모두를 위한 딥러닝(시즌1-딥러닝의 기본)
1.Tensorflow의 기본

import tensorflow.compat.v1 as tf tf.disable_v2_behavior()hello = tf.constant("Hello, TensorFlow!")sess = tf.Session()print(sess.run(hello))결과: 노드들을
2.머신러닝의 개념과 용어

\-> Field of study that gives computers the ability to learn without being explicity programmed.지도 학습, training set으로 학습.label O(Most common problem t
3.Linear Regression 의 개념
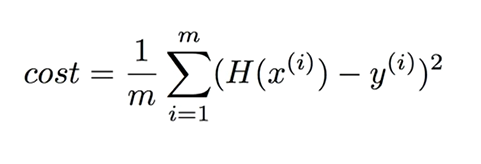
H(x) = Wx + b(Loss function)\-> 우리가 세운 가설과 실제 data가 얼마나 다른가 하는 것=> (H(x) - y)^2m: 학습 데이터의 개수Cost(W, b)의 가장 작은 값을 구하는 것이 linear regression의 학습minimize
4.Linear Regression cost함수 최소화
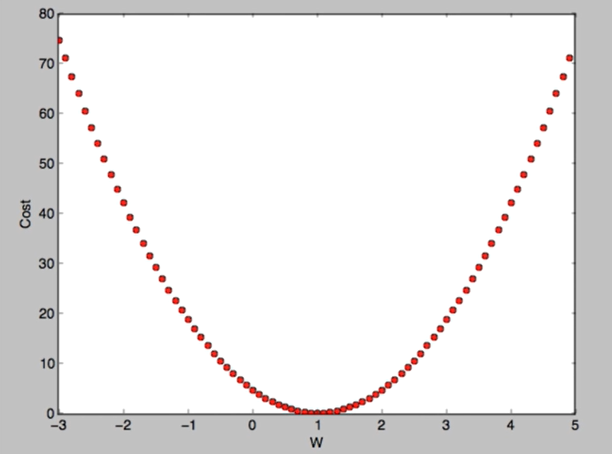
(경사 하강법)Minimize cost functionGradient descent is used many minimization problemsFor a given cost function cost(W, b), it will find W, b to minimize c
5.여러개의 입력(feature)의 Linear Regression
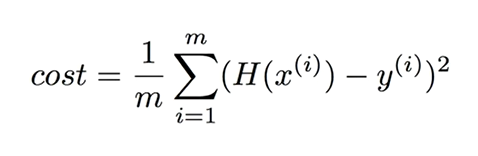
asdf
6.Logistic (Regression) Classification - Hypothesis 함수 소개
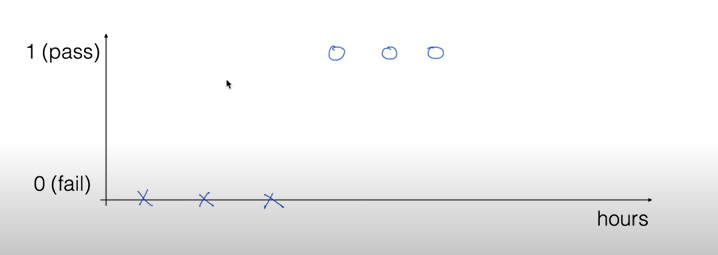
0과 1의 값(두 개의 값)으로 결과가 나뉨.그럼 이걸 linear Regression으로 만들 수 있지 않을까?이게 Binary classification이면 이렇게 linear regression으로 생각할 수 있다.근데 저렇게 해버리면 문제가 발생한다.만약에 ho
7.Softmax Regression (Multinomial Logistic Regression)
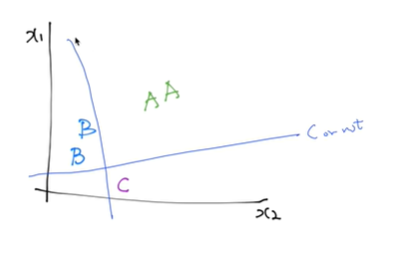
여러 개의 클래스가 있다.우리가 전에 쓰던 Binary classification을 여러 개를 합쳐서 구현이 가능하다.이런식으로 하나하나(예시: C인지 아닌지) 선을 그으면 됨.그럼 식이 이렇게 되는데 이걸 하나하나 계산하면 복잡하니까 합쳐서 행렬 벡터로 한번에 계산한
8.ML의 실용과 몇가지 팁
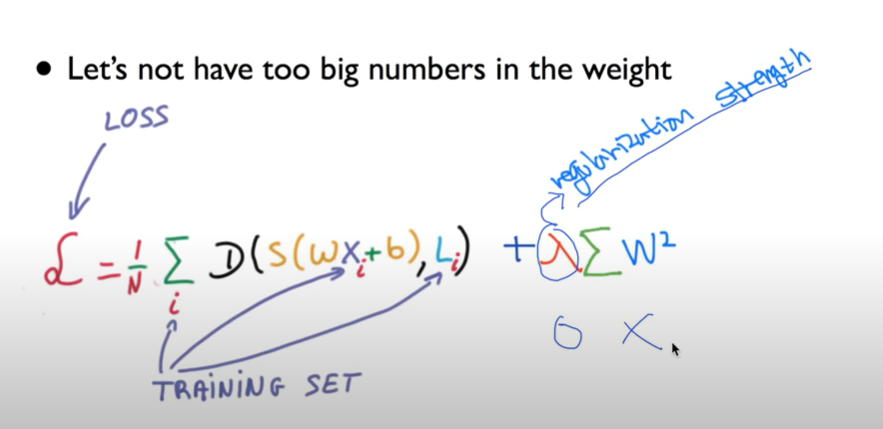
Learning rate 너무 큰 learning rate를 정하면 overshooting이 생긴다. 값이 너무 커서 적절하게 학습이 되지 않는다는 것이다. 만약 너무 작은 learning rate을 정하면 너무 긴 시간이 걸리고, local minimum에서 멈추어