER로 평가한다.
3-2. Acoustic Models
음향 모델의 훈련 및 평가를 위해 wav2letter++ toolkit을 사용한다.
- TIMIT은 Zeghidour et al. (2018a)의 문자 기반 wav2letter++ 설정을 따른다. 커널 크기 5, 1,000 채널을 가진 7 개의 연속적인 convolution 블록을 사용한다. 그 후 PReLU 비선형성과 0.7 비율의 dropout을 사용한다. 최종 표현은 39차원의 음소 확률로 투영된다. 이 모델은 Auto Segmentation Criterion (ASG; Collobert et al., 2016)을 사용하여 훈련한다.
- WSJ은 Collobert et al. (2019)에 의해 설명된 wav2letter++ 설정을 baseline으로 한다. gated convolution을 사용한 17개 laeyr의 모델이다. 모델은 표준 영어 알파벳, apostrophe, period, 두 개의 반복 문자(ex. "ann"은 an1으로 전사됨) 및 단어 경계로 사용되는 silence 토큰 ()를 포함한 31개의 graphemes 대한 확률을 예측한다.
모든 음향 모델은 8대의 NVIDIA V100 GPU에서 fairseq와 wav2letter++의 분산 훈련 구현을 사용하여 훈련된다. WSJ에서 음향 모델을 훈련할 때 학습률 5.6, gradient clipping과 함께 SGD를 사용하며, 총 batch 크기는 64개 오디오 시퀀스를 1000 epoch동안 훈련한다. early stopping을 사용하고 4-gram 언어 모델로 체크포인트를 평가한 후 validation WER을 기준으로 모델을 선택한다. TIMIT의 경우 학습률 0.12, momentum 0.9, batch 크기는 16개 오디오 시퀀스로 8대의 GPU에서 1,000 epoch동안 훈련한다.
3.3 Decoding
WSJ 언어 모델링 데이터만 사용하여 훈련된 별도의 언어 모델인 lexicon을 사용한다.
사용한 언어 모델 : 4-gram KenLM, 단어 기반 convolutional 언어 모델, 문자 기반 convolutional 언어 모델
- : 음향 모델, : 언어 모델, : y의 문자들
- 는 각각 언어 모델, 단어 패널티, silence 패널티에 대한 가중치로 랜덤 서치로 최적의 파라미터 찾음
- 단어 기반 언어 모델에 대해서는 빔 크기 4,000, threshold 250을 사용하고, 문자 기반 언어 모델에 대해서는 빔 크기 1,500, threshold 40을 사용
이를 통해 컨텍스트 네트워크 c 또는 log-mel 필터뱅크의 아웃풋인 단어 시퀀스 y를 디코딩한다.
3.4 Pre-training Models
사전 훈련 모델은 PyTorch에서 fairseq toolkit을 사용하여 구현했다. Adam, 코사인 학습률 스케줄을 사용하여 최적화 했다. WSJ와 깨끗한 Librispeech 훈련 데이터셋에 대해서는 40k 단계 동안 annealed(단련된?) 학습률을 사용하였고, 전체 Librispeech에 대해서는 400k 단계 동안 사용하였다. 학습률은 1xe-7로 시작해 5xe-3까지 증가하다 코사인 곡선을 따라 1xe-6까지 감소했다. objective를 계산하기 위해 각 K = 12에 대해 업데이트 단계당 10개의 negative를 샘플링한다.
첫 번째 wav2vec 변형을 8개의 GPU에서 훈련하며, 각 GPU에 최대 1.5M 프레임에 해당하는 오디오 시퀀스를 배치한다. 시퀀스는 길이에 따라 그룹화되며, 각각을 최대 크기인 150k 프레임과 batch에서 가장 짧은 시퀀스의 길이 중 더 작은 값으로 자른다. 자르기는 시퀀스의 처음 또는 끝에서 음성 신호를 제거하며 각 샘플에 대한 자르기 오프셋은 무작위로 결정된다. 이것은 데이터 증강의 형태임과 동시에 GPU에서 모든 시퀀스의 동일한 길이를 보장하며 훈련 데이터의 25%를 평균적으로 제거한다. 자른 후, GPU 간의 총 유효 batch 크기는 약 556초의 음성이다. 큰 모델 변형의 경우 16개의 GPU에서 훈련하며 유효 batch 크기를 두 배로 늘렸다.
4. Results
4.1 Pre-training for the WSJ benchmark
사전 훈련된 표현은 성능을 향상시킨다.
사전 훈련된 표현은 log-mel 필터뱅크 피처로 훈련된 문자 기반 baseline 모델에 비해 성능을 크게 향상시켰다. wav2vec은 문자 기반 접근 방식인 Deep Speech 2 보다 WER을 0.27 개선시켰으며, Librispeech 레이블에서 사전 훈련한 후 WSJ에서 파인 튜닝한 기존의 음소 기반 모델을 wav2vec large는 더 약한 baseline 모델을 사용하고 Librispeech 전사를 사용하지 않고도 능가한다. 이는 레이블이 없는 오디오 데이터에 대한 사전 훈련이 좋은 성능을 보임을 뜻한다.
많은 데이터에서의 사전 훈련이 좋은 성능을 보인다.
적은 양의 전사된 데이터로 사전 훈련된 표현이 어떤 영향을 미치는지 알아보기 위해 다른 양의 레이블이 지정된 훈련 데이터로 음향 모델을 훈련하고, 사전 훈련된 표현을 사용할 때와 안 할 때의 정확도를 비교한다. 사전 훈련된 표현은 전체 Librispeech에서 훈련되었으며, 4-gram 언어 모델을 사용하여 디코딩할 때 WER을 기준으로 정확도를 측정한다. 전사된 데이터가 약 8시간만 사용 가능한 경우에도 nov92에서 WER이 36% 감소했다. WSJ의 오디오 데이터만을 사용하여 사전 훈련한 경우 (wav2vec WSJ) 매우 큰 Librispeech (wav2vec Libri)에 비해 성능이 좋지 않았다. 이는 많은 데이터에서의 사전 훈련이 좋은 성능을 보인다는 것을 뜻한다.
4.2 Pre-training for TIMIT
마찬가지로 사전 훈련 데이터 양이 늘어날수록 정확도가 증가하며, 가장 많은 양의 데이터를 사용한 사전 훈련에서 가장 좋은 정확도를 달성했다.
4.3 Ablations
negative 샘플 수는 10개일 때 성능이 가장 좋음
negative 샘플 수를 제외하고 모든 것을 동일하게 했을 때, negative 샘플 수를 10개까지 늘리면 성능이 향상됐다. (깨끗한 Librispeech에서 사전 훈련하고 TIMIT에서 평가함) 이후로는 성능이 안정되고 훈련 시간이 증가한다. 그 이유는 negative 샘플의 양이 증가함에 따라 positive 샘플의 훈련 신호가 감소하기 때문이라고 추측된다.
오디오 시퀀스 자르기를 통한 데이터 증강의 효과
batch를 생성할 때 시퀀스를 사전에 정의된 최대 길이로 자른다. 그 결과, 150k 프레임으로 잘랐을 때 가장 좋은 성능을 보였다. 최대 길이를 제한하지 않는 경우(None) 약 207k 프레임의 평균 시퀀스 길이를 얻으며 최악의 정확도를 보였다. 그 이유는 이 설정에서 가장 적은 양의 데이터 증강을 제공하기 때문이라고 추측된다.
그 외
12 단계 이상 예측하는 것이 더 좋은 성능을 보이진 않으며, 단계를 늘리면 오히려 훈련 시간이 증가한다.
5. Conclusions
wav2vec은 완전한 convolution 모델로, 최초의 음성 인식 비지도 사전 훈련 모델이다. 이는 WSJ의 테스트 세트에서 2.43%의 WER을 달성하였으며 이전의 최고 성능 모델보다 전사된 훈련 데이터 양을 적게 사용했음에도 능가한다.
✔ ref
Wav2Vec
https://velog.io/@ingsol/논문리뷰Connectionist-Temporal-Classification-Labelling-Unsegmented-Sequence-Data-with-Recurrent-Neural-Networks
