rag에 대해 공부를 하고 있다. 그중 가장 중요하다고 생각이 들었던, 개념과 특징을 명확히 짚고 넘어가야 할듯한 RRF & rerank & pro-retrieval/post-retrieval에 대해 최종적으로 정리해보자.
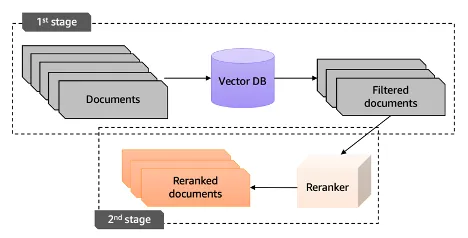
rag 과정 순서도
사용자 질문 → 임베딩 → 벡터 검색 (✅ hybrid search) → ✅ 리랭킹 → 상위 N개 문맥 선택 → LLM 답변 생성cross encoder 예시 (rerank)
Input: "Query: 9월 전력 사용량은? Context: 9월 최대 전력은 93.2GW였습니다."
Output: 관련성 점수 (e.g. 0.87)
# ❗ dense retriever와 달리, **문서와 질문을 함께 한 input으로 LLM에 넣어 점수를 예측**✅ 왜 벡터 검색 후에 쓰는가?
- Cross-Encoder는 모든 문서 쌍에 대해 비교하면 느리기 때문에,
- 먼저 Milvus나 FAISS 등으로 top_k 문서를 빠르게 필터링하고,
- 이후에 소수의 후보(보통 10~20개)에 대해서만 정밀하게 평가하는 방식
- 먼저 Milvus나 FAISS 등으로 top_k 문서를 빠르게 필터링하고,
📖 Hybrid Search
🔎 키워드 기반 검색 Lexical Search: BM25 같은 sparse 벡터 알고리즘 통해 키워드 기반 매칭
- 특정 도메인 용어 검색 용이 but 오타/동의어 취약
🔎 유사도 기반 검색 Semantic Search: 의미론적으로 유사한 검색 결과 반환
- 임베딩 품질에 의존도 높다
→ Hybrid Search는 각 검색 방법의 장점만을 추려 사용
👓 어떻게 두 검색 결과를 결합하나?
- CC (Convex Combination): LS와 SS 각각 문서 score에 가중치 부여해 취합
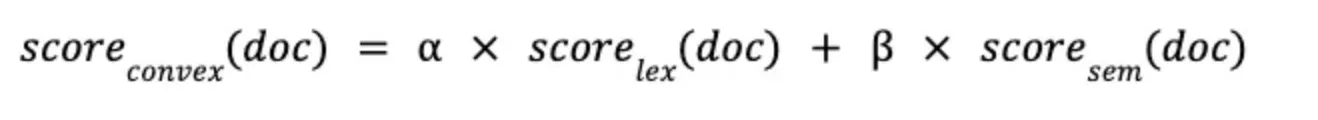
- RRF (Reciprocal Rank Fusion): 순위가 매겨진 문서 반환 & 취합 시 순위 높은 문서에 점수 ↟
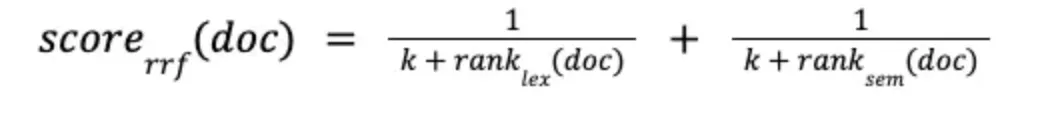
👓 어떻게 구현하나?
- LangChain의
EnsembleRetriever→ 각기 다른 쿼리 응답의 조합 위해 RRF 채택
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import OpenSearchVectorSearch
...
# Ensemble Retriever(앙상블 검색)
ensemble_retriever = EnsembleRetriever(
retrievers=[opensearch_lexical_retriever, opensearch_semantic_retriever],
weights=[0.50, 0.50]
)
search_hybrid_result = ensemble_retriever.get_relevant_documents(query)
# 실제 LLM을 호출할 때 context로 EnsembleRetriever의 결과인 search_hybrid_result를 전달하면 Hybrid Search를 수행할 수 있다.- 라마인덱스의
HybridRetriever←BM25Retriever+EmbeddingRetriever-
텍스트의 빈도와 관련성을 기준으로 순위를 매기는 BM25 (전통적 키워드 검색에 적합)
-
문서와 검색어를 임베딩 벡터로 변환하여 유사도 기반 문서 간의 의미적 연관성을 찾아줌 (벡터 기반 검색 적합 - 시멘틱 검색 처리)
→ 키워드 검색과 시멘틱 검색을 동시에 수행한 후, 두 결과를 결합하여 사용자에게 반환 (키워드와 의미적 유사성 동시에 고려) + 검색 결과의 가중치 조정, 특정 방식에 더 비중 ↑ 둘 수 있다
-
📖 Rerank
🔎 질의 Query: 사용자가 “문장”을 작성해 검색을 한다
- 검색 프로세스는 질의와 사전에 등록된 데이터를 비교하여 가장 유사한 데이터 제공
- 질의와 데이터(문서/청크 etc)를 연산이 가능한 벡터로 변환 + 코사인 유사도나 BM25를 이용한 hybrid search 방법론을 적용해 → 질의와 가장 유사한 데이터가 무엇인지 알아냄
🔎 RAG: Hallucination을 최소화하기 위해 최신 정보를 검색하고 이를 생성 단계에서 사용
- 논문 → RAG의 정확도는 관련 정보의 컨텍스트 내 정보 유무가 아니라, 순서이다! → 관련 정보가 컨텍스트 내 상위권에 위치할 때 좋은 답변을 얻을 수 있다
- 많은 정보를 LLM에 넘겨준다고 한들, 생성이 더 좋다는 보장은 없다
- LLM에 넘겨야 하는 정보의 길이 제한 + 비용 + 핵심 정보가 애매하게 위치하면 성능 ↓
- LLM이 더 좋은 답변을 만들기 위해서는 우리가 제공해야 하는 정보의 순서가 중요하다!
⇒ 이렇게 정보의 순서를 조정하는 단계를 rerank
- rerank를 위한 모델 reranker를 사용하여 최종적으로 질의에 대해 가장 의미있는 내용을 담고 있는 문서를 보다 상위로 올리는 것을 목표로 한다.
- 검색에서 한차례 선별된 정보 리스트에서 상위 k개 문서에 한정해 순위 재조정
- 유사도를 이용한 검색은 전체 문서에 대해 빠르게 결과를 얻을 수 O
- rerank는 질의와 문서 사이의 의미론적 유사성을 탐색 → 그보다 오래 걸린다 → 검색을 통해서 추출된 상위 문서에 한해서만 수행
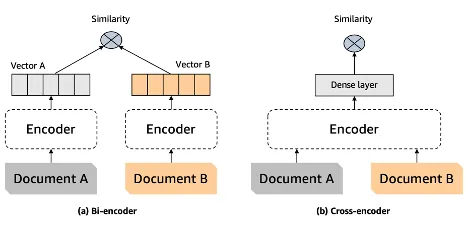
기존 벡터 검색을 위해 사용하는 구조가 Bi-encoder ↔ rerank를 위한 구조는 Cross-encoder
- Bi-encoder: 질의와 정보를 각각 임베딩한 후 유사도 계산
- Cross-encoder: 질의와 정보를 입력으로 사용해 유사도 출력 → 질의와 정보의 내용을 한번에 고려 ⇒ 더욱 정확한 유사도!
한국어 reranker: https://huggingface.co/Dongjin-kr/ko-reranker
model_path = "Dongjin-kr/ko-reranker"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
model.eval()
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
scores = exp_normalize(scores.numpy())
print(np.round(scores * 100, 2))다국어 reranker: https://huggingface.co/BAAI/bge-reranker-v2-m3
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-m3')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-v2-m3')
model.eval()
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
scores = exp_normalize(scores.numpy())
print(np.round(scores * 100, 2))🔔 Reranking step
Improve Retrieval Augmented Generation (RAG) with Re-ranking
The concern here is that by only considering the top_k responses, we might miss out on valuable context that could improve the accuracy of the LLM’s responses.
This limitation highlights the need for a more robust approach to selecting and providing context to the LLM, ensuring that it has access to the most relevant information to generate accurate responses.
However, during the conversion of documents into vectors, there’s potential for information loss as vectors represent content in a compressed numerical format.
Additionally, larger documents often need to be divided into smaller chunks for embedding into vector format, making it challenging to maintain the context across all the smaller parts.
🔎 The reason why we can’t simply send all search results from vector search to the LLM is twofold:
- LLM Context Limitation: LLMs have constraints on how much text can be passed to them, known as the “context window.”
- LLM Recall Performance: LLM recall refers to the ability of the model to retrieve information from the given context.
🔎 As part of refining RAG implementation, one crucial step is re-ranking.
A re-ranking model is a type of model that calculates a matching score for a given query and document pair.
- This score can then be utilized to rearrange vector search results,
- ensuring that the most relevant results are prioritized at the top of the list.
👉 In summary, the initial step involves retrieving relevant documents from a large dataset using vector search due to its speed.
Once these related documents are obtained, re-ranking is applied to prioritize the most relevant ones at the top.
These top-ranked documents, which align closely with the user’s query, are then passed to the LLM to enhance the accuracy and precision of results.
📖 Pre-Retrieval & Post-Retrieval
[우아한 스터디] RAG 성능을 끌어올리는 Pre-Retrieval (Ensenble Retriever) 와 Post-Retrieval (Re-Rank)
🔎 Pre-retrieval (Ensemble Retriever)
: 여러 retriever를 입력으로 받아 → get_relevant_documents() 메서드 결과를 앙상블 → RRF 기반 결과 재순위화
- Sparse Retriever: 키워드 기반 관련 문서 탐색 효과적
- TF-IDF, BM25 → 텍스트 데이터를 희소 벡터로 변환 → 질의 벡터와의 유사성 따라 검색
- Dense Retriever: 의미적 유사성 기반 문서 탐색 효과적
- BERT 신경망 모델 → 텍스트 데이터를 밀집 임베딩 벡터로 변환 → 질의 벡터와의 유사성 따라 검색
- 두 Retriever를 결합하여 각 방식의 장점을 활용한 Ensemble Retriever → 검색 효율성
# BM25 리트리버 생성 (Sparse Retriever)
bm25_retriever = BM25Retriever.from_documents(docs)
# FAISS 리트리버 생성 (Dense Retriever)
faiss_retriever = vectorstore_faiss.as_retriever(search_kwargs={'k': 5})
# 앙상블 리트리버 생성
self.retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5] # 가중치 설정 (가중치의 합은 1.0) 🔎 Post-Retrieval
- 최근 RAG에는 Lost in the Middle 문제 → 질문 관련 문서가 컨텍스트 중간에 위치할 경우, LLM 응답 정확도 ↓
- RAG 성능 향상을 위해서는 질문 관련 문서가 컨텍스트에 존재 & 컨텍스트 내에서 상위권
- 이에 대한 해결책이 Reranker
- Reranker는 질문과 문서 사이의 유사도를 측정하는 것이 목표 = 기존 벡터 검색 목적
- but 질문과 문서에 대한 독립적 임베딩 활용하는 Bi-Encoder와 달리,
- Reranker는 질문과 문서를 하나의 input으로 활용하는 Cross-Encoder 형태
- 질문과 문서를 동시에 분석 (Self-attention) → 더욱 정확한 유사도 측정 ⇒ 질문-문서 사이 관련성 더욱 정교하게 측정
🔔 Hybrid Search & Reranking
[RAG 시리즈] Hybrid Search 와 재순위화 알고리즘 (RRF 를 곁들인..)
🔎 Hybrid Search는 왜 등장하였는가?
- LLM은 특정 시간에 학습을 멈추고 배포된다 → 실시간 데이터와 일치 X 경우 ↑
- 또한, 모든 데이터를 학습시킬 수 X → 사실과는 다른 답변 내놓는 경우 ↑
→ 이러한 문제를 해결하기 위해, LLM에 질문과 유사도가 높은 context를 답변 생성 전에 전달하여 → 보다 높은 정확도의 답변을 반환하도록 하는 RAG 기술 대두
- 하지만, 이런 유사도 기반 검색조차 단어 임베딩 품질에 따라 답변의 정확도가 떨어졌으며, production level에서 일반 RAG 사용하기는 부족함 O
⇒ 이를 해결하기 위해 유사도에 더해, 키워드 기반 검색을 함께 활용하는 Hybrid Search 기술 생김.
🔎 Hybrid Search란?
= 키워드 기반 검색 Lexical Search + 유사도 기반 검색 Semantic Search
- Lexical Search: BM25와 같은 sparse 벡터 알고리즘 → 키워드 기반 매칭
- Semantic Search: 의미론적으로 유사한 결과 반환 ← 임베딩 품질에 의존도 ↑
🔎 EnsembleRetriever란?
= 여러 retriever를 입력으로 받아 검색 결과 앙상블 & RRF 기반 결과 재순위화
- 가장 일반적인 패턴은 → sparse retriever(예:BM25)와 dense retriever(예:embedding similarity)를 결합 ← 이는 두 retriever의 장점이 상호 보완적이기 때문, hybrid search라고도 한다.
- sparse retriever는 키워드 기반으로 관련 문서 탐색 효과적
- dense retriever는 의미적 유사성 기반으로 관련 문서 탐색 효과적
🔎 Ensemble Retriever를 활용하지 못하는 경우
→ Lexical search 결과와 Semantic search 결과 결합 위해 재순위화 알고리즘 사용
https://github.com/Judy-Choi/rag_series/blob/main/note_4/main.ipynb
기본적으로 Hybrid Retrieval에는 RRF와 CC 방법이 있다.
- RRF: 서로 다른 관련성 지표를 가진 여러 개의 결과 집합 → 하나의 결과 집합으로 결합 (=rank 사용) , 튜닝 필요 X, 서로 다른 관련성 지표들이 상호 관련되지 않아도 고품질 결과 O

🔔 Reranker
한국어 Reranker를 활용한 검색 증강 생성(RAG) 성능 올리기 | Amazon Web Services
🔎 Reranking은 RAG가 생성한 후보 문서들에 대해 질문에 대한 관련성 및 일관성을 판단하여 문서의 우선순위를 재정렬하는 것
→ 질문과 관련성 있는 문서들을 컨텍스트의 상위권에 위치시킴 ⇒ 답변의 정확도 ↑
- 문제 정의
- RAG는 수많은 텍스트 문서에서 의미론적 검색(Semantic Search) 수행
- 일반적으로 벡터 검색 활용 → 두 가지 정보 손실
- 문서의 임베딩 벡터 변환 과정에서의 손실: 문서가 긴 경우에 정해진 벡터의 차원으로 표현하기 어려운 상황
- 검색 과정에서의 손실: RAG는 건색 시간 단축 위해 ANNs(Approxiate Nearest Neighbor search) 활용 → 질문과 문서 사이의 관련성 체크 횟수 ↓ → 검색속도 ↑ → 이 과정에서 발생하는 관련성 정확도 하락이 정보의 손실로 나타남 ⇒ LLM으로 전달되는 컨텍스트의 상위 k개 이내에서 질문 관련 정보 누락 발생
- 일반적으로 벡터 검색 활용 → 두 가지 정보 손실
- 해결 전략
- RAG의 성능을 향상시키기 위해서는 질문에 대한 관련 문서가 컨텍스트에 존재할 뿐만 아니라, 컨텍스트 내에서 그 순서 또한 상위권에 위치하고 있어야 한다. → 해결책 - Reranker
- Reranker: 질문과 문서 사이의 유사도 측정이 목표 → 질문과 문서를 하나의 input으로 활용하는 Cross-encoder 형태 ⇒ 질문과 문서를 동시에 분석 (self-attention) → 독립적인 임베딩 벡터 기반의 Bi-encoder 방식에 비해 더욱 정확한 유사도 측정 가능
- 첫번째 단계에서는 기존의 벡터 검색 방식으로 대규모 문서 중 질문과 관련성 높은 후보군 검색
- 두번째 단계에서는 검색된 문서들에 대해 reranker 기반으로 관련성 재측정