Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, SPPNet
Paper_Review_object_detection
https://arxiv.org/abs/1406.4729
- 본 논문에서 사용한 selective search는 fast mode입니다.
0. RCNN에서의 warp
RCNN에서는 selective search algorithm을 통과한 후 warp(resize)를 거쳐서 CNN에 들어 가기전 227×227의 size로 고정해주어야 했습니다.
엄밀히 말하면 convolution은 같은 size의 image가 들어갈 필요는 없습니다.
대표적인 예로 segmenation model인 FCN에서 이를 확인할 수 있습니다. input image의 size에 따라 output feature map의 size는 달라 지지만 convolution의 parameter는 달라질 이유가 없습니다. 하지만 RCNN에서의 CNN architecture는 마지막에 classifier로 FC-layer를 사용하기 때문에 고정된 size의 vector를 만들려고 CNN 이전에 resize를 합니다.
이렇게 고정된 size로 output을 내기위해 resize를 하면 당연히 정보의 손실 또는 왜곡이 일어납니다. 또한 NLP의 seq-to-seq model에서도 encoder에서 decoder로 넘겨줄때 고정된 크기의 벡터는 상당한 문제였습니다.
이를 보완하는 동시에 RCNN에서 가장 큰 문제였던 소요시간을 줄이기 위해 본 논문에서는
Spatial Pyramid Pooling을 이용하여 CNN이전에 고정된 크기로 맞추어 주는 작업을 필요 없게 하였다.
1. Overal architecture
우선 대략적인 구조는 다음과 같습니다.
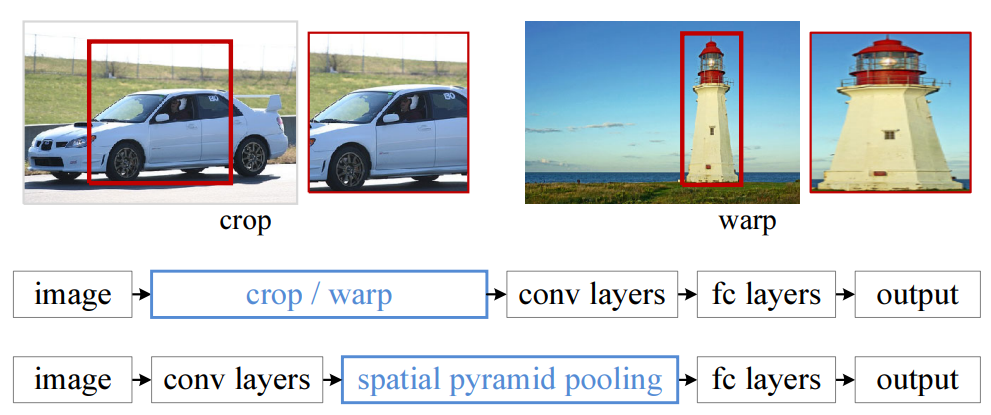
위에는 R-CNN 아래는 SPPNet입니다. 보면 resize의 과정이 없어진 것을 볼 수 있습니다.
또한 R-CNN은 처음 image에 대해 selective algorithm을 적용하여 crop한 cropped image 2,000장을 모두 CNN을 통과 시킵니다. 이때 cropped image의 size는 모두 달라 resize의 과정이 필요합니다.
하지만 SPPNet은 한장의 image에 대해 CNN을 통과 시킨후 마지막 conv에서 bnd룰 이용하여 cropped feature map을 뽑습니다. 이후 SPP-layer를 통과시켜 같은 크기의 만들어 FC-layer에 들어갈 수 있게 해줍니다.
2. CNN Block
위에서 SPP를 이용하므로 resize가 필요 없다고 하였습니다. 이 부분이 오해의 소지가 있습니다. 위의 그림을 자세히 본다면 사실 resize가 필요하다고 생각할 수 있는 부분이 2곳 있습니다. 첫번째는 Conv 마지막에 crop한 image에 대한 resize 이고 두번째는 input image에 대한 resize입니다. 첫번째 부분은 SPP를 이용하여 해결 가능한 부분이고 두번째는 crop을 하기 때문에 resize가 필요 없게 됩니다.
즉, 기존의 classification은 input image가 같은 size여야 했는데 위와 같은 object detection에서는 input image를 crop하고 실제 학습에는 cropped image가 사용되므로 input image의 size는 의미가 없어진다고 생각해도 됩니다.
이 부분은 논문에서 다음과 같은 문장으로 잘 설명 되어 있다.
"The convolutional layers accept arbitrary input sizes, but they produce outputs of variable sizes."
다만 실제로 different size input을 적용하는 것은 상당히 어려운 것으로 알고 있습니다. 일단 pytorch 만 하더라도dataloader가 항상 same sized image만 iterate하게끔 코딩되어 있고 different sized image에 대해서는collate_fn이부분을 건들어 줘야 하는데 이건 잘 모르겠습니다.
https://discuss.pytorch.org/t/torchvision-and-dataloader-different-images-shapes/41026/3
이렇게 찾으면 됩니다.
또한 CNN 마지막에 crop되는 부분은 R-CNN과 동일하게 selective search를 이용하여 2,000장의 cropped image를 얻습니다.
(논문에 classification도 있긴한데 일단은 object detection만 본다.)
여기서 시간 차이가 심하게 발생합니다.
R-CNN needs 2,000 calculations in CNN for 1 image, otherwise SPPNet needs only 1 calculation.
여기서 주의해야 할 점이 있습니다. 심지어 몇몇의 블로그에는 잘못 설명되어 있는 부분이기도 합니다.
대부분 실수하는 것이 다음과 같은 문장입니다.Input image를 Conv를 통과시켜 feature vector를 뽑아 이를 selective search를 이용하여 RoI를 뽑는다.
위 문장은 틀렸습니다.
첫번째로 Conv를 통과한 feature vector는 우리가 알고있는 RGB 3-channel의 iamge가 아닙니다. Conv에 따라 다르겠지만 적어도 256-channel이상일 겁니다. 이는 Image라고 부를수는 없습니다. 그래서 feature map이라고 부르고 정확하게는 channel별로 feature를 다른게 잡는다 하여 그렇게 부릅니다.
또한 selective search algorithm은 image에 대해서 물체가 있을법한 RoI를 output으로 내주는 algorithm입니다.
즉, feature map에 selective algorithm을 적용할수는 없지요.
물론 무조건 안된다라기 보다는 개념 자체가 다릅니다. selective serach는 Image에 맞게 고안된 algorithm이기 때문입니다.
그런데 충분히 오해의 소지가 있습니다. 주된 이유는 보통 설명할때 사용하는 아래의 문장이라고 생각합니다.
SPPNet이 R-CNN보다 좋은 이유가 Input image를 Conv에 통과한 후 crop하기 때문입니다.이렇게 말하는 순서 때문인데 이를 표현하면 Image -> Conv -> crop 이렇게 보이기 때문입니다. 즉, feature map을 crop하긴 하는데 feature map에 selective search를 사용한다고 충분히 생각할 만 합니다.
또한 본 논문에서는 당연히 feature map에서 selective는 말이 안된다고 생각하는지 따로 언급하지는 않는것 같습니다.
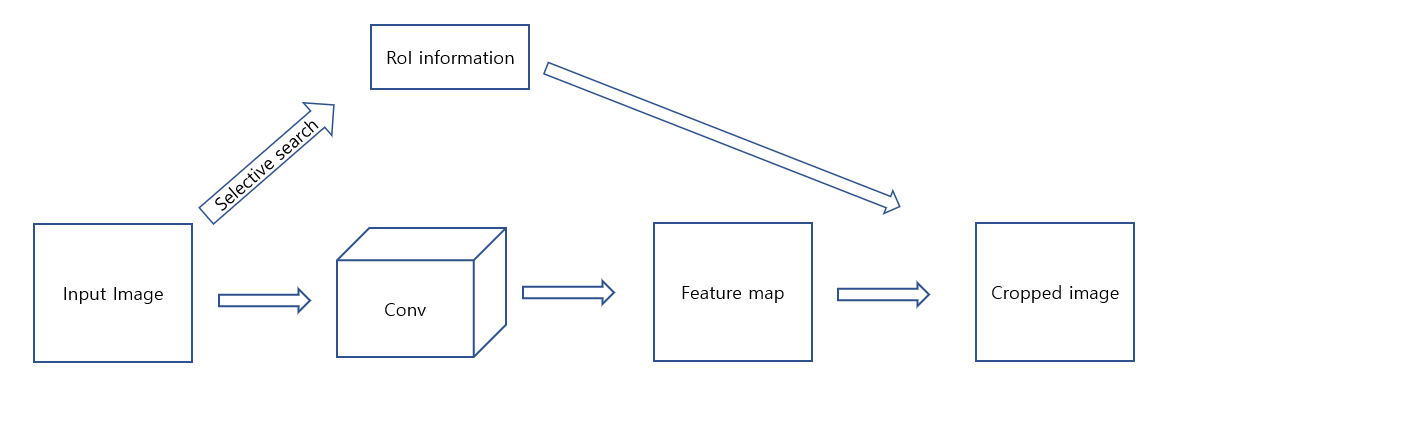
그럼 어떻게 crop하는 것일까요? 아래의 그림을 보면 바로 이해가 됩니다.
즉, Input image에 selective serach를 적용하여 이 정보를 저장합니다. Feature map의 size는 사용한 Conv에 따라 다르겠지만 Input image보다는 작습니다. 따라서 RoI 정보를 Input image -> feature map으로 갈때 줄어든 만큼 mapping을 해주면 됩니다.
이제 이 과정이 이해가 되었다면,위의 1. Overal architecture의 그림에서 아래가 SPPNet인데 위의 R-CNN에는 crop이 있는 반면 SPPNet에는 crop이 들어가 있지 않는 이유도 이해가 되실 겁니다. conv layers 를 기준으로 앞, 뒤 어느 한곳에 넣어도 둘다 100% 맞다고는 할 수 없으므로 아예 삽입하지 않은것 같습니다. 또한 아래의 iamge도 쉽게 찾아 볼 수 있습니다.
https://yeomko.tistory.com/14
이 그림이 처음에는 잘못 표시 된 줄 알았었는데 위의 사실을 이해하고 나면 정말 잘 표현된 그림이라는 것도 알 수 있습니다.
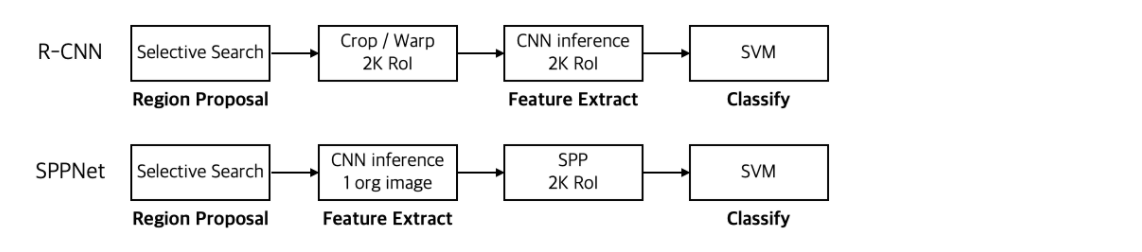
3. SPP layer
본 논문의 핵심 구조입니다.
간단하게는 cropped image를 FC-layer를 통과 시키기 위해 고정된 크기의 vector를 만들어 주는 역할을 한다고 보면 됩니다.
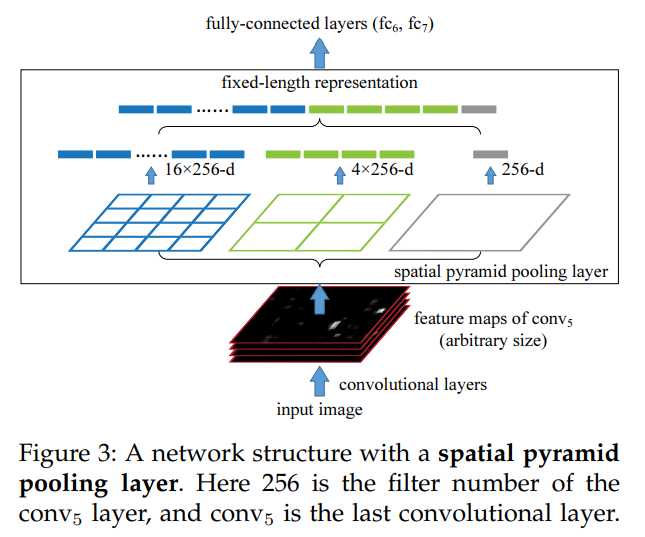
다시 간략한 설명을 하자면 Conv을 거치고 마지막 Conv5의 feature map을 Input image에 selective search를 적용한 RoI를 이용하여 crop합니다. 따라서 256-channel cropped feature map을 얻게 되며 size는 대부분 다릅니다. 모두 다른 size의 feature map은 spp-layer를 거쳐 같은 길이인 n-size vector로 표현이 됩니다.
목표하는 n이 21이라는 예시를 들어보겠습니다. 을 이용합니다.
즉, 위의 그림과 같이 [4x4, 2x2, 1x1]size의 feature map을 만들기 위해 window와 stride가 유동적인 pooling을 사용하게 됩니다. 이때 13x13의 image가 들어오는 경우에는 순서대로 <w=4, s=3>, <w=7, s=6>, <w=13, s=0>으로 해주면 됩니다.
즉, axa의 image가 들어오고 목표한 vector의 길이를 맞추기 위한 feature map들중 하나의 size가 kxk 이라면 w = [a/k]+1 , s = [a/k]으로 pooling을 적용하면 됩니다.
위의 예시에서 feature map을 총 3가지의 size로 pooling하였습니다. 이를 서로 다른 size의 pooling을 쌓는다 하여 pyramid라고 합니다.
이렇게 하여 서로 다른 size의 croppef feature map에 대해 모두 같은 n-size의 vector로 만들어 줄 수 있습니다.
다만 정확하게 말하면 channel까지 생각해야 하므로 n×channel-d vector가 맞는 표현 입니다.
4. SVM and BND regression
SPP-layer의 output인 21-d vector를 이용하여 classification을 수행하는 SVM을 학습하며 RoI를 수정하기 위해 BND Regression을 진행합니다.
이 부분은 아래 사진에서 보듯이 R-CNN와 같은 방식을 사용합니다.



자세한 설명은 R-CNN 설명 post인
https://velog.io/@jj770206/Rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation-RCNN
에 있습니다.
.png)