1. Introduction
Transformer based paino cover 생성 모델인 Pop2Piano를 소개한다. 이는 팝 음악의 파형으로부터 piano performance (MIDI)를 만들어내는 모델이다.
- 피아노 커버 생성에 대한 새로운 접근 방식을 제안한다. P2P(Piano Cover Synchronized to Pop Audio)라는 300시간의 동기화된 {Pop, Piano Cover} dataset을 구축하고 이를 만드는데 사용되는 전처리 시스템을 소개한다.
- 주어진 오디오에서 피아노 커버를 생성하는 Transformer network인 Pop2Piano를 설계한다. 멜로디나 코드 추출기를 사용하지 않고 spectrogram 자체를 input으로 사용하며, 편곡기 token을 사용하여 커버 스타일을 조정한다.
2. Related Work
2-1. Automatic Music Transcription
Automatic Music Transcription (AMT)는 악기의 파형으로부터 note 정보를 추정하는 작업이다. piano AMT에서는 CNN과 RNN architecture을 사용하여 feature를 추출하고 note onset, offset, frame을 모델화했다. 일부 연구에서는 Transformer와 spectrogram을 사용하여 MIDI를 생성했다. 다중 악기 AMT는 여러 악기의 혼합된 사운드로부터 각 악기에 대한 note 정보를 추정하는 것을 목표로 한다.
이러한 연구는 MAESTRO와 Slakh2100 같은 대규모 동기화 된 악기-오디오 데이터 세트에서 유망한 결과를 도출했다. 피아노 커버 생성을 이한 모델 훈련을 위해 300시간 동기화된 피아노 커버 데이터 세트를 구축한다.
AMT와 피아노 커버 생성은 오디오 음악 음을 변환하는 데 있어 유사하지만 피아노 커버 생성은 정답이 없다는 점에서 다르다. (→ 원곡의 분위기나 편곡자의 스타일에 따라 화음이 다양한 반주로 나타날 수 있다!)
2-2. Music Transformation
Music Transformation은 음악 데이터를 조작하는 것을 목표로 하는 연구 분야이다. 가장 일반적인 접근법인 music style transfer은 음악 본연의 음악적 특성을 살리면서 음악을 다른 style로 변형시키는 작업이다. 음악 style에 대한 공통된 정의가 없기에 본 논문에서는 주어진 팝송의 피아노 커버를 만들 때 편곡자마다 달라지는 음악적 해석과 작곡 과정이라 정의한다.
또 다른 일반적인 접근법인 music reduction은 음악 콘텐츠를 보존하면서 더 작은 악기들로 또는 한 명의 연주자가 연주할 음악으로 재배열하는 과정이다. audio-based 악기 커버에 대한 연구는 단일 악기로의 music reduction로 간주할 수 있다. 이전의 연구는 오디오에서 멜로디와 코드를 추출하기 위해 외부 모듈을 사용했다. Song2Guitar는 모듈을 사용하여 멜로디, 화음 및 비트를 추출함으로써 pop audio에서 기타 커버를 생성했다. 그 후, fingering 확률을 통계적으로 모델링하여 guitar tab score을 만들었다.
이와 대조적으로 본 논문의 Pop2Piano는 pop audio에서 직접 피아노를 생성하는 추출기만 사용한다.
3. Data
raw 파형 쌍을 모델링할 때 주요 병목 현상은 긴 범위의 종속성인데, 이는 음악의 고차원 의미론을 계산적으로 학습하기 어렵기 때문이다. 이에 대한 대안으로 짧은 범위의 파형 segment를 쌍으로 훈련하는 방법이 있다. 이 방법은 쌍을 이루는 데이터를 동기화해야 하며, 그렇지 않으면 쌍을 이루는 segment 데이터에 올바른 label이 포함되지 않을 위험이 있다. 수집된 데이터 쌍이 동기화되지 않아 저자는 아래와 같이 동기화된 {Pop, PianoCover} 데이터를 얻기 위한 전처리 pipeline을 개발했다.
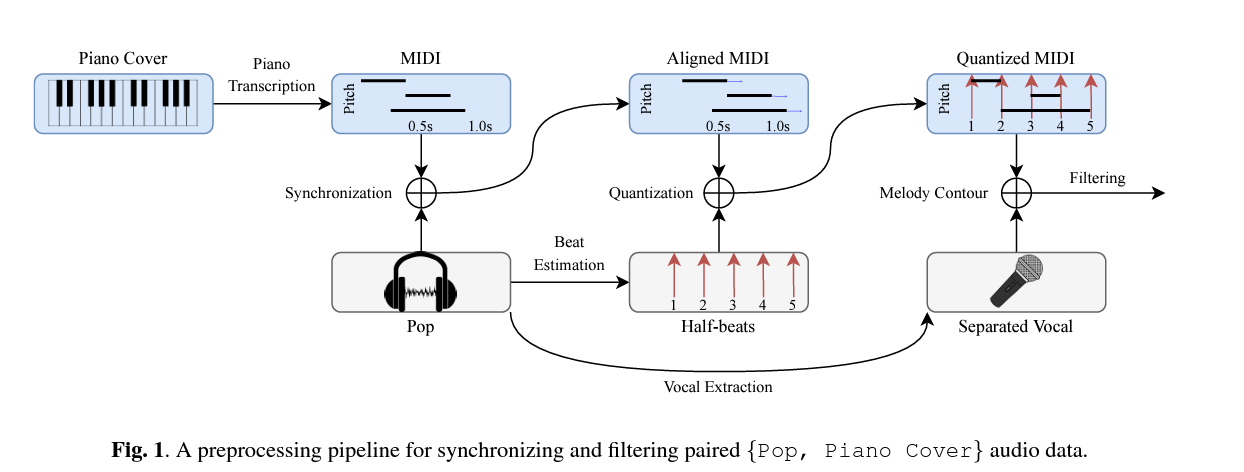
3-1. Preprocessing
3-1-1. Synchronizing Paired Music
- piano transcription model을 사용하여 피아노 커버 오디오를 MIDI로 변환한다.
- pop audio와 함께 piano MIDI를 대략적으로 align 한다. SynctoolBox을 사용하여 warping path를 얻은 후 이를 이용하여 linear interpolation을 통해 MIDI의 음정 타이밍을 수정한다.이를 통해 피아노 커버와 pop audio 간의 간단한 동기화를 제공한다.
- 음정 타이밍은 8비트로 양자화한다. Essentia를 이용하여 pop audio에서 비트를 추출한 후, MIDI에서 각 음정의 oneset와 offset은 가장 가까운 8비트로 양자화된다. 양자화된 onset과 offset이 동일하면 offset은 다음 비트로 이동한다. 이와 같이, 음의 시간 단위를 연속 시간(초)에서 양자화된 시간(비트)로 변겨함으로써 데이터의 엔트로피를 낮출 수 있다.
3-1-2. Filtering Low Quality Samples
음악 진행의 차이 또는 원곡과 다른 키를 갖는 등의 이유로 데이터 쌍이 부적합한 경우가 있다. 이러한 경우를 필터링 하기 위해 0.15 이하의 melody chroma accuracy (MCA) 또는 오디오 길이 차이가 20% 이상인 모든 데이터를 폐기한다.
- MCA는 오디오에서 추출된 보컬 신호의 피치 윤곽(pitch contour)과 MIDI의 탑라인에서 계산된다.
- 저자는 보컬 신호를 분리하기 위해 Spleeter를 사용한다.
- 그 후 pop 음악의 멜로디 윤곽을 얻기 위해 Librosa pYIN을 사용하여 보컬의 f0 시퀀스를 계산한다.
- sample rate는 44100이고 hop lenth는 1024이다.
3-2. Piano Cover Synchronized to Pop Audio(PSP)
저자는 유튜브에서 21개의 편곡자와 해당 팝송으로부터 5989개의 피아노 커버를 수집한다. 그 후 동기화하고 {Pop, PianoCover}를 필터링한다. 그 결과 총 4989개의 트랙(307시간)이 남아 있으며, 이 트랙들은 PSP라는 training set로 사용된다.
Note that the piano cover included in the PSP is unique, but the original song is not. 이는 편곡자 조건과 주어진 오디오의 음향적 특성에 따라 피아노 커버 스타일을 따로 training 하는 데 도움이 될 것이다..
4. Model
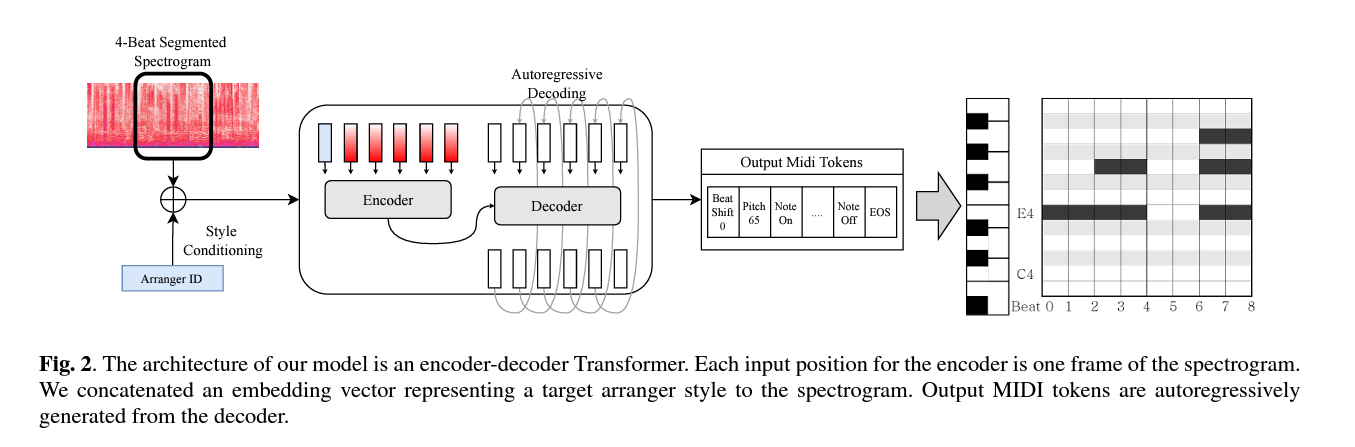
4-1. Inputs and Outputs
Pop2piano는 pop audio의 log-mel spectrogram을 encoder의 input으로 사용한다. sampling rate는 22050, window size는 4096, hop size는 1024이다. 또한 spectrogram의 첫 번째 frame 앞에 target 피아노 커버를 누가 편곡했는지 나타내는 arranger token을 임베딩하여 추가한다.
decoder ouput의 각 단계는 다음과 같은 유형의 토큰 중에서 선택된다.
- Note Pitch [128 values]
MIDI 피치 중 하나에 대한 피치를 나타낸다. 하지만 피아노 건반에 해당하는 88개의 음정만 실제로 사용된다.
- Note On/Off [2 values]
이전 Note pitch event가 note-on으로 해석되는지 note-off로 해석되는지 여부를 결정한다.
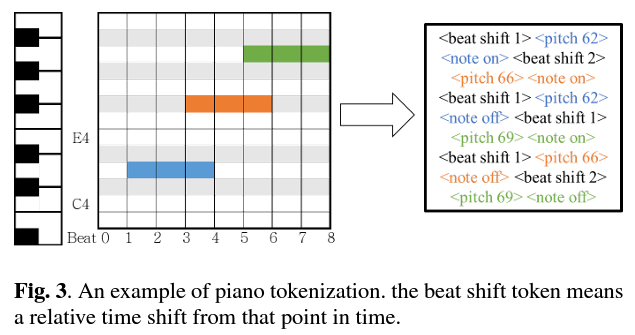
- Beat Shift [100 values]
8비트로 양자화된 segment 내의 상대적인 시간 이동을 나타낸다. 이는 다음 beat shift event가 발생할 때까지 이후의 모든 note-related event에 적용된다. 최대 50 beat까지 Beat shift로 정의하지만, segment마다 시간이 재설정되기 때문에 실제로는 이러한 유형의 event를 10개 정도만 사용한다.
- EOS, PAD [2 values]
시퀀스의 끝과 시퀀스의 padding을 나타낸다.
각각의 input에 대해, 모델은 decoder에서 EOS 토큰이 생성될 때까지 output을 autoregressively 생성한다. 임의 길이의 pop audio의 피아노 커버를 생성하기 위해, 추론 단계에서는 오디오를 4비트씩 순차적으로 잘라 모델에 대한 input으로 사용한 후 생성된 토큰(EOS 제외)을 축약한다. 그 후, 생성된 토큰의 relative 비트는 원곡에서 추출된 비트의 절대 시간 정보를 사용하여 절대 시간으로 변환된 다음, 표준 MIDI 파일로 변환된다.
4-2. Architecture
Pop2Piano 모델 architecture은 MT3에 사용되는 T5-small이다. 이는 encoder-decoder 구조를 갖는 Transformer network이다. 학습 가능한 parameter 수는 약 59M이다. MT3와 달리, absolute positional embedding 대신 원래 T5의 relative positional embedding을 사용한다. 또한, 편곡자 스타일을 임베딩하기 위해 학습 가능한 임베딩 계층이 사용된다.
5. Experiment
본 실험에서는 PSP로 훈련된 Pop2Piano가 신뢰할 수 있는 Piano 커버를 생성할 수 있는지를 확인하고 특정 편곡자의 스타일을 따르고 있는지를 검증한다.
5-1. Training Setup
저자는 random 4비트 길이로 추출된 오디오 모델을 훈련한다. 전체 PSP dataset에 대해 이 과정을 2000번 반복한다. 음악의 평균 bpm이 120이라 가정할 때, 저자는 P2P dataset을 이용하여 약 5500시간의 오디오가 훈련에 사용되었다고 추정할 수 있다. 네트워크는 AdaFactor을 사용하여 최적화되며 학습률은 0.001이다.
5-2. Generation Result
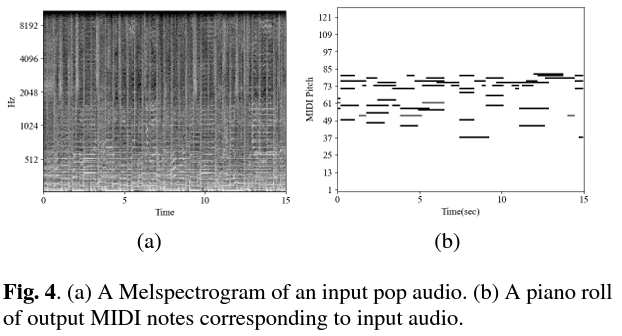
임의의 팝 음악을 input으로 하여 생성된 피아노 커버의 예시이다. 원곡은 보컬, 베이스, 퍼커션 등의 다양한 소리들이 섞인 복잡한 오디오 signal이지만, 생성된 피아노 커버는 원곡의 로컬 멜로디 라인이 쌓여있는 note들을 보여주며 원곡의 화음을 따르는 반주도 포함하고 있음을 알 수 있다.
또한, 생성된 피아노 커버가 저자가 지정한 편곡자의 스타일로 커버하였는지 확인하기 위해 Pop2Piano에 의해 생성된 피아노 커버의 note density를 측정하였다. 그 결과, 생성된 피아노 커버가 R2=0.804의 높은 선형성으로 타겟 편곡자의 note density를 따른다 할 수 있다.
MCA를 계산하여 생성된 피아노 커버의 품질을 평가했다. 저자의 결과는 명시적인 멜로디 없이 훈련되었음에도 생성된 피아노 커버의 MCA가 POP909 dataset의 MCA와 유사함을 보인다.
- POP909는 멜로디, 브릿지 및 반주에 대한 별도의 트랙이 있는 909개의 중국 팝송으로 구성된 피아노 MIDI dataset임.
5-4. Limitation
Pop2Piano의 input은 4비트 길이의 오디오만 사용하기 때문에 이보다 긴 시간을 생성할 때 멜로디 윤곽이나 반주의 질감과 같은 특징은 일관성이 적다. 또한 8 박자에 기초한 시간 양자화는 모델이 3연음, 16박, trill과 같은 다른 리듬의 피아노 커버를 생성하는 것을 방해한다.
6. Conclusion
멜로디나 코드 추출 모듈을 사용하지 않고 오디오에서 직접 팝피아노 커버를 생성하는 Transformer network 기반의 Pop2Piano를 제시한다. 모델을 훈련시키기 위해 300시간의 쌍을 이룬 {Pop, PianoCover} dataset인 PSP를 수집한다. 또한 network 훈련에 적합한 형태로 동기화하는 pipeline을 설계한다. Pop2Piano가 신뢰할 수 있는 팝 피아노 커버를 생성할 수 있으며 특정 편곡자 스타일을 따라할 수 있다고 평가한다.
