1. Demucs
input : raw waveform
output : 각 악기 소스 별 waveform 생성 (drum/bass/others/vocal)
U-net 구조 : convolution encoder, wide transposed convolution 기반의 decoder
-
encoder와 decoder 사이에 skip connection → original signal에 직접적인 접근이 가능하게 함, input 상에서 output으로 직접 transfer함
-
U-net과의 차이점 : 선형 보간이 아닌 convolution of stride of 1 사용 (적은 계산량)
-
주요 특징
- bi-LSTM(중요), 깊이에 비례하는 채널수, 마스킹 허용하는 활성화 함수(GLU)
- L1 손실을 주로 씀 (L1과 L2 사이에 큰 차이 없음)
- 초기화의 중요성
- 소스 분리 모델은 시간 동치성 (time equivariant, input을 이동시킨만큼 output도 이동됨)가 중요함 → demucs는 자연적으로 만족 x → 따라서
shift trick1제안- shift trick1 : input mixture x를 S 샘플로 무작위 이동함 → 반대의 이동을 적용한 후 각각에 대한 모델 예측을 평균냄
MusDB로 학습 (drum/base/others/vocal로 이루어진 150개 곡)
성능 평가는SDR (Signal to Distortion Ratio, 다른 소스나 아티팩트에 의한 오염된 비율)
피치/템포 증강 : 성능 향상 (사유: 오디오 저하시키지만 오히려 과적합 방지가 됨)
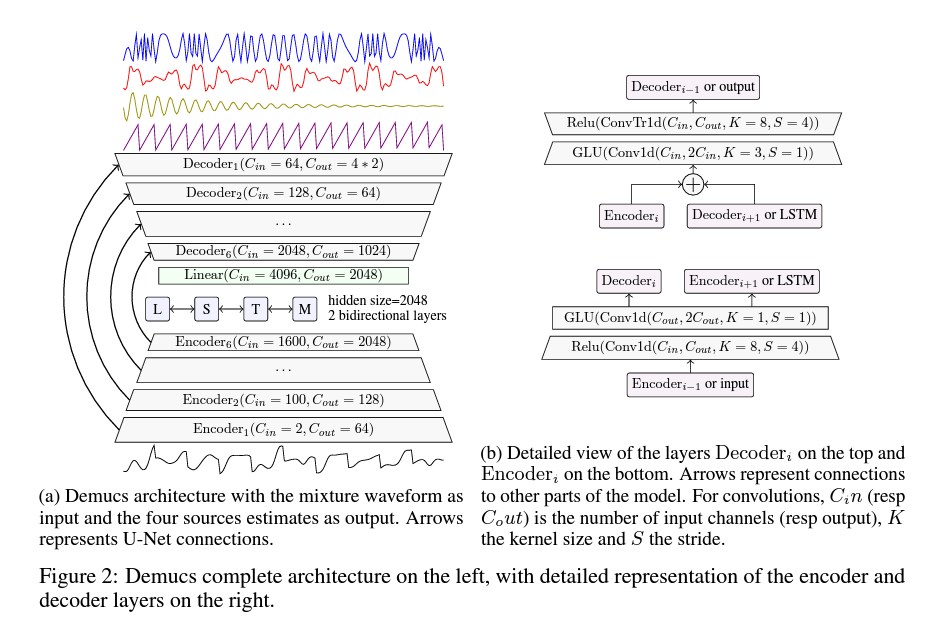
인코더 : CL=2048. 양방향 LSTM. LSTM 시간 위치당 2개의 CL채널 output(=4096)을 가짐. 따라서 CL로의 축소를 위해 linear layer 사용.
디코더 : GLU: 커널 크기 3 → 인접 timestep의 context 제공 → transpose된 컨볼루션의 출력이 시간을 일정하게 하고, stride가 4인 경우에 발생할 수 있는 잠재적인 아티팩트를 줄일 수 있음
| encoder | decoder | |
|---|---|---|
| number of layer | 6 | 6 |
| each layer kernel size | 8 | 8 |
| each layer stride | 4 | 4 |
| 특징 | 1x1 convolution kernel size 1, ReLU → 1x1 convolution은 채널을 2배로 늘리고 GLU는 반으로 줄여 일정하게 유지하게 함 | skip connection, 이전 레이어와 합산, 1x1 convolution with GLU → transposed convolution(채널 수 절반으로 줄임) → ReLU |
| encoder 들어오기 전 2배로 upsampling | decoder 나올 때 2배로 downsampling |
단점 : 모델 크기가 너무 큼 → 해결법은 초기 채널 수 줄이기 or DiffQ 양자화 기술을 사용(SDR 손실 없이 줄일 수 있음)
결론 : 베이스, 드럼은 demucs가 우세하나 나머지는 스펙트로그램 기반이 우세
- 스펙트로그램 도메인 모델은 콘텐츠가 주로 고조파이고 빠르게 변할 때 이점을 가지는 것으로 추정되며, 반면 고조파가 없는 경우(드럼) 또는 강한 어택 패턴(베이스)이 있는 경우 음파 도메인이 음악 소스의 구조를 더 잘 보존할 듯함
1-2. Hybrid Demucs
기존 demucs는 vocal 분리 때 crunchy static noise에 영향을 받아 좋지 않았음 ⇒ demucs 아키텍쳐 확장하여
end-to-end hybrid 소스 분리방법 : multi domain 분석 및 예측
Hybrid Demucs는 기존의 U-net 아키텍쳐를 확장하여 두 병렬 branch : time (temporal) & frequency (spectral) domain가 있으며, 각 branch에 skip connection이 있는 이중 U-net 구조
- time branch
- input waveform으로부터 표준 demucs처럼 처리
- 5 layer, time step 수를 줄임 (4의 제곱으로 나눔, 총 1024 나누어짐)
- ReLU(기존) → GELU로 대체
- spectral branch
- 4096 time step을 걸친 STFT로 얻은 spectrogram으로부터 얻음
- hop length = 1024
- frequency 차원을 줄이기 위해 time branch와 동일한 convolution을 frequency 차원을 따라 적용
- 5 layer, 각 layer는 주파수를 4로 나누지만 5번째 layer는 8로 나눔.
- spectral encoder 거친 후에 signal에는 1 frequency만 남음, time branch의 output과 동일한 채널 수 및 sr을 가짐
⇒ temporal and spectral representations는 공유된 encoder/decoder layer을 거쳐 time step을 2로 나눔(커널 크기 4) / 이 output은 temporal and spectral decoder 각각의 input으로 사용 / spectral branch의 output은 ISTFT으로 역변환되고 temporal branch output과 합쳐져 최종 model 예측을 제공
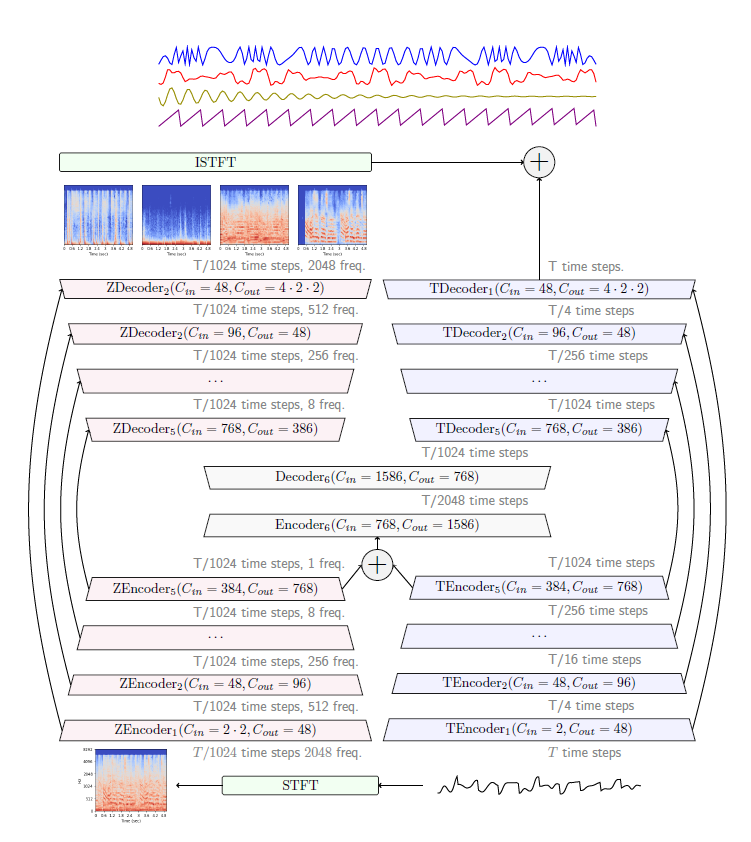
ZEncoder3&decoder3 128 freq.인듯함.. 그러면 맞음 !
-
padding
- 모든 input 길이에 대해 적절히 align 하기 위해 패딩함
- MelGAN등을 따라 P = (K-S)/2로 패딩하여 L/S output을 얻음
- 전체 stride를 맞추면 spectral and temporal representations 길이를 정확히 매치할 수 있음
- 이 패딩은 STFT와 temporal encoder의 convolution layer에 사용함
-
frequency-wise convolution
- spectral branch에서 frequency-wise convolution 사용하여 매 layer마다 주파수 bin을 4로 나눔
- 5번째 layer input은 8 frequency bin이고 이를 kernel 8에 no padding convolution사용하여 1로 줄임
- 시간 축과 달리 musical singal은 frequency 축을 따른 이동에 변함
- 악기는 특정 pitch 범위를 갖고 보컬은 명확한 형성음을 가짐. 따라서 convolution 적용 전 frequency의 embedding 주입을 제안함.
- 초기 임베딩을 smooth하게 해 가까운 frequency가 유사한 임베딩을 갖게함.
- 이는 두번째 인코더 레이어 전에 주입됨
-
compressed residual branch
- 기존 demucs encoder인 convolution with ReLU → convolution with GLU에서 두 convolution 사이에 dilated convolution으로 이루어진 2개의 compressed residual branch 도입
- 내부 layer에는 한정된 범위와 local attention을 가진 양방향 LSTM 포함됨
- 각 branch의 5번째 layer에는 이 convolution만 포함되어 있어 시간 및 스펙트럼 branch가 동일한 모양을 가짐 (compressed residual branch and 1x1 convolution 공유됨)
- comporessed residual branch 내에서는 모든 컨볼루션이 시간 차원에 대한 것이며, 서로 다른 frequency bin은 별도로 처리.
- 각 인코더 당 두 개의 comporessed residual branch 있음. 모두 커널 크기3, stride 1, 첫번째 branch dilation 1. 두번째 branch 2. output 차원은 input의 4배 적음, layer normalization + GELU
- 5&6번째 encoder layer에서는 long range context가 local attention + bi LSTM(2개의 layer)으로 처리됨 → skip connection으로 삽입 → 최대 범위는 200 steps
- input은 200 time step의 프레임으로 split with 100 time step stride
- 각 프레임은 병렬 처리. 임의의 time step에 대해 해당 time step이 가장 가장자리에서 멀리 떨어진 frame의 output이 유지
- 모든 레이어에는 kernel 1인 최종 컨볼루션으로 output 차원이 input의 2배, GLU가 따름
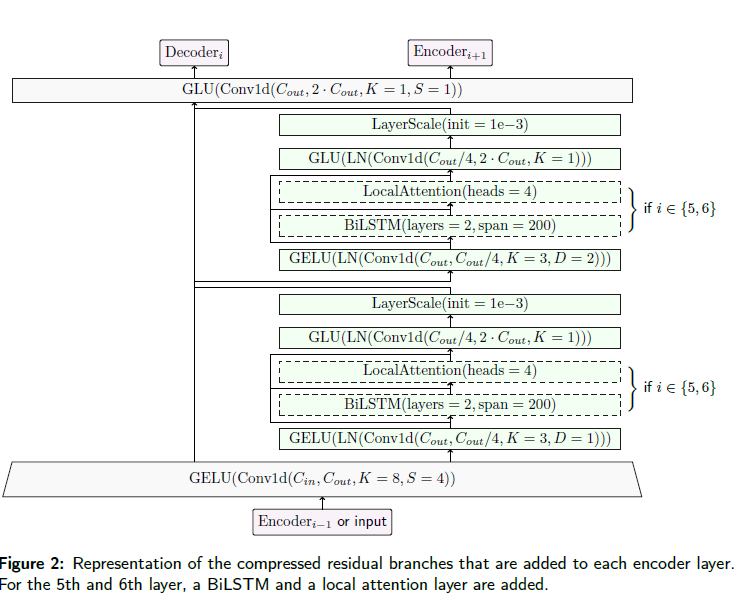
- local attention
- 일반 attention에서 위치 임베딩 대신 컨트롤 가능한 패널티 항으로 대체
- stable train (layer 수가 많아지거나 train size 150곡 추가했을 때 불안정)
- group normalization : 인코더와 디코더의 레이어 5와 6에 대한 비잔류 합성곱 다음에 그룹 정규화(4개 그룹 사용)를 사용
- 안쪽 layer에만 사용하여 성능에 영향 x
- 훈련이 안정적일 때 (only on MusDB)는 성능 개선 없음
- 훈련이 불안정적이 때 정규화 시 에포크동안 더 많은 훈련 가능
- singular value regularization
- 낮은 rank SVD 방법으로 가장 큰 특이값의 더 빠른 근사값을 얻음
- 훈련이 이미 안정되어 있을 때도 일반화 개선
- 그러나 불안정성이 완전히 제거되지는 않음
- 훈련 시간이 더 길어짐
- group normalization : 인코더와 디코더의 레이어 5와 6에 대한 비잔류 합성곱 다음에 그룹 정규화(4개 그룹 사용)를 사용
- finetuning (멜로디 라인에 너무 의존하지 않도록 → trackB 사용한 데이터셋)
- librosa :: 드럼 소스에 비트 추적, 나머지는 크로마그램 추정 적용
- 시간에 따른 크로마그램을 단일 크로마 분포로 집계하고 두 스템 간의 최대 중첩을 측정하는 데 사용되는 L1 거리에 따라 최적의 음정 이동을 찾음
- 베이스 라인의 최적 이동은 보컬 및 반주에 대해서도 동일하다고 가정
- 템포와 첫 비트를 정렬
- 아티팩트를 제한하기 위해 3 세미톤 미만의 이동 및 15%의 템포 변경이 필요한 경우에만 두 스템이 혼합되도록 허용
- spectrogram branch 대신 residual branch 사용하여 성능 향상
- Hybrid Demucs는 other, vocal SDR을 개선했으나 여전히 다른 모델에 비해 낮음
1-3. Hybrid Transformer Demucs(v4)
기존(=hybrid demucs)의 가장 바깥쪽 4개의 레이어는 유지하고 인코더와 디코더의 가장 안쪽 2개의 레이어(로컬 어텐션과 bi-LSTM)를
cross-domain transformer encoder로 대체 → 이는 스펙트럼 branch의 2D 신호와 웨이브폼 branch의 1D 신호를 병렬로 처리Hybrid Demucs는 시간과 주파수 표현을 allign 하기 위해 모델 parameter를 조정해야 했으나, cross-domain transformer encoder는 이질적인 데이터 형태에서 작동할 수 있기 때문에 더 유연함
-
Transformer encoder layer
- 단일 self-attention encoder layer
- self-attention과 feed forward 전에 정규화, train 안정화를 위해 layer scale과 결합
- 그 후 time layer norm (모든 토큰이 함께 정규화)
- input/output 차원은 384
- 선형 layer 사용
- attention mechanism은 8개 head 가짐
- feed forward network는 transformer 차원의 4배
-
Cross-domain encoder layer
- 동일하나, 다른 도메인과의 corss-attention 사용
-
Cross-domain transformer encoder
- spectral / temporal domain에서 transformer encoder layer와 cross-attention encoder layer 교차됨(interleave)
- 각 도메인 input에 1D/2D sinusoidal 인코딩 추가 후 spectral domain은 reshape (시퀀스로 처리하기 위해서)
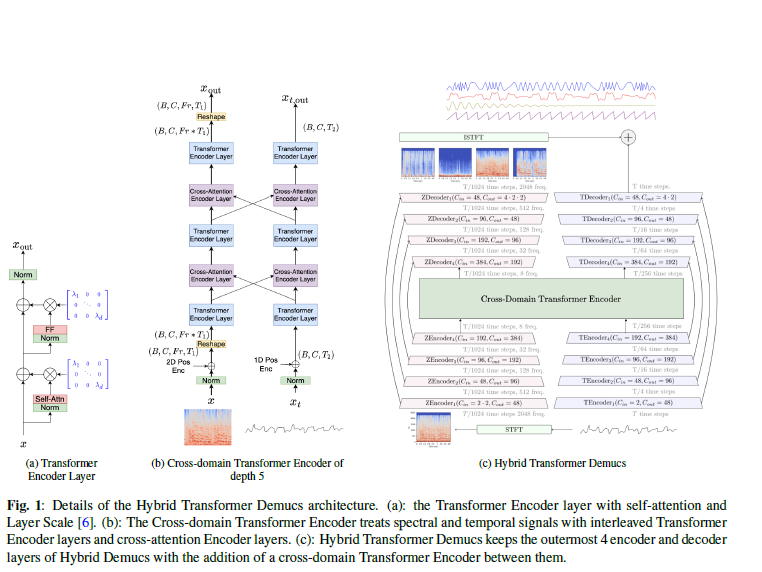
-
Sparse HT Demucs
- 시퀀스 길이가 증가함에 따라 메모리 소비 및 어텐션 속도가 저하됨 → 확장을 위해 sparse attention kernels 사용 + LSH(locally sensitive hashing) 체계 사용하여 동적으로 패턴 결정
- 32회의 LSH 전체에서 최소한 k번 일치하는 요소를 선택하고 k는 sparse level이 90%가 되도록 선택
-
train dataset
- musedb
- 다양한 장르를 가진 200명 아티스트의 3500곡 → 전처리 후 800곡
-
결론
- 대규모 train dataset으로 훈련하여 Hybrid Demucs SDR을 0.45 dB 능가
- input 길이는 최대 12.2초까지 확장(Sparse attention tech)
