1. Introduction
-
통계적 파라미터 TTS
텍스트 프론트엔드가 다양한 언어적 특징을 추출하고, 지속 시간 모델, 음향 특징 예측 모델, 복잡한 신호 처리 기반 Vocoder가 있음. 이러한 구성 요소들은 광범위한 도메인 전문 지식을 기반으로 하며, 설계하기 어렵고, 독립적으로 훈련되어 각 구성 요소에서 발생하는 오류가 합쳐질 수 있음.
-
<text, audio> 쌍으로 훈련될 수 있는 end-to-end TTS
- 휴리스틱 및 취약한 디자인 선택을 포함할 수 있는 번거로운 특징 x
- 스피커나 언어와 같은 다양한 속성에 대한 풍부한 조건부 처리를 보다 쉽게 허용함. 이는 모델의 매우 초기에 조건부 처리가 가능하기 때문임. 마찬가지로 새로운 데이터에 대한 적응도 더 쉬움
- 각 구성 요소의 오류가 합쳐질 수 있는 다단계 모델보다 단일 모델이 더 견고할 것으로 예상됨.
-
TTS에서 end-to-end 모델이 어려운 이유?
같은 텍스트가 발음이나 말하는 스타일에 따라 달라질 수 있기 때문임. 또한, end-to-end 모델의 아웃풋은 인풋보다 더 길고 연속적이기에 예측 오류가 빠르게 누적됨.
본 논문에서는 Tacotron이라는 end-to-end TTS 생성 모델을 제안함. 이는 seq2seq 및 attention 패러다임을 기반으로 함.
3. Model Architecture
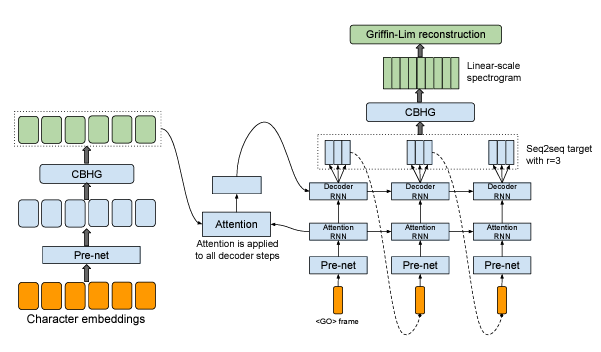
Tacotron의 backbone은 attention을 사용한 seq2seq 모델임. high-level에서 인풋으로 문자를 받은 후 스펙트로그램을 생성한 후 이를 파형으로 변환함.
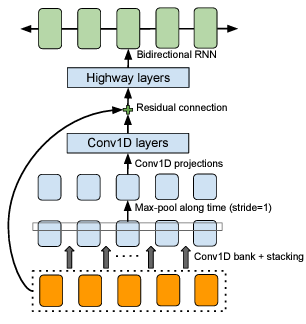
3-1. CBHG Module ⭐
CBHG 구조 : 1-D Convolutional Bank + Highway networks + GRU
CBHG는 시퀀스에 따라 변하지 않는 피처를 추출함.
Process
- 인풋 시퀀스는 K 개의 1-D convolution 필터 뱅크와 합성됨. 이때, 필터는 각각 k의 길이를 갖음(k=1,2,...,K). 이 필터들을 통해 특정 길이 k를 고려하여 정보를 추출함. 생성된 피처 벡터들은 쌓이게(stack) 되고 로컬 불변성을 증가시키기 위해 시간에 따라 max-pool 됨. 기존의 시간 해상도를 보존하기 위해 stride=1 사용함.
- 처리된 시퀀스를 몇몇의 고정 너비 1-D convolutions로 전달하여 시퀀스 벡터 사이즈와 일치하는 벡터가 생성됨. 이는 잔차 연결을 통해 기존 인풋 시퀀스와 더해짐.
- convolution 아웃풋은 highway layers에 전달되어 high-level 피처를 추출함.
- GRU(=양방향 RNN)을 쌓아 순방향/역방향 context에서 시퀀스 피처를 추출함.
3-2. Encoder
인코더의 목표는 텍스트의 견고한 시퀀스 표현을 추출하는 것임. 인코더의 인풋은 문자 시퀀스이며, 각 문자는 one-hot 벡터로 표현되고 연속 벡터로 임베딩됨. 그 후 각 임베딩에 "pre-net"이라 불리는 비선형 변환을 적용함. 이때, 수렴을 돕고 일반화를 향상시키기 위해 dropout이 있는 병목층(bottleneck layer)을 pre-net으로 사용함.
CBHG 모듈은 pre-net 아웃풋을 최종 인코더 표현으로 변환하며, 이 표현은 어텐션 모듈에서 사용됨. CBHG를 기반으로 한 이 인코더는 과적합을 줄이고, 표준 다층 RNN보다 발음 오류가 적음.
3-3. Decoder
⭐ context → STFT 바로 예측하는 것은 어려움. b/c STFT가 high-level 정보, linear 함, (위상, 크기, 주파수) 3개로 구성됨.
따라서 decoder에서는 seq2seq를 사용하여 우선적으로 3개 frame을 만들고, 이로부터 CBHG 모듈을 이용해 STFT로 만듦
Process
- t-1 시점까지 생성된 디코더의 mel-spectrogram을 인풋으로 받음. 첫 디코더 step은 모두 0이라는 frame임.
- pre-net 모듈을 거쳐 생성된 벡터를 Attention-RNN의 인풋으로 사용함.
- 인코더에서 생성된 시퀀스 벡터를 key로, Attention-RNN으로부터 추출된 시퀀스 hidden 벡터를 query로 하여 Attention 모듈을 통해 context-vector를 추출함.
- 위의 context 벡터와 Attention RNN의 시퀀스 hidden 벡터가 concatenate되어 Decoder-RNN의 인풋으로 사용됨. = “We concatenate the context vector and the attention RNN cell output to form the input to the decoder RNNs.”
- Decoder-RNN의 아웃풋은 seq2seq의 타겟인 t 시점의 80 mel-scale spectrogram임.
❓ Decoder에서 직접 linear spectrogram을 예측하지 않고 후처리를 사용하는 이유?
“While we could directly predict raw spectrogram, it’s a highly redundant representation for the purpose of learning alignment between speech signal and text. Because of this redundancy, we use a different target for seq2seq decoding and waveform synthesis.”
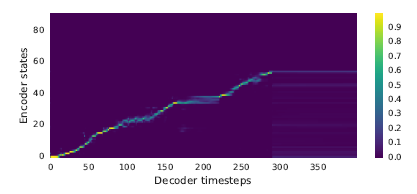
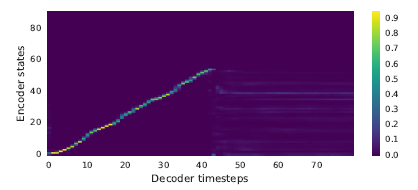
오디오로부터 추출한 mel-spectrogram은 시간에 따라 변하는 연속적인 프레임이기에 겹치는 정보가 많음(=연속 시점의 mel-spectrogram은 반복되는 프레임으로 구성될 수 있음). 본 논문에서 실험적으로 증명함. Vanila seq2seq(a)를 보면 attention이 많은 프레임에서 멈춰있는(stuck) 현상을 볼 수 있는 반면 Tacotron(b)는 깨끗한 선형의 정렬을 보임.
(a) Vanila seq2seq
(b) Tacotron
따라서 제안된 디코더는 한 step에서 r개의 mel-spectrogram을 생성함. 이 방법을 사용하면 전체 디코더 step이 r로 나눈만큼 줄어듦(=겹치지 않는 프레임을 생성할 수 있음). 후처리 과정에서는 디코더에서 생성된 전체 mel-spectrogram을 보고 linear spectrogram을 생성함. linear spectrogram은 STFT와 같은 high-level 정보에 해당함.
추론 중에는 디코더 스텝 t에서 예측의 마지막 프레임이 스텝 t+1에서 디코더에 인풋으로 공급됨. 훈련 중에는 매 r번째 ground truth 프레임을 디코더에 공급함. 인풋 프레임은 인코더와 마찬가지로 pre-net을 통해 전달됨. pre-net에서의 droupout은 모델이 아웃풋 분포의 여러 모드를 해결하기 위한 노이즈 소스를 제공하므로 일반화에 중요함.
3-4. Post-Processing and Waveform Synthesis
후처리 네트워크 작업은 seq2seq 타겟을 파형으로 합성할 수 있는 타겟으로 변환하는 것임. 후처리 네트워크의 또 다른 동기는 완전 디코딩된 시퀀스를 볼 수 있다는 것임. Seq2seq는 항상 왼쪽에서 오른쪽으로 실행되는 반면, 후처리 네트워크는 각 개별 프레임의 예측 오류를 수정하기 위해 순방향/역방향 정보를 모두 가지고 있음.
후처리 네트워크로 CBHG 모듈을 사용함. 우리는 예측된 스펙트로그램에서 파형을 합성하기 위해 Griffin-Lim 알고리즘을 사용하기 때문에 후처리 네트워크는 선형 주파수 스케일에서 샘플된 스펙트럼 크기를 예측하는 것을 학습함.
6. Discussion
본 논문은 통합된 end-to-end TTS 생성 모델인 Tacotron을 제안함. 이 모델은 문자 시퀀스를 인풋으로 받고 아웃풋은 스펙트로그램임. 간단한 파형 합성 모듈을 사용함. Tacotron은 프레임 기반이므로 추론이 샘플 수준 자기 회귀 방법보다 빠름.
✔ ref
Tacotron
