1. Introduction
기존의 음성 신호 데이터 증강은 raw waveform에서의 변형이었으나, 인풋으로 주로 log-mel 스펙트로그램을 사용하기에 이 자체를 이미지로 인식하여 변형하는 SpecAugment라는 데이터 증강 방법을 제안한다. 인풋으로 log-mel 스펙트로그램을 사용하며 추가적인 데이터가 필요 없는 간단하고 계산 비용이 저렴한 방법이다. SpecAugment는 log-mel 스펙트로그램의 세 가지 변형인 시간 왜곡, 주파수 마스킹, 시간 마스킹으로 구성된다.
2. Augmentation Policy
2-1. Augmentation 방법
log-mel 스펙트로그램에 직접 적용되는 증강 정책을 통해 네트워크가 유용한 피처를 학습하는 것을 목표로 한다. log-mel 스펙트로그램은 τ의 time step에 대한 가로축이 시간, 세로축이 주파수인 이미지다. 또한, log-mel 스펙트로그램은 정규화되어 있다(=평균값이 0). 따라서 마스크된 값을 0으로 설정하는 것은 평균값으로 설정하는 것과 같다.
❗ SpecAugment
아무것도 적용하지 않은 log-mel 스펙트로그램은 아래와 같다.
시간 왜곡(Time Warping)
시간 왜곡은 tensorflow의 sparse_image_warp을 사용한다. 이미지의 중심을 통과하는 (W,τ-W) time step 내의 무작위 가로선 상의 점이 왼쪽 혹은 오른쪽으로 왜곡된다. w는 0부터 W까지의 균일 분포에서 선택된 거리 (W : 시간 왜곡 파라미터)


주파수 마스킹(Frequency masking)
주파수 마스킹은 연속적인 mel 주파수 채널 [f0, f0 + f)이 마스킹되는 것이다. f는 0부터 F까지의 균일 분포에서 선택되고, f0는 [0, υ- f)에서 선택된다. (υ : mel 주파수 채널의 수, F : 주파수 마스크 파라미터)
시간 마스킹(Time masking)
시간 마스킹은 연속된 time step [t0, t0 + t)가 마스킹되는 것이다. t는 0부터 T까지의 균일 분포에서 선택되고, t0는 [0, τ- t)에서 선택된다. (T : 시간 마스크 파라미터) 또한, 시간 마스크의 상한을 도입하여 시간 마스크가 시간 단계의 p 배보다 넓어지지 않도록 한다.


2-2. Augment 구현
- 시간 왜곡
def time_warp(feat, W=10):
feat_size = feat.shape[1]
# 소스 및 목적지 컨트롤 포인트 생성
src = tf.Variable([[[feat_size // 2, 0]]], dtype=tf.float32) # 원래 이미지에서의 위치
dst = tf.Variable([[[feat_size // 2, W]]], dtype=tf.float32) # 왜곡된 이미지에서의 위치
# sparse_image_warp 적용
warped = tfa.image.sparse_image_warp(feat, src, dst, num_boundary_points=2)
return warped- 주파수 마스킹
def freq_masking(feat, F=10, freq_mask_num=2):
feat_size = feat.shape[1]
# freq mask
for _ in range(freq_mask_num):
f = np.random.uniform(low=0.0, high=F)
f = int(f)
f0 = random.randint(0, feat_size - f)
feat[f0: f0 + f,:] = 0
return feat- 시간 마스킹
def time_masking(feat, T=10, time_mask_num=2):
seq_len = feat.shape[0]
# time mask
for _ in range(time_mask_num):
t = np.random.uniform(low=0.0, high=T)
t = int(t)
t0 = random.randint(0, seq_len - t)
feat[:,t0: t0 + t] = 0
return feat3. Model
3-1. LAS Network Architectures
Listen, Attend and Spell (LAS) 네트워크를 사용하며, LAS-d-w라 표기한다. 인풋 log-mel 스펙트로그램은 2-layer CNN을 통과하며 맥스 풀링과 2의 stride를 갖는다. CNN의 아웃풋은 양방향 LSTM으로 쌓여있는 인코더를 통과하여 어텐션 벡터를 산출한다. 어텐션 벡터는 2-layer RNN 디코더로 공급되어 전사를 위한 토큰을 생성한다. 텍스트는 단어 조각 모델(WPM)을 사용하여 토큰화되며, LibriSpeech에는 어휘 크기가 16k이고 Switchboard에는 1k이다. LibriSpeech 960h의 WPM은 훈련셋을 사용하여 구성되고, Switchboard 300h은 훈련셋에 Fisher 코퍼스를 결합하여 구성된다.
3-2. Learning Rate Schedules
학습률 스케줄은 ASR 네트워크의 성능을 결정하는 주요 요소 중 하나이다. 데이터 증강시에도 더 긴 스케줄이 네트워크의 최종 성능을 향상시키는지 증명한 후 네트워크의 성능을 극대화하기 위해 매우 긴 스케줄을 도입한다. 학습률은 최대값의 1/100이 될 때까지 증가하다가 기하급수적으로 감소하며, 이 지점 이후로는 일정하게 유지된다. 이 스케줄은 (sr, si, sf)라는 time stamp 파라미터와 두 개의 추가적인 요소로 구성된다.
- sr : 증가 시작 지점, si : 감소 시작 지점, sf : 감소 중지 지점
- snoise : 표준 편차가 0.075인 변이 가중치 노이즈(variational weight noise)를 가하는 지점으로 훈련 중에 일정하게 유지됨. 이는 학습률의 높은 플래토에서 도입되며 (sr, si) 간격에 적용된다.
- label smooting (불확실성 = 0.1) : 정확한 클래스 레이블에는 0.9 confidence가 할당되며, 다른 레이블의 confidence도 증가한다. 이label smooting은 작은 학습률에서는 훈련을 불안정하게 만들 수 있어 때로는 훈련 시작시에만 활성화하고 학습률이 감소하기 시작하면 사용하지 않는다.
- B(asic) : (sr, snoise, si, sf) = (0.5k, 10k, 20k, 80k)
- D(ouble) : (sr, snoise, si, sf) = (1k, 20k, 40k, 160k)
- L(ong) : (sr, snoise, si, sf) = (1k, 20k, 140k, 320k), label smooting 적용
3-3. Shallow Fusion with Language Models
증강으로도 SOTA를 달성하지만, 언어 모델(LM)을 사용하면 더 큰 향상이 있다. 따라서 shallow fusion을 통해 RNN LM을 통합한다. LibriSpeech의 경우 LM에 임베딩 차원이 1024인 2층 RNN을 사용하며, 이는 LibriSpeech LM 코퍼스에서 훈련된다. Switchboard의 경우 Fisher와 Switchboard 데이터셋의 결합 트랜스크립트에서 교육된 임베딩 차원이 256인 2층 RNN을 사용한다.
4. Experiments
4-1. LibriSpeech960h
LAS-4-1024, LAS-6-1024 및 LAS-6-1280 세 개의 네트워크가 None, LB, LD 증강 정책 및 B/D의 조합으로 훈련되었다.(최대 학습률: 0.001, 배치 크기: 512, 32 Google Cloud TPU 7일) 증강 정책과 학습률 스케줄 외의 모든 하이퍼파라미터는 고정시켰다. 그 결과 증강이 훈련된 네트워크의 성능을 향상시키고 더 큰 네트워크와 더 긴 학습률의 이점이 더 강한 증강에서 명확해짐을 확인했다. 따라서 가장 큰 네트워크인 LAS-6-1280을 선택하고 스케줄 L (훈련 시간 24일) 및 정책 LD를 사용하여 성능을 극대화하도록 네트워크를 훈련했다. time step <140k인 경우 label smoothing을 적용했다. 그 결과 LM을 사용하지 않아도 SOTA를 달성했으며, 성능을 향상시키기 위해 shallow fusion을 사용하여 LM을 통합했다.
4-2. Switchboard 300h
LAS-4-1024를 None, SM, SS 증강 정책 및 B로 훈련했다.(최대 학습률: 0.001, 배치 크기: 512, 32 Google Cloud TPU) 그 결과 label smoothing(LS)을 적용하는 것이 모든 증강 정책에서 더 우수한 성능을 보였다. LAS-6-1280을 Switchboard 300h 훈련셋에서 L (훈련 시간 24일)로 훈련하여 SOTA를 달성했다. 전체 훈련 중에 label smoothing을 계속 적용하면 최종 성능에 이점이 있었다. Fisher-Switchboard에서 교육된 LM을 사용하여 shallow fusion을 적용했다. LibriSpeech의 경우와 달리 fusion 파라미터는 서로 다르게 훈련된 네트워크 간 전이가 잘 되지 않았다.
5. Discussion
- 시간 왜곡은 성능 향상에 기여하지만 주요 요소는 아니다.
아래의 표는 데이터 증강을 전부 했을 때와 각각 시간 왜곡, 시간 마스킹 및 주파수 마스킹을 제외했을 때의 결과이다. 시간 왜곡을 제외하면 test WER이 3.7에서 3.8로 는 것으로 보아 효과가 미미하다는 것을 알 수 있다. 시간 왜곡은 증강 기법 중 가장 비용이 많이 들면서도 가장 영향이 적기 때문에 예산 제약이 있다면 가장 먼저 제외되어야 한다.
- label smoothing은 훈련시 불안정성을 가져온다.
label smoothing이 증강과 함께 적용될 때 LibriSpeech의 훈련 불안정성이 증가했다. 이는 학습률이 감소될 때 잘 나타나므로 LibriSpeech를 훈련시키는 동안 레이블 스무딩을 도입했다. 이때, 학습률의 초기 단계에만 적용한다.
- 증강은 과적합을 과소적합 문제로 전환한다.
아래의 그림처럼 훈련 중인 네트워크는 증강된 훈련셋의 손실과 WER을 과소적합될 뿐만 아니라 증강된 데이터로 훈련될 때 훈련 셋 자체에도 과소적합된다. 이는 증강 훈련의 주요 이점이다.
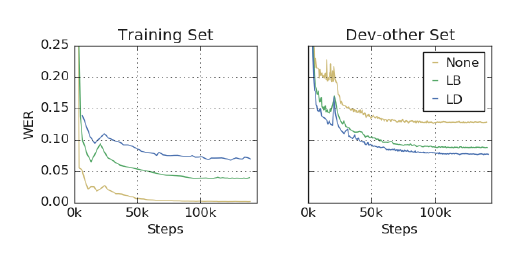
- 과소적합을 해결하려는 방법들은 성능 향상을 가져온다.
강한 증강 정책을 반복적으로 적용한 후 더 넓고 깊은 네트워크를 만들어 더 길게 훈련하여 과소적합을 해결하려 했다. 이러한 방법은 성능을 크게 향상시켰다.
6. Conclusions
SpecAugment는 ASR 네트워크의 성능을 크게 향상시킨다. 간단한 hand-crafted 정책을 사용하여 훈련 세트를 증강함으로써 end-to-end LAS 네트워크에서 LibriSpeech 960h 및 Switchboard 300h에서 SOTA를 달성했다. 이는 LM의 도움 없이도 하이브리드 시스템의 성능을 능가한다. SpecAugment는 ASR을 과적합 문제에서 과소적합 문제로 변환하며, 더 큰 네트워크를 사용하고 더 오래 훈련함으로써 성능을 향상시켰다.
✔ ref
SpecAugment
