Rich feature hierarchies for accurate object detection and semantic segmentation, RCNN
Paper_Review_object_detection
https://arxiv.org/abs/1311.2524
RCNN은 Object detection 분야에서 convolution 구조를 이용한 model로 현재는 여러가지의 이유로 잘 쓰이지 않습니다. 하지만 object detection분야의 R-CNN계열의 논문들의 가장 기초가 되는 논문인 만큼 처음부터 공부하고자 합니다.
0. Overall architecture
전체 구조는 다음과 같습니다
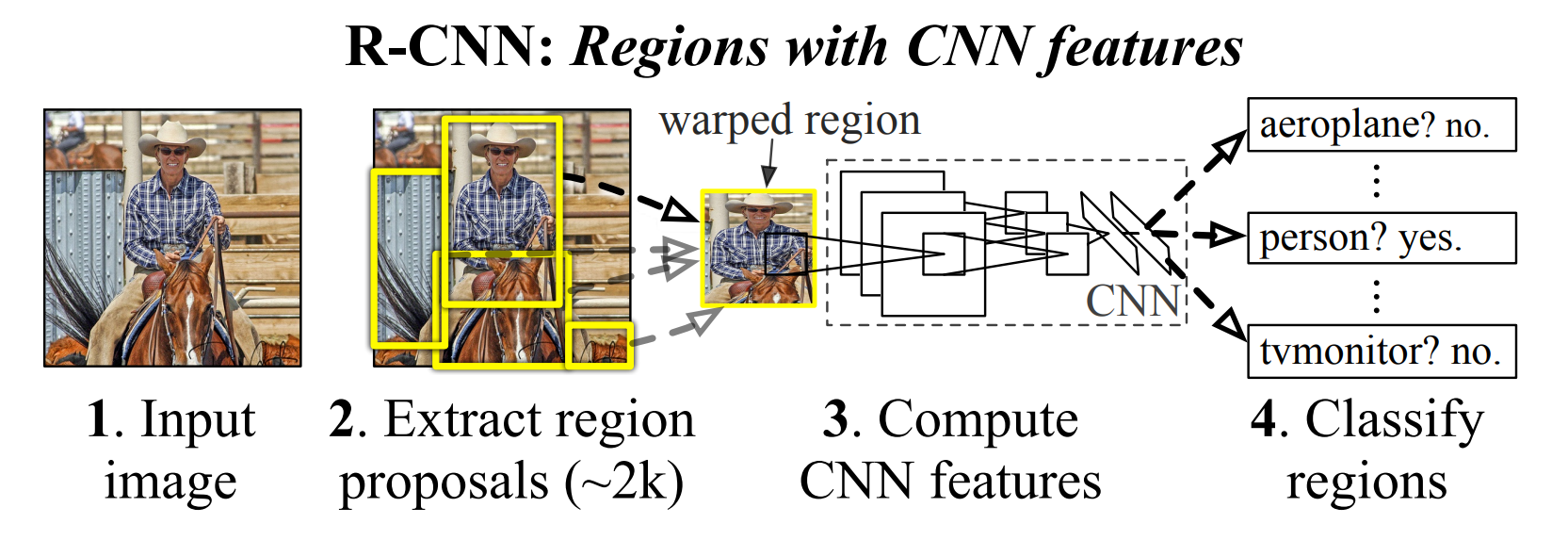
크게 4가지로 분류하여 볼 수 있습니다.
1. Using selective search algorithm, propose regions
selective search라는 알고리즘을 이용하여 input image에서 물체가 있을법한 위치를 찾습니다.
2. Computing CNN, extract 4096-dimensional feature vectors
물체가 있을법한 위치를 Conv에 넣어 4,096차원의 vector로 축소 합니다.
3. Linear SVM classifier
축소된 4,096차원의 vector를 이용하여 물체의 class를 구분하는 classifier를 만듭니다.
4. Bounding box regression
축소된 4,096차원의 vector를 다시 이용하여 1에서 진행한 bounb box를 수정합니다.
1. selective search algorithm
물체가 있을법한 bounb box를 만들어 주는 알고리즘으로 아래 논문에서 제시되어 잇고 자세한 설명이 나와있습니다.
http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
이는 딥러닝의 기법이 들어가 있다고 보기에는 어려우며 단순히 image에 대해서 color, texture, size, fill을 이용하여 비슷한 즉, 물체인거 같은 곳을 묶는 algorithm입니다. 따라서 자세하게 다루지는 않습니다.
Peudo-Code는 아래와 같습니다.

의사 코드를 보면 을 기준으로 구역을 합치는 것을 볼 수 있습니다.
특히 이는 위에서 언급했던 4가지의 선형결합으로 R-CNN 논문에서는 가중치를 모두 적용하였습니다.
각각의 요소는 다음과 같이 계산된다.
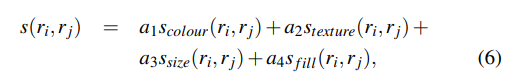
- color
특히 이는 아래의 사진을 보면 직관적으로 이해할 수 있습니다.
https://donghwa-kim.github.io/SelectiveSearch.html

- texture

- size

- fill

이 그림이 algorithm을 통해 bnd를 찾는 그림이다
왼쪽 부터 오른쪽을 갈 수록 더욱 적은 수의 bnd를 만들기 위해 합집합을 진행합니다.
이렇게 하여 한장의 image당 총 2,000개의 bnd를 만들고 이를 227×227으로 resize합니다.
위의 pseudo code에서 까지 반복하면 되는것 같습니다.

2. CNN
seletive search를 통하여 한장의 image당 2,000장의 RoI를 생성하였습니다.
이후 2,000장의 cropped image를 모두 227 size로 resize (논문에서는 warp) 합니다. 이부분이 헷갈리는 경우가 있는데 본 논문에서는 Conv로 AlexNet을 사용하였습니다. 찾아보면 AlexNet논문에서 Input image size에 대한 논의가 많습니다. 이유는 해당 논문에 Input image size를 227인지 224인지 상당히 헷갈리게 작성되었기 때문입니다. 특히 AleeNet 논문에 삽입된 그림이 224로 되어 있어서 그랬던 것으로 기억하는데 사실 이부분이 typo이고 227이 맞습니다.
다시 말하자면 한장의 iamge에 대해 RoI 2,000장을 생성하고 이를 모두 Conv에 통과시켜 4,096차원의 vector를 얻습니다. 일반적인 classification 모델 같은 경우 마지막에 FC-layer를 통한 loss 를 계산 한 후 FC-layer 즉 classifier와 Conv의 parameter가 동시에 학습 됩니다. 하지만 R-CNN의 경우 softmax기반으 classifier가 아닌 Linear SVM을 사용하므로 feature vector를 추줄하는 Conv와 Claaification을 진행하는 SVM이 동시에 학습될 수 없습니다. 따라서 어쩔 수 없이 아래와 같은 학습 과정을 거칩니다.
https://blog.naver.com/laonple/220731472214
위 그림이 Conv의 training과정을 가장 잘 설명한다고 봅니다.
학습과정은 아래와 같습니다.
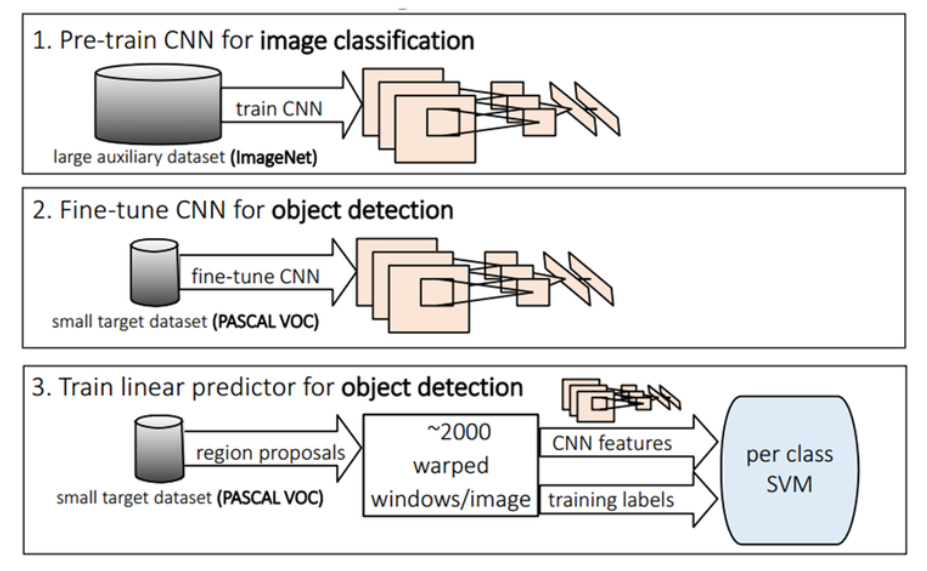
- ILSVRC2012 classification dataset으로 classification model을 만들어 pre-train을 진행합니다.
- PASCAL VOC dataset를 selective search를 통과시킨 후의 cropped image들을 Input image로 하여 fine-tuning을 진행합니다.
- 특히 이부분은 첫번째와 다른점이 있습니다.
첫번째는 classification dataset입니다. 즉, 한장의 iamge에 대핸 target이 하나 존재합니다. 하지만 두번째의 경우에는 object detection dataset입니다. 즉, 여러개의 class가 존재하며 selective search에 의해 추천된 region이 무조건 object를 포함한다고 할 수 없으며 실제로는 전혀 그렇하지 않습니다. 따라서 원래의 target class가 N개였다면 이 과정에서는 N+1로 바꿉니다. 이때 +1은 배경을 의미합니다. 다음과 같은 그림을 보면 이해가 쉬울겁니다.
selective search를 이용한 boun box가 1,2,3개 있다고 하면 1번은 나무, 2번은 사람 3번은 아무것도 아니게 됩니다. 이때는 ground truth data를 이용하여 각각의 BND에 대한 IoU를 계산합니다. IoU가 0.5 이상미면 이를 positive box라고 하며 0.5미만이면 이는 negative box라고 합니다. 즉, 순서대로 물체가 있는 bnd와 배경인 bnd라고 생각하면 됩니다. 이후에는 이렇게 label이 붙은 bnd를 32개의 positive와 96개의 background를 하나의 mini-batch로 만듭니다. 이렇게 만든 batch를 가지고 학습을 진행하면 됩니다.
추가로 구현을 하진 않을거지만 이부분을 코드상에서 본다면 positive에 대한 target은 ground truth의 것을, background에 대한 target은 background라고 하면 될것 같습니다- 이부분에서는 Conv에 대한 학습이 일어나지는 않습니다. Conv에서 추출된 feature를 통하여 SVM을 학습합니다. 자세한 내용은 아래에서 따로 다룹니다.
이때 각각의 의미는 다음과 같습니다.
1의 과정에서는 image에 대한 feature를 어떻게 뽑으질에 대한 전반적인 내용을 학습합니다.
2의 과정에서는 selective search를 거친 dataset을 이용하여 object detection dataset에 특화된 dataset에 대한 feature추출을 학습합니다. 이는 1에서 학습된 parameter를 fine-tuning하는 과정이라고 생각하면 됩니다.
이렇게 1,2의 과정을 거치면 Conv는 비로써 Image에 대한 feature를 추출하는 것으로 학습된 것입니다.
이후 3의 과정을 통하여 Conv에서 output으로 나오는 feature를 이용한 classifier를 학습하게 됩니다.
이렇게 Conv를 학습하게 되면 이제 Conv는 object detection Input Image에 대한 feature를 뽑아 낼 수 있게 학습이 된것입니다.
단 여기서 주의할 점은 1,2과정은 모두 softmax기반의 classifier를 사용하였고 3의 과정을 위해서는 이부분을 제거해야 합니다.
3. SVM
이부분이 Conv를 통과한 feature vector를 가지고 classification을 진행하는 부분입니다. 이건 사실 딥러닝이 아니므로 다루지 않습니다. 다만 중요한 사실 몇가지만 짚고 넘어가겠습니다. 우선 CNN의 두번째 과정에서 IoU를 0.5를 기준으로 fine-tuning하였이만 여기에서는 0.3을 기준으로 합니다. 그냥 이렇게 하는게 더 잘되었다고 합니다. 또한 총 N+1개의 SVM을 독립적으로 만들어 진행합니다.
단순히 Conv의 output인 4,096-d vector를 이용한 classifier라고 생각하면 됩니다.
또한 score한다는 문장이 이후의 논문에서도 꽤 나오던데 이부분은 다음과 같이 받아들이면 됩니다.
Seleteive serach를 통하여 cropped된 iamge를 각 class가 될 점수가 Conv를 거친 feature를 이용한 SVM의 output으로 나온다 입니다.
4. Bounding Box Regression
앞에서 SVM은 Conv의 output인 4,096-d vector를 input을 받는다고 하였습니다. 여기에서도 같은 vector를 input으로 받게 됩니다.
selective search algorithm을 이용한 region proposal은 사실 머신러닝의 개념이 들어가지 않습니다. 따라서 정확하지 않고 이를 개선하기 위해 CNN을 거쳐 나온 feature vector를 이용하여 BND를 수정하는 과정을 거친는 것입니다.
우선 논문의 식을 보겠습니다.
뭔가 처음보는 식입니다. 정리해 보겠습니다.
참고 https://yeomko.tistory.com/13
이와같이 regression을 진행합니다.
추가로 P는 모두 사용하는 것이 아니라 nearness방식을 사용했다고 하는데 이는 G와 IoU가 가장 높은 P를 regression하는 방식입니다.
다만, 마지막의 해를 찾는 부분이 애매하고 loss function에 대해 다시 볼 필요가 있다고 느껴서 이부부은 다시 정리하고자 합니다.





5. Non-Maximum Suppression

위 사진과 같이 여러개의 bnd가 있을 수 있습니다. 따라서 이들 중 IoU를 기준으로 가장 높은 bnd를 제외하고는 삭제해야 합니다.

6. Drawbacks
- 엄청 느립니다.
한장의 이미지에서 2,000장의 RoI를 추출하여 모두 Conv 연산을 수행하는 것으로 엄청난 연산량을 요구합니다 - 복잡합니다
학습이 일어나는 부분이 Conv, SVM, Regression 세가지가 있으며 이는 서로 share 즉, 한번에 학습되지 못합니다. - End-to-end가 아닙니다.
즉, 2에서 언급한 세개의 학습되는 parameter가 한번에 학습 될 수 없고 각각 다른 과정에서 학습이 되므로 정확성이 효율적이지 못합니다. 즉, SVM을 classifier로써 학습할 때 conv의 parameter가 update되지 못합니다.
.png)