Learning rate
너무 큰 learning rate를 정하면 overshooting이 생긴다. 값이 너무 커서 적절하게 학습이 되지 않는다는 것이다.
만약 너무 작은 learning rate을 정하면 너무 긴 시간이 걸리고, local minimum에서 멈추어 학습이 적절하게 되지 않는다.
learning rate을 정하는 것은 정답이 없기 때문에 여러 가지를 시도해 보는 것이 좋다. (보통 0.01로 시작한다.)
데이터가 너무 튄다면(등고선이 너무 길쭉하게 되면) 데이터를 normalize 할 필요성이 있다.
normalize of data
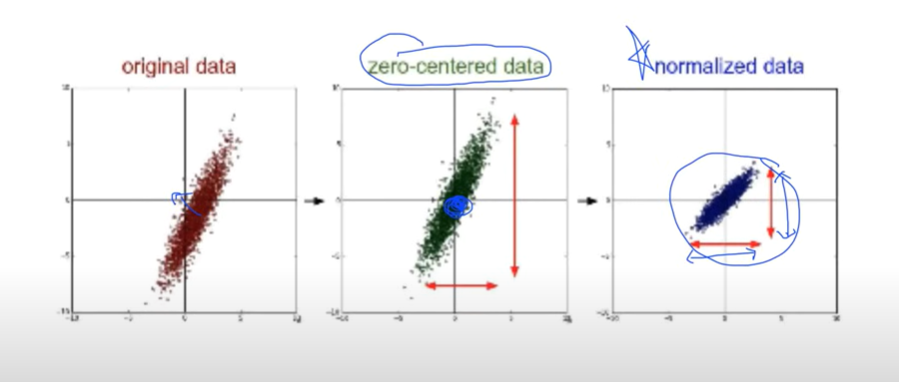
보통 이때 많이 쓰는 방법은 데이터의 중심을 zero로 만드는 zero-center 방법이 있다.
또 값의 전체의 범위가 어떤 범위 안으로 가도록 normalize 하는 방법이 있다.

여러가지 많은 방법이 있지만 그 중 위의 식은 standardization이다.
Overfitting
학습을 위한 데이터를 가지고 모델을 만들면 해당 데이터에 너무 fitting된 모델이 만들어지는 경우가 있다. 이것이 문제가 되는 이유는 만들어지는 일반적이지 않아서 그렇다. 해당 데이터셋에만 적합한, 즉 Overfitting된 모델이 된다는 것이다.
이것을 해결하는 가장 좋은 방법은 training dataset을 많이 확보하는 것이다.
아니면 가지고 있는 feature의 개수를 줄이는 방법도 있다.
세번째로는 일반화(Regularization)를 하는 것이다.
Regularization
일반화를 시킨다는 말은 함수를 구부리지 말고 피라는 의미이다. weight을 크게 하면 해당 weight에 대해 구부러지고, weight을 작게 하면 함수가 펴진다.
각각의 element를 제곱하여 더한 것이 최소가 되게 하면 된다.
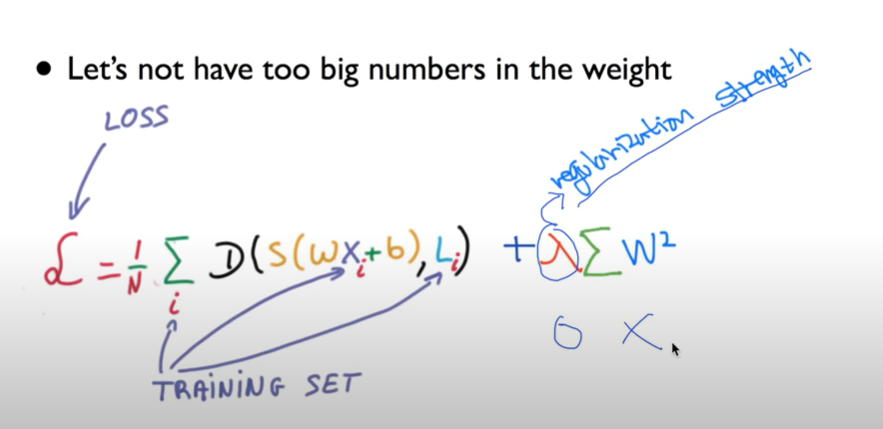
끝에 람다 식을 보자. 저 람다(상수)를 regularization strength라고 한다. 저 값이 0이 되면 regularization을 하지 않겠다는 말이다. 저 상수가 커지면 regularization을 중요시 하겠다는 말이다.
training/test dataset
우리가 시험을 볼 때랑 같이, 데이터셋은 training dataset과 test dataset으로 나누어 training 데이터를 가지고 학습한 모델을 test 데이터를 가지고 시험을 보면 된다.
Training, validation and test sets
학습을 할 때, training dataset을 또 두가지로 나눈다.
Training dataset과 Validation dataset으로 나누는 것이다.
우리가 튜닝하는 값인 알파(descent algorithm)와 람다(regularization) 값이 있다.
training 값을 가지고 모델을 학습시킨 후, validation 데이터셋을 가지고 이 두가지의 상수 값을 튜닝시킨다. 여기서 주의할 점은 Testing dataset은 반드시 한번만 볼 수 있다는 것이다.
이것을 한번에 학습시키기 힘드니까 online learning이라는 것이 있다. 이때 모델이 할 일은 학습이 지속 될수록 앞에서 학습했던 데이터의 결과를 계속해서 저장해나가는 것이다.
Accuracy
우리가 가지고 있는 test 데이터셋을 가지고 정확도를 측정해야한다. 모델을 통해 나온 정답 y^과 원래 데이터셋의 정답 레이블 y를 가지고 정확도를 측정한다.
