SGD(경사하강법)와 모델 평가(결정계수 )
1. SGD(Stochastic Gradient Descent) 란?
경사 하강법(Gradient Descent)은 손실 함수(Loss Function)의 기울기를 구하여, 기울기가 낮은 쪽으로 계속 이동시켜 극소값(최적의 파라미터)을 찾는 알고리즘이다.
LinearRegression: 정규 방정식(OLS)을 사용해 한 번에 해를 구함 (데이터가 작을 때 유리)SGDRegressor: 기울기를 따라 조금씩 이동하며 해를 구함 (데이터가 매우 클 때, 점진적 학습이 필요할 때 유리)
예제: SGD로 자동차 제동거리 예측하기
- 기존의 LinearRegression 대신 SGDRegressor를 사용하여 모델을 학습하기
1) 데이터 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.linear_model import SGDRegressor # SGD 모델 임포트
# 시각화 폰트 설정
matplotlib.rcParams['font.family']='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] = False
# 데이터 로드
carDF = pd.read_csv('data/cars.csv', index_col='Unnamed: 0')
# 독립변수(X)와 종속변수(y) 설정
x = carDF.iloc[:, :-1]
y = carDF.iloc[:, [-1]]
# Tip: SGDRegressor에서 y는 보통 1차원 배열(Series or ravel)을 권장하지만,
# 데이터프레임 형태도 허용됨. (warning이 뜰 수 있음)2) 모델 학습 (Verbose 옵션 활용)
SGD는 반복 학습을 하므로 어떻게 학습되는지 과정을 지켜보는 것이 중요하다.
verbose=1: 학습 과정(로그)을 출력합니다.n_iter_no_change=100: 100번 반복하는 동안 성능 향상이 없으면 학습을 조기 종료(Early Stopping)
model = SGDRegressor(verbose=1, n_iter_no_change=100)
model.fit(x, y)
# --- 실행 결과 로그 (예시) ---
# -- Epoch 1
# Norm: 3.82, NNZs: 1, Bias: 0.389145, T: 50, Avg. loss: 622.827902
# Total training time: 0.00 seconds.
# ...
# -- Epoch 170
# Norm: 3.85, NNZs: 1, Bias: -12.900648, T: 8500, Avg. loss: 156.947071
# Convergence after 170 epochs took 0.00 secondsAvg. loss(평균 오차)가 점점 줄어드는 것을 확인할 수 있다.
3) 결과 확인 및 시각화
# 학습된 기울기와 절편
print("기울기(w):", model.coef_)
print("절편(b):", model.intercept_)
# 기울기(w): [3.84672995]
# 절편(b): [-12.90064768]
# 시각화
pred = model.predict(x)
plt.scatter(x, y, label='실제값')
plt.plot(x, pred, 'r--', label='SGD 예측선')
plt.legend()
plt.show()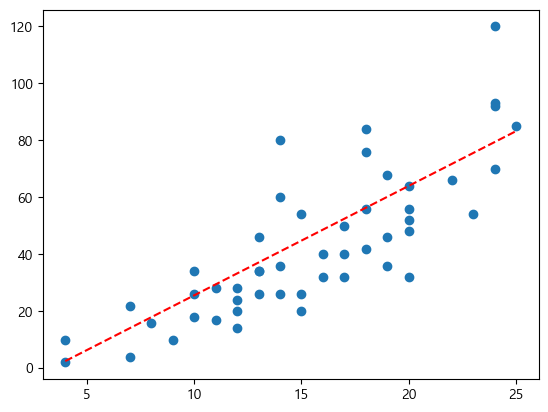
2. 결정계수 ( Score, R-squared)
- 모델을 만들었다면 "이 모델이 얼마나 정확한가?" 를 평가해야 한다. 회귀 분석에서 가장 대표적인 평가지표가 바로 결정계수()이다.
개념 정리
회귀 모델이 실제 데이터를 얼마나 잘 설명하고 있는지를 0 ~ 1 사이의 숫자로 나타냄.
- 1에 가까울수록: 모델이 데이터를 완벽하게 설명함 (좋음)
- 0에 가까울수록: 모델이 데이터의 평균 정도밖에 설명 못함 (나쁨)
- 보통 0.5 이상이면 의미가 있다고 판단하며, 0.7~0.8 이상이면 꽤 높은 성능으로 본다.
수식 이해하기 (SSE, SST, SSR)
- 결정계수를 이해하려면 분산의 분해 과정을 알아야 한다.
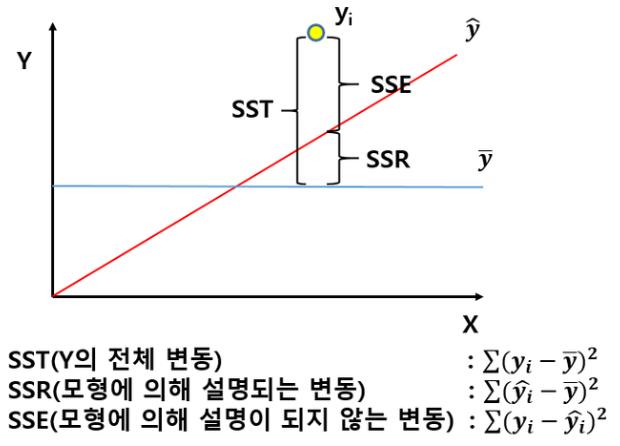
1. SST (Total Sum of Squares, 총 제곱합):
- 실제값()이 평균()으로부터 얼마나 흩어져 있는가? (데이터 자체의 분산)
2. SSE (Sum of Squared Errors, 오차 제곱합):
- 실제값()과 예측값()의 차이. 즉, 모델이 맞추지 못한 에러.
- 잔차(Residual)가 작을수록 0에 가까워짐.
3. SSR (Sum of Squares due to Regression, 회귀 제곱합):
- 예측값()이 평균()으로부터 얼마나 떨어져 있는가?
- 모델이 평균보다 얼마나 더 잘 설명했는지를 의미.
최종 공식
예시) 집값 예측
- 모델이 엉망일 때: 집값과 상관없는 평수로 예측을 한다면, 그냥 평균값으로 찍는 것이나 다름없다. 이때 오차(SSE)는 전체 분산(SST)과 같아져서 이 된다.
- 모델이 완벽할 때: 실제값과 예측값이 똑같다면 오차(SSE)가 0이 된다. 이때 이 된다.
3. Scikit-learn에서 구하기
1) r2_score 함수 사용
- sklearn.metrics 모듈을 사용. (실제값, 예측값) 순서로 넣어줌.
from sklearn.metrics import r2_score
# r2_score(y_true, y_pred)
# 주의: y는 1차원 배열 형태여야 정확합니다. y가 2차원이면 경고가 뜰 수 있음.
score = r2_score(y, pred)
print(f"결정계수: {score}")2) model.score() 메서드 사용 (추천)
- 모델 객체 자체에 내장된 함수. (입력값 X, 실제값 y)를 넣으면 알아서 예측 후 점수를 계산.
# model.score(X, y)
model_score = model.score(x, y)
print(f"모델 점수: {model_score}")
# 출력 예시
# 0.6334328883976291해석: 이 모델은 자동차 속도에 따른 제동거리 변동의 약 63.3%를 설명하고 있다.
요약
- SGD(경사하강법): 오차를 줄이는 방향으로 기울기를 조금씩 수정하며 최적값을 찾는다. (verbose=1로 과정 확인 가능)
- 결정계수(): 회귀 모델의 설명력을 나타내는 지표다. (1에 가까울수록 좋음)
- 수식:
소금에 절인 생선, 몸을 뒤척이다 🐟