k-Nearest Neighbors (k-최근접 이웃)
-
별다른 모델 없음
-
key idea: just store!!!
모든 training data를 그냥 저장 (Training) -
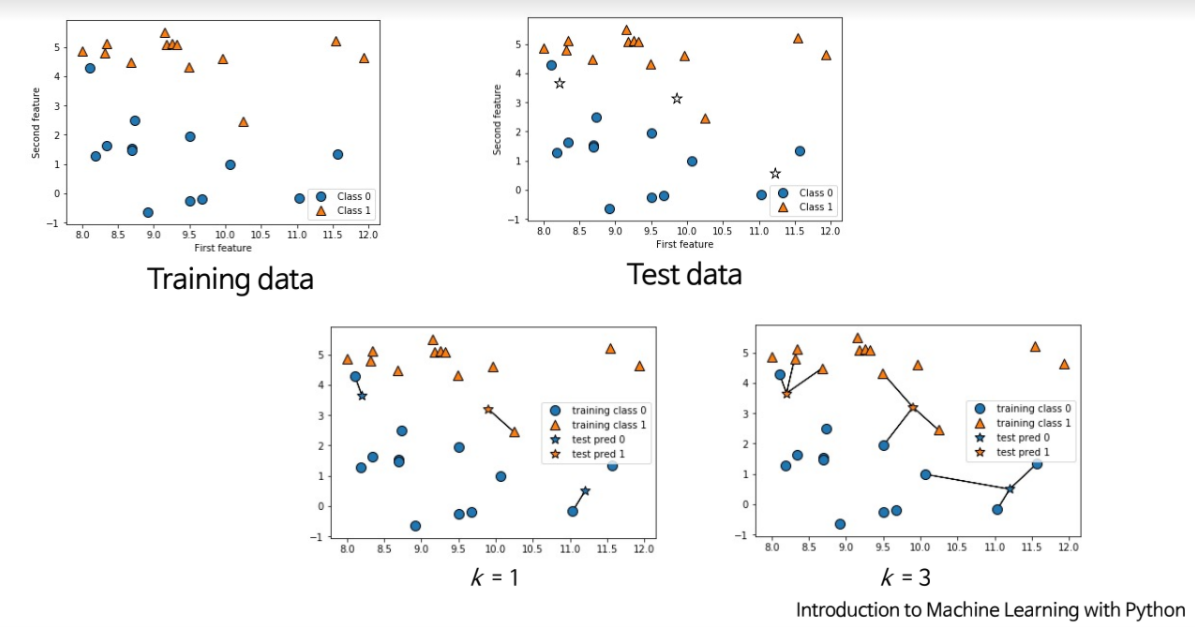
Nearest neighobr: (Test)
주어진 query instance 와 가장 가까운 training example 을 먼저 찾고, 그다음 추정 -
k-Nearest neighbor: (Test)
Given test data , take vote among its k nearest neighbors
장점
- 단순히 저장만 하기 때문에 Training이 매우 빠름!!
- 복잡한 target functions을 학습
단점
- n개의 data와 거리를 다 계산해야하기 때문에 test time이 느림
- but, 요즘은 faiss 인덱싱을 사용하면 데이터가 많아도 빠르게 찾을 수 있음
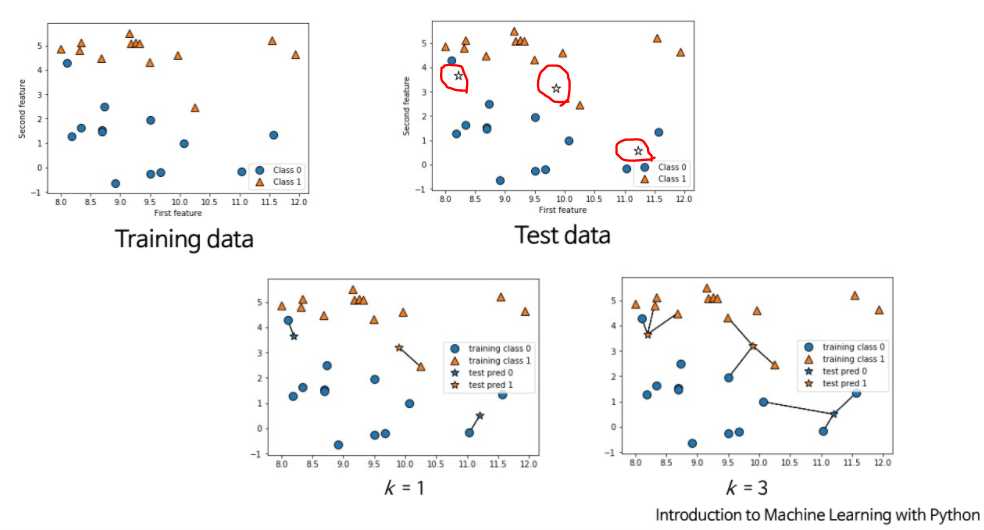
https://github.com/facebookresearch/faiss - 관련 없는 attributes에 쉽게 속음
⇒ 보통 0 ~ 1 사이의 값으로 normalization(정규화) 시켜줌 categorical data에서는 거리를 어떻게 측정? (non-euclidean data)
Distance-Weighted kNN
- 가까운 데이터를 더 고려해보자!
- 즉, 가까운 데이터에 가중치 부여
분수가 왜이렇게 쪼꼬매..
- 는 와 사이의 거리
- 는 꼭 정해져있는 건 아니며, 거리가 가까울수록 값이 큼
Hyperparameters
-
매개변수
-
In
Decision Tree, 어느 정도의 best depth를 사용하는 게 좋을까? -
In
kNN,
k의 best value 값은?
어느 정도의 best distance를 사용하는 게 좋을까? -
위의 값들이 hyperparameters!!
-
학습보다는 우리가 설정한 알고리즘에 대한 선택
Setting Hyperparameters
- data가 많으면 많을수록 좋음
📌 Idea #1

- 학습한 데이터로 test하면 절대 안됨!!!!!!!!!
📌 Idea #2

-
약
9:1로 자름 -
traindata로 model을 만들고testdata로 테스트 -
testdata로 hyperparameter 판단하면 절대 안됨!!!!!!
📌 Idea #3

-
약
8:1:1로 자름 -
먼저
train데이터로 학습한 후validation데이터, 즉 검증 데이터로 매개변수를 정하고,test데이터로 최종 테스트
Cross-Validation
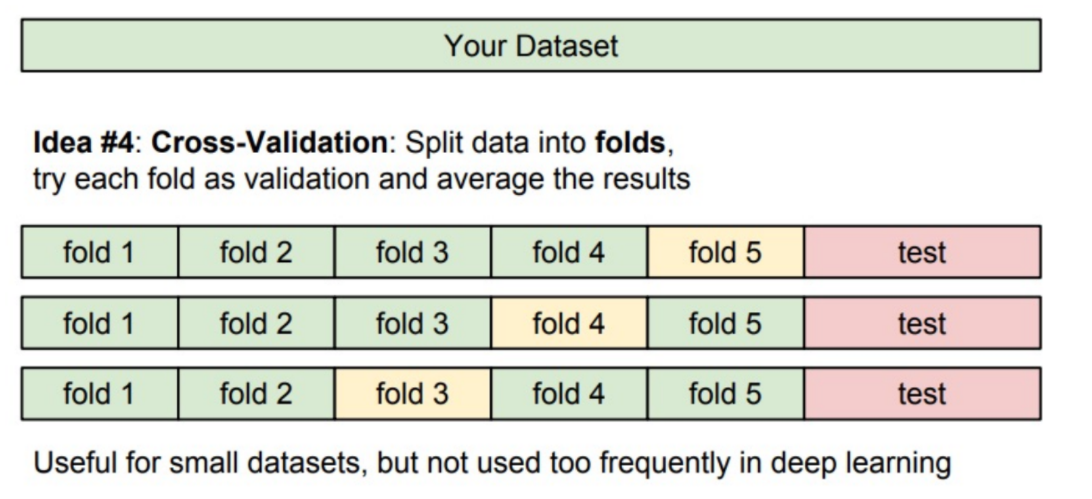
-
교차 검증, data가 작을 때 자주 사용하는 방식
-
딥러닝에서는 학습 시간이 오래 걸려서 잘 쓰이지 않음
-
test데이터는 무조건 남겨둬야 함!!! model 만들 때 건들면 안되는 data -
위의 예시는
5-fold cross-validation -
test data를 그 누구도 잘 알 수 있게 뽑은 게 아니냐는 지적이 있을 수 있기 때문에, test data 자체도 cross-validation 할 수 있음
-
(+ 평균)(± 분산)
