[논문 리뷰] Enhancing Time Series Forecasting via Multi-Level Text Alignment with LLMs (DASFAA 2025)
Motivation
계열 데이터의 연속성과 LLM의 이산적 토큰 간의 간극을 좁히고, 기존 텍스트 리프로그래밍(Reprogramming) 방식의 낮은 해석 가능성(Interpretability) 문제를 해결하고자 함.
Solution
시계열을 Trend, Seasonal, Residual로 분해한 뒤, 각 요소를 텍스트 앵커 및 프로토타입에 매핑하는 'Multi-level text alignment'를 제안. 뿐만 아니라 모델의 판단 근거를 설명할 수 있는 해석 가능성을 확보함.
1. Introduction
핵심 목표
"시계열 데이터(연속적 수치)"와 "LLM(이산적 텍스트 토큰)" 사이의 간극을 줄이고, 해석 가능성을 높이는 것
1.1 Problem Define
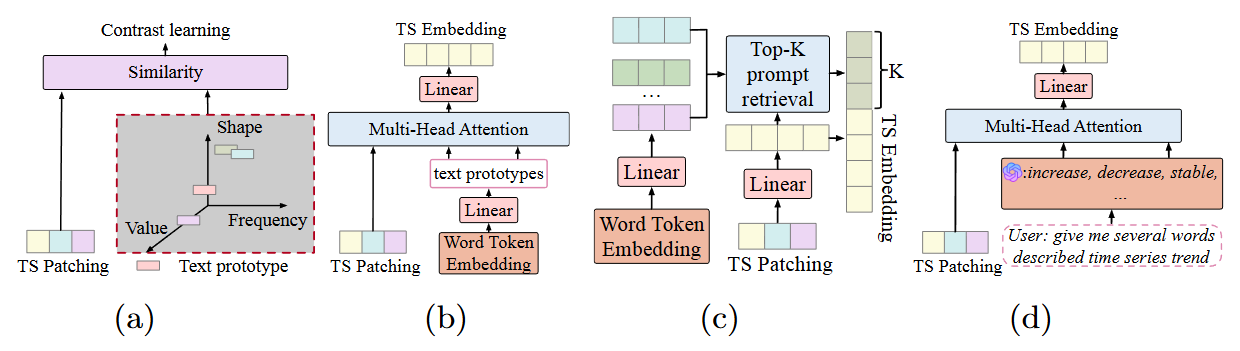
figure 1: LLM을 활용한 시계열 예측에서 시계열 데이터를 텍스트 기반 표현과 정렬하는 다양한 접근 방식
(a): Contrastive Learning 방식: 시계열 데이터의 형태(Shape), 빈도(Frequency), 값(Value)을 분석하여 가장 유사한 단어 임베딩과 매핑
(b): Text Prototypes Reprogramming: 시계열 패치(Patch)를 선형 레이어(Linear)를 통해 '텍스트 프로토타입'으로 변환하여 LLM에 입력하는 방식
(c): Semantic Informed Prompt: 프롬프트 검색(Retrieval)을 통해 시계열 임베딩과 텍스트 사이를 연결하려 시도
이러한 방식들은 텍스트 프로토타입을 임의로 선정하거나, 데이터의 실제 특성을 제대로 반영하지 못하는 경우가 많았음.
예시로, 실제로는 '상승(Upward)'하는 추세인데, 엉뚱하게 '하락(Decline)'이라는 단어와 매핑되거나 전혀 상관없는 단어와 연결되어 해석이 불가능해짐.
(d)와 같이 Proposed Anchors Alignment 방식
- 핵심 아이디어
- 시계열을 통째로 넣는 대신, 추세(Trend), 계절성(Seasonal), 잔차(Residual)의 세 가지 성분으로 분해
- LLM이 이해할 수 있는 명확한 언어적 앵커(Anchors)를 사용하여 시계열을 설명하도록 유도
- 설명
- User: give me several words described time series trend처럼 명시적으로 요청
- 모델은 increase, decrease, stable (증가, 감소, 안정)와 같이 사람이 직관적으로 이해할 수 있는 단어(앵커)들과 시계열 데이터를 alignment 수행
- 즉, 모호한 텍스트 프로토타입 대신, 구체적인 설명이 가능한 단어들과 매핑하여 예측의 정확도와 설명력을 동시에 높임
1.2 Contributions
-
backbone model 유지: LLM 자체를 수정하지 않고, 입력단의 Alignment 방식만 개선하여 효율성 확보
-
Multi-Level Text Alignment: 시계열을 분해(추세, 계절성, 잔차)하고 각 성분을 그에 맞는 텍스트 표현으로 변환하여, 정보 손실을 줄이고 해석력을 높임.
- 추세(Trend) 해석 가능한 앵커(increase, decrease 등)와 정렬.
- 계절성/잔차 전반적인 표현력 향상
-
높은 성능 달성: 여러 TSF task에 맞는 benchmark datasets에 대해거 기존 SOTA보다 정확도가 높고 해석이 용이함을 증명함.
2. Related Work
-
기존 접근 방식
-
시계열의 텍스트 변환 (Promptcast, LLMTime): 수치 데이터의 입출력을 프롬프트로 재구성하여, 시계열 예측을 '문장 대 문장(Sentence-to-Sentence)' 작업으로 변환해 처리함.
-
패치화 및 미세 조정 (GPT4TS, TEMPO): 시계열 데이터를 패치(Patch) 단위로 토큰화하거나, 사전 학습된 LLM의 일부(Add&Norm 레이어 등)를 미세 조정(Fine-tuning)하여 적용함.
-
검색 기반 프롬프트 (S2IP-LLM): 의미론적(Semantic) 프롬프트나 검색(Retrieval) 기반 방식을 통해 시계열 임베딩과 텍스트 정보를 연결함.
-
프로토타입 기반 정렬 (TEST, TimeLLM): 대조 학습을 통해 시계열을 단어 임베딩에 매핑하거나(TEST), 백본 모델 수정 없이 텍스트 프로토타입으로 리프로그래밍(TimeLLM)함.
-
-
주요 한계
-
해석 가능성(Interpretability) 결여: 시계열을 단순한 토큰 시퀀스로만 취급하여 데이터 고유의 시간적 구조(Temporal Structure)를 무시하는 경향이 있음.
-
매핑의 부정확성: 주로 "시계열 패턴 텍스트"의 패러다임을 따르는데, 이 과정에서 임의로 선택된 텍스트 프로토타입이 데이터의 실제 특성을 제대로 반영하지 못함.
-
모델 투명성 저하: 잘못된 정렬(Alignment)로 인해 예측 정확도가 떨어지며, 모델이 왜 그러한 예측을 했는지 설명하기 어려움(다변량 시계열에서 특히 두드러짐).
-
3. Methodology
본 연구는 시계열 데이터를 성분별로 분해해 텍스트 앵커와 정렬하는 4단계 프레임워크(분해, 정렬, 프롬프트, 투영)를 적용하고, 미세 조정 없는 GPT-2(초기 6개 층)를 백본으로 활용하여 해석 가능한 예측을 수행
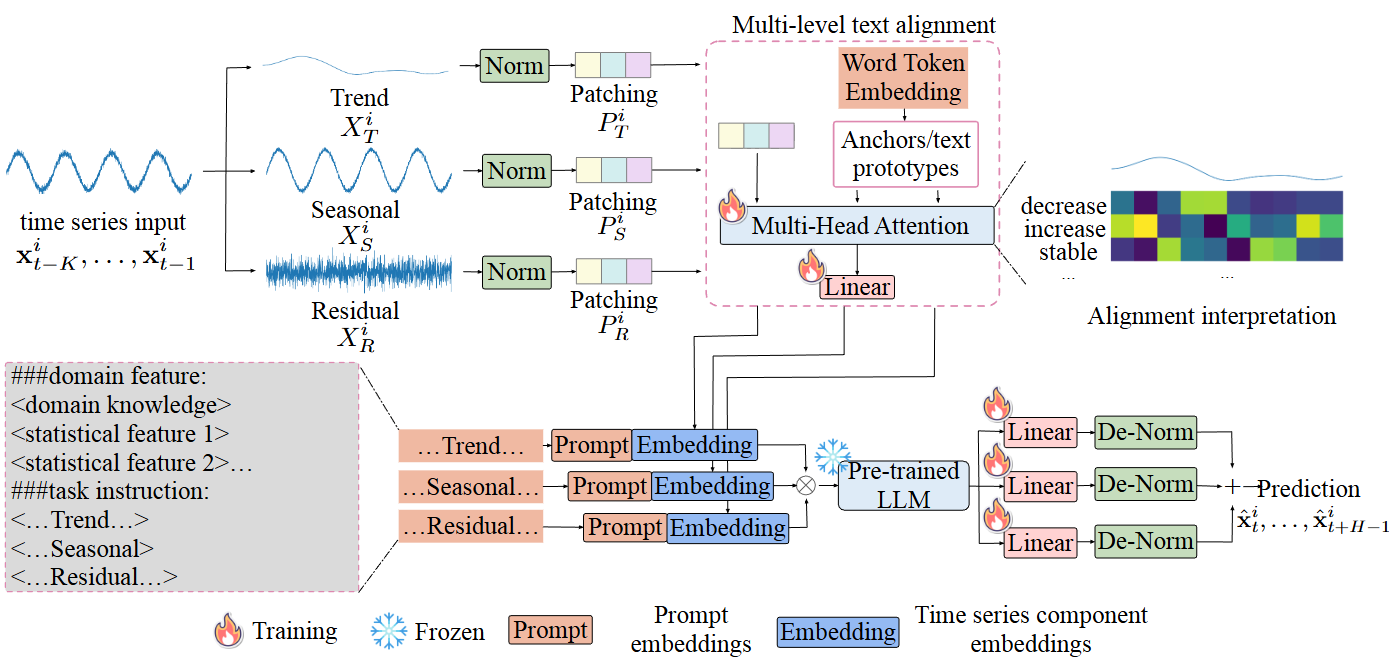
3.1 Time Series Input Decomposition
-
Decomposition
- 추세 (): 이동 평균(Moving Average) 등을 통해 장기적인 패턴을 추출
- 계절성 (): 반복되는 단기 사이클을 추출
- 잔차 (): 위 두 요소를 뺀 나머지 불규칙한 변동
- 분해 방법으로는 이동 평균법이나 STL(Seasonal-Trend decomposition using Loess)
-
Patching:
- 분해된 각 성분(T, S, R)을 LLM이 처리할 수 있는 토큰 단위인 패치(Patch)로 자름
- 이 과정은 긴 시계열 데이터를 작은 조각()으로 나누어 임베딩할 준비를 하는 단계
3.2 Multi-level text alignment
-
추세(Trend) 정렬 해석 가능성(Interpretability) 초점:추세는 사람이 말로 설명하기 쉬움 (예: "증가한다", "감소한다", "안정적이다").
-
따라서 추세 패치()는 사전에 정의된 텍스트 앵커(Anchors, )와 직접 정렬 이를 통해 모델이 "이 데이터는 상승 추세다"라고 명확히 이해하게 만듬
-
계절성(Seasonal) & 잔차(Residual) 정렬 정보 표현력 초점:이들은 단순한 단어로 정의하기 어렵습니다. 따라서 사전 학습된 LLM의 단어 임베딩 공간()에서 학습된 텍스트 프로토타입()과 정렬
- 잔차()가 계절성보다 불규칙하므로, 잔차를 표현하는 프로토타입의 개수()를 더 많이 할당하여 표현력을 높임
-
정렬 메커니즘 (Multi-Head Cross-Attention):시계열 패치를 Query(Q)로, 텍스트 앵커/프로토타입을 Key(K)와 Value(V)로 사용하여 어텐션 연산을 수행
- 수식: 이 과정을 통해 시계열 데이터가 텍스트의 의미를 담은 임베딩()으로 변환
3.3 Component-specific prompts
정렬된 임베딩만 넣는 것이 아니라, LLM이 작업을 더 잘 수행하도록 텍스트 지시사항(Prompt)을 함께 넣어줌
-
프롬프트 구성:
-
도메인 지식: 데이터셋의 배경 정보
-
통계적 특징: 데이터의 평균, 분산 등 요약 정보
-
작업 지시(Task Instruction): "지난 512 스텝의 [추세, 계절성, 잔차]를 보고 다음 96 스텝을 예측하라"는 식의 템플릿
-
-
백본 모델 (Backbone LLM):
- GPT-2의 초기 6개 레이어 사용
- 중요한 점은 GPT-2를 미세 조정(Fine-tuning)하지 않고 Frozen 상태로 사용
- 오직 앞단의 정렬 모듈과 뒷단의 투영 레이어만 학습
3.4 Output Projection
LLM을 통과한 결과물을 다시 시계열 수치로 변환
- Linear Projection
- LLM에서 나온 출력 임베딩을 선형 레이어(Linear Layer)에 통과시켜 각 성분별 예측값을 만듬
- 역정규화 및 합산 (De-Norm & Summation)
- 정규화되었던 값을 다시 원래 스케일로 돌려놓음(De-Norm).
- 마지막으로 예측된 추세(), 계절성(), 잔차()를 모두 더하여 최종 예측값 를 도출
4. Experiments
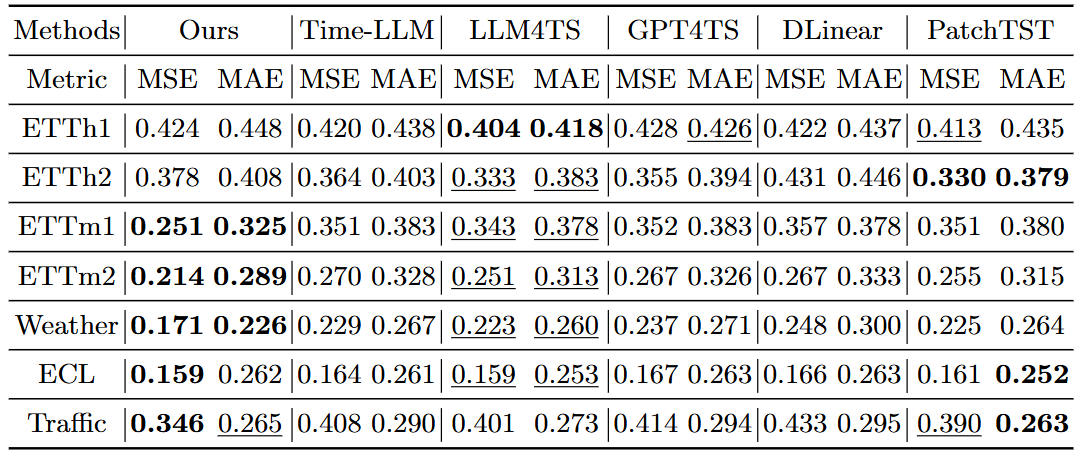
-
목적: 최신 SOTA 모델(PatchTST, DLinear, TimeLLM 등) 대비 장기·단기·퓨샷 예측 성능의 우수성 입증 .
-
실험 설정
-
데이터셋: ETT 계열, Weather, ECL, Traffic 등 7종 (입력 길이 512, 예측 범위 96~720)
-
백본 모델: 공정한 비교를 위해 GPT-2의 초기 6개 레이어만 사용 (TimeLLM, GPT4TS와 동일 조건) .
-
평가 지표: MSE(평균 제곱 오차), MAE(평균 절대 오차) .
-
결과: 대부분의 벤치마크에서 가장 낮은 오차율을 기록했으며, 특히 Weather와 ETTm1 데이터셋에서는 기존 최고 모델(LLM4TS) 대비 20% 이상 성능 향상을 달성함 .
-
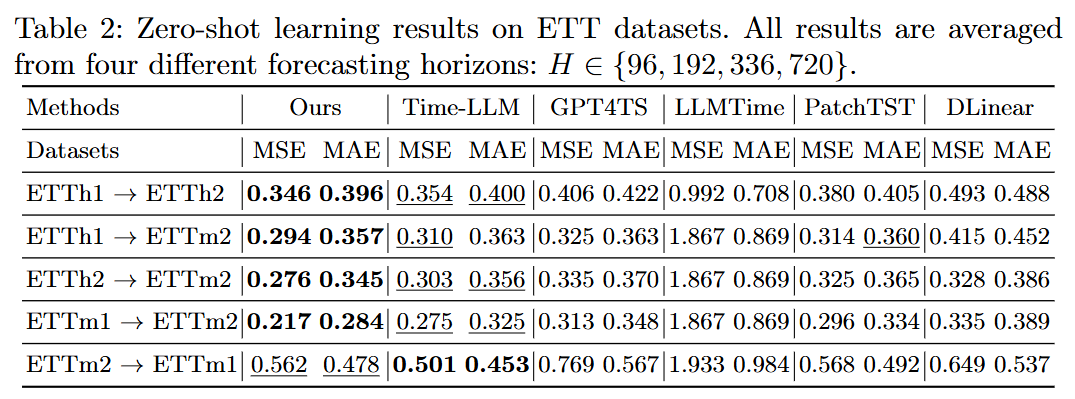
-
Zero shot train
- 특정 데이터셋에서 훈련된 모델이, 한 번도 보지 못한 다른 데이터셋에 대해 추가적인 fine-tuning 없이 얼마나 잘 예측하는지를 평가
-
Zero shot task에서 좋은 성능을 보임
- ETTm2 → ETTm1 (location 차이)
ETTm datasets → 15분 단위의 고주파 데이터 (변동성이 크고, 노이즈가 많을 수 있음)
ETTm2 datasets 자체에 대해서 trend seasonal residual 등이 anchor alignment이 덜 부합한 것으로 생각
- ETTm2 → ETTm1 (location 차이)
4.1 Multi-level text alignment variants
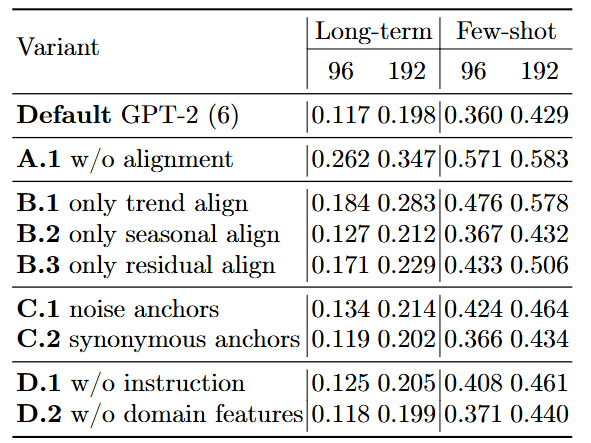
-
정렬(Alignment) 과정이 없으면 성능이 75% 이상 급락하므로, 추세·계절성·잔차 3가지 성분 모두를 정렬하는 것이 필수
-
의미 없는 단어를 앵커로 사용하면 오차가 커지지만, 동의어를 사용하면 성능 차이가 없어 모델이 단어의 실제 '의미'를 파악하고 있음을 입증
-
단순한 데이터 입력보다 좋은 작업 지시문과 도메인 지식을 함께 제공해야 LLM의 추론 능력을 극대화하여 예측 정확도를 높일 수 있음
4.2 Multi-level text alignment interpretation
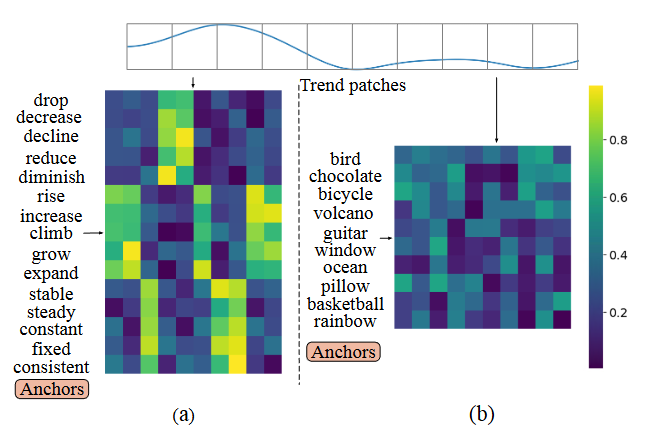
-
실험방법
ETTm1 데이터셋을 사용하여, 시계열의 Trend Patches와 미리 정의된 앵커 단어들 사이의 Attention Score를 히트맵으로 표현 -
결과
-
(a) Synonymous Anchors: '상승(rise, increase)'이나 '하락(drop, decrease)'과 같은 단어들이 실제 해당 추세를 보이는 시계열 구간에서 높은 score값
-
(b) Noise Anchors: '새(bird)', '초콜릿(chocolate)'처럼 시계열과 무관한 단어들을 앵커로 사용했을 때는 score값 낮음
-
5. Conclusion and future work
-
결론: 사전 학습된 LLM을 활용해 시계열 성분을 텍스트 앵커 및 프로토타입과 정교하게 매핑하는 '다단계 텍스트 정렬 프레임워크'를 제안하여 예측 정확도와 해석 가능성을 동시에 향상
-
성과: 실험을 통해 텍스트 앵커와 정렬된 시계열 토큰이 데이터의 추세를 명확하고 직관적으로 설명할 수 있음을 입증
-
향후 과제: 앵커와 토큰 간의 정렬 모듈을 더욱 최적화하고, 시계열과 자연어 등 다양한 데이터를 아울러 공동 추론(Joint Reasoning)이 가능한 멀티모달 모델로 확장할 계획
