
Session Review
What is Linear Algebra?
수학이란 인과관계를 수를 이용하여 표현하는 것 -> 세상을 이해하는데 밀접한 영향력 존재
특히, 인간의 입장에서 인과관계를 명확하게 이해할 수 있는 경우는 선형적인 관계일 때
e.g. 10min - 10km then, 20min - 20km
다시 말하자면, 선형적이지 않은 인과관계는 명확하게 설명하는 것이 어려움
수학에서는 이를 선형적인 인과관계로 이해하려고 시도:
1 input - 1 output = "함수"를 선형적으로 바꿔주는 도구 = 미분(함수를 미분하면 제약조건 하에서 선형 관계라고 가정) / 미분으로 알아낸 정보들을 합쳐주는 것 = 적분
미적분: 선형화된 정보들을 어떻게 이해하는가를 수학적으로 다루는 학문
하지만,
우리가 실생활에서 마주치는 환경은 1 input - 1 output의 단순한 것 아님
-> input, output 변수가 모두 여러개 있을 때, 이들이 모두 선형적인 관계로 얽혀있다고 가정하는 것 = 행렬(Matrix)
선형대수(Linear Algebra): 행렬을 최대한 이해하기 쉽게, 단순하게 표현하는 방법 + 행렬을 이해하는 시야를 공부하는 학문
선형대수는 비선형적인 인과관계를 선형적인 관계로 떨어뜨려 놓는 상황이나, 반대로 오히려 선형적인 정보를 추상화하는 상황 모두에서 매우 중요한 역할을 담당
🔥 데이터 사이언스와 선형대수
비선형적인 데이터의 인과관계를 선형적으로 바꾸고, 이를 이용해 계산하는 과정에서 선형대수는 필연적으로 사용됨 e.g. machine learning, deep learning
-> 많은 숫자의 배열을 시각적으로 개념화하기 좋은 방법을 제공: 데이터 속 패턴을 설명하고, 연산들에 관한 보편적 관점 제공
Data Structure
Data Structure: 데이터를 담는 구조 (feature 수에 따라 차원 달라짐)
- 1D: list
👀 데이터의 순서(order)는 유지되어야 함! - 2D: dataframe (feature 2개 이상)
👀 사람이 시각적으로 이해할 수 있는 것은 3차원이 끝 -> 그 이상은 숫자로 표현
Scalar
변수로 저장되어 있는 단일 숫자 -> 벡터 or 매트릭스에 곱해지는 경우, 해당 값에 곱한 값으로 결정됨
실수와 정수 모두 가능
Vector
n차원의 벡터는 컴포넌트라 불리는 n개의 원소를 가지는 순서를 갖는 모음
-> 컴포넌트의 개수에 따라 벡터의 차원 결정
Vector를 바라보는 시각
- 물리학자: 공간 상의 화살표
벡터: 길이와 방향으로 구성 -> 두 요소가 같다면 아무 곳에서나 여전히 같은 벡터로 취급 - 컴퓨터과학자: 숫자 자료를 배열한 것 (이 때, 순서가 중요함)
- 수학자: 어떤 것이든지 벡터가 될 수 있다 e.g. 벡터 간의 덧셈, 상수배 etc 가능
-> 벡터의 덧셈과 상수배는 선형대수학에서 중요한 역할 담당
선형대수에서의 Vector
x,y 평면 같은 좌표계에 있는 꼬리가 원점에 고정되어 있는 화살표
선형대수에서는 물리학자(화살표)와 컴퓨터과학자(배열) 관점 사이에서 중요한 부분 설명
👀 화살표의 좌표 즉, 배열은 벡터의 머리가 꼬리(원점)으로부터 얼마나 떨어져있는가를 나타냄
[x, y, z]: 하나의 배열(좌표)는 하나의 벡터(x,y,z)와 대응하고, 하나의 벡터는 하나의 배열과 대응
-> 좌표계 위 벡터의 덧셈: 삼각형법
e.g. 2*v = v의 2배 길이 (2: 스칼라(scalar) / 2*v: 스케일링(scaling))
Vector의 크기 (Magnitude, Norm, Length)
벡터의 크기 표현할 때는 |v| 와 같이 ||를 사용함 (절댓값과 그 기호가 비슷하니 주의!)
벡터의 Norm은 단순히 길이를 의미
-> 벡터가 선이기 때문에 피타고라스 정리를 통해 그 길이를 구할 수 있음
즉,
벡터의 크기: 모든 원소의 제곱을 더한 후 루트를 씌운 값
Vector의 내적 (Dot Product)
두 벡터의 내적은 각 구성요소를 곱한 뒤 합한 값과 같음
-> 교환법칙, 분배법칙 적용
👀 내적을 위해서는 두 벡터의 길이가 반드시 동일해야 함
dot_product = np.dot(x, y)Matrix
행과 열을 통해 배치되어 있는 숫자들 (벡터는 소문자, 매트릭스는 대문자로 표시)
dataframe과 유사한 형태
Dimensionality
매트릭스의 행과 열의 숫자를 차원으로 표현 (행-열 순)
2개의 매트릭스가 일치하기 위해서는
- 동일한 차원 보유
- 각 해당하는 구성요소들이 동일
해야 함
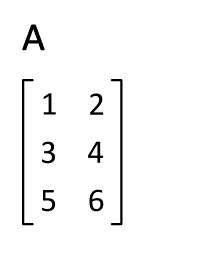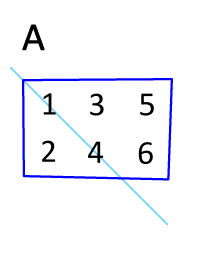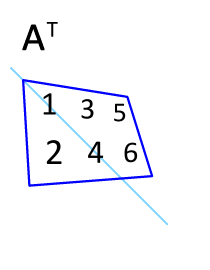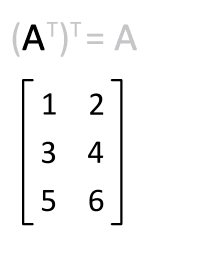
Transpose : 매트릭스의 행과 열을 바꾸는 것
-> 대각선 부분의 구성요소를 고정시키고, 이를 기준으로 나머지 구성요소를 뒤집는 것
정방 매트릭스 (Square matrix)
행과 열의 수가 동일한 매트릭스
정방 매트릭스의 특별한 케이스
- Diagonal(대각): 대각선 부분에만 값이 있고 나머지는 전부 0
- Upper Triangular(상삼각): 대각선 위쪽 부분에만 값이 있고, 나머지는 전부 0
- Lower Triangular(하삼각): upper triangular와 반대로, 대각선 아래에만 값이 있음
- Symmetric(대칭): 대각선을 기준으로 위 아래의 값이 대칭인 경우
- Identity(단위 매트릭스)
단위 매트릭스 (Identity)
1:1, 2:2 처럼 행과 열이 동일한 엘리먼트만 1이고 나머지는 0인 매트릭스
임의의 정방 매트릭스에 단위 행렬을 곱하면, 그 결과는 원본 정방 매트릭스 그 자체로 나옴
<-> 임의의 매트릭스에 곱했을 때, 단위 매트릭스가 나오게 하는 매트릭스가 역행렬(Inverse)
,
👀 매트릭스에는 나누기가 없으므로, inverse matrix를 곱하는 것으로 나누기 대신함
Matrix Calculation
대부분의 데이터는 2차원 이상으로 표현되기 때문에, 이러한 matrix 계산을 효율적으로 할 수 있도록 하는 방법들이 필요
Matrix multiplication
👀 Matrix * Matrix
행렬을 곱할 때, 가장 중요한 규칙: 앞 행렬의 열과 뒷 행렬의 행 개수가 같아야 함
why? 각 요소를 매칭해서 계산해야 하기 때문
=> n x m 행렬을 계산하려면 뒷 행렬은 m x p 여야 함
Determinant
- 3x3: 2차원 매트릭스에 대한 값을 계산 후, 수를 곱하여 더함
- 4x4: 3차원 매트릭스...
- 5x5: 4차원 매트릭스...
...
Detreminant: 행렬식
모든 정방 행렬이 갖는 속성으로, 행렬을 '스칼라 값'으로 표현하여 데이터의 특성을 이해하기 위한 방법
e.g. 2x2 매트릭스([A, B],[C, D]) 기준 행렬식: (AD - BC)
det = np.linalg.det(matrix)Inverse
역행렬: 행렬의 역수
👀 행렬 * 역행렬의 값은 항상 1(단위 매트릭스)
매트릭스에는 곱은 있지만 나눗셈은 없음 -> 그 대신에 행렬의 역행렬을 곱함
inv = np.linalg.inv(matrix)❗️ 행렬식이 0인 경우 역행렬 존재 X
행렬식이 0인 정방 매트릭스 = '특이(singular)' 매트릭스 -> 2개 행렬의 행 또는 열이 선형의 관계
즉,
매트릭스의 행과 열이 선형의 의존 관계가 있는 경우 매트릭스의 행렬식은 0이다
-> 동일한 데이터가 존재한다는 의미
e.g. 동일한 데이터인데 측정 단위만 바뀐 경우 (30cm 1개 = 15cm 2개)
Food for Thought
How to deal with errors?
성능 측정 지표를 이용하여 예측값과 실제값 간의 오차 파악
-> 아래의 성능 측정 지표들은 오차에 대해 알아봄으로써 두 값이 얼마나 비슷한지 알아보는 것을 목적으로 함
이를 통해 도출한 값이 작다는 것은 예측값과 실제값이 거의 비슷하다는 뜻 = 예측이 거의 정확했다는 것
MSE(mean squared error)
실제값과 예측값의 차이를 제곱해 평균화
특이값이 존재하면 수치가 많이 늘어남
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test(실제 측정값), y_pred(예측값))MAE(mean absolute error)
실제값과 예측값의 차이를 절대값으로 변환해 평균화
에러에 절대값을 취하기 때문에 에러의 크기가 그대로 반영됨 -> 에러에 따른 손실이 선형적으로 올라갈 때 적합 (e.g. 에러가 10 나온 상황이 5 나온 상황보다 2배 나쁜 경우)
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_test(실제 측정값), y_pred(예측값))+) 추가 참고자료
Linear Algebra functions
