- 해당 파트를 이해하기 위해선 이전 포스트의 CNN 에 대한 개념과 정리가 필요합니다. https://velog.io/@jjong2961/Convolution-Neural-Network-CNN
CNN in Image Classification
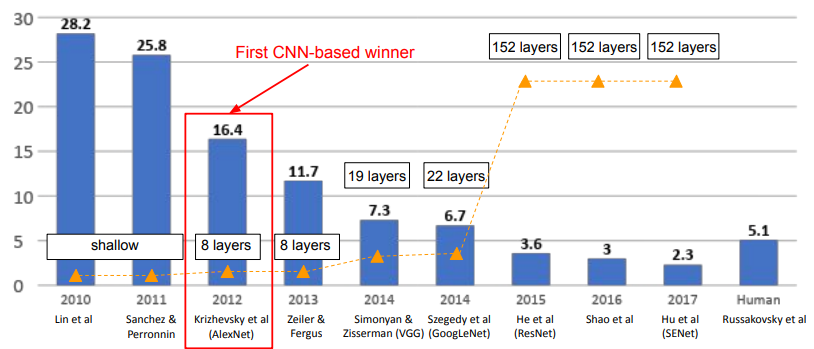
- 해당 그림은 http://cs231n.stanford.edu/slides/2022/lecture_6_jiajun.pdf 의 강의에서 가져온 그림입니다.
CNN 에서는 layer가 많아질수록 이미지 분류 성능이 증가하였고, 심지어 효율적으로 연산하기까지 합니다. layer의 구조에 따라 다양한 CNN의 모델이 등장하였는데, 등장한 모델들을 소개해드리도록 하겠습니다.
Case 1. AlexNet
- AlexNet 특징
- Input Size : 227*227
- 초기 단계에서는 large filter size & stride
- 상위 단계에서는 smaller size
- AlexNet의 구조
AlexNet의 기본 구조는 LeNet-5와 크게 다르지 않습니다. 2개의 GPU로 병렬연산을 수행하기 위해 병렬적인 구조로 설계되었다는 점이 큰 차이라고 볼 수 있습니다.
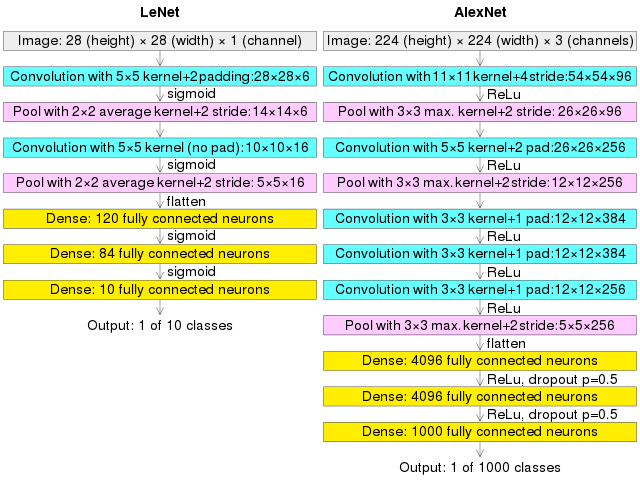
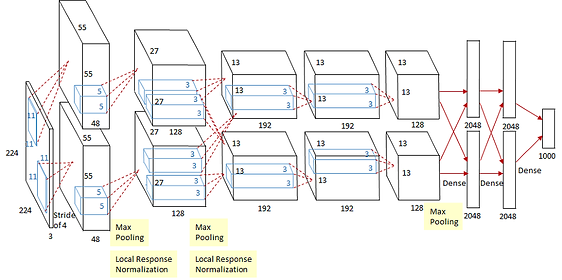
- AlexNet은 8개의 layer로 구성되어 있습니다. 5개의 Convolution layer, 3개의 Fully-connected layer로 구성되어있습니다. 두번째, 네번째, 다섯번째 Convolution layer들은 전 단계의 같은 채널의 Feature map들과만 연결되어 있는 반면, 세번째 Convolution layer는 전 단계의 두 채널의 Feature map들과 모두 연결되어 있는 것이 특징입니다.
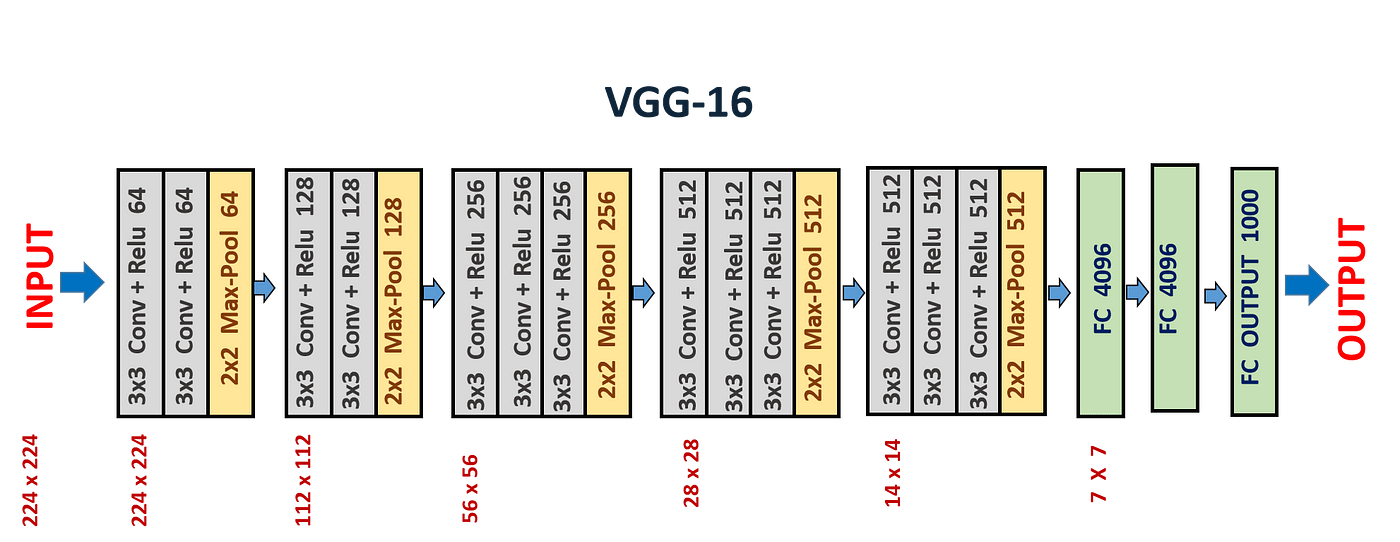
Case 2. VGGNet - VGG 16, VGG 19
- VGG 는 Visual Geometry Group의 약자입니다. 다중 레이어가 있는 표준 심층 CNN아키텍처 입니다. VGG 뒤의 16과 19는 레이어의 수를 나타냅니다.
What's VGG16?
16개의 레이어를 지원하며, 이미지를 키보드, 동물, 연필, 마우스 등을 포함하여 1000개의 개체 범주로 분류할 수 있습니다. 또한 모델의 이미지 입력 크기는 224 x 224 입니다.
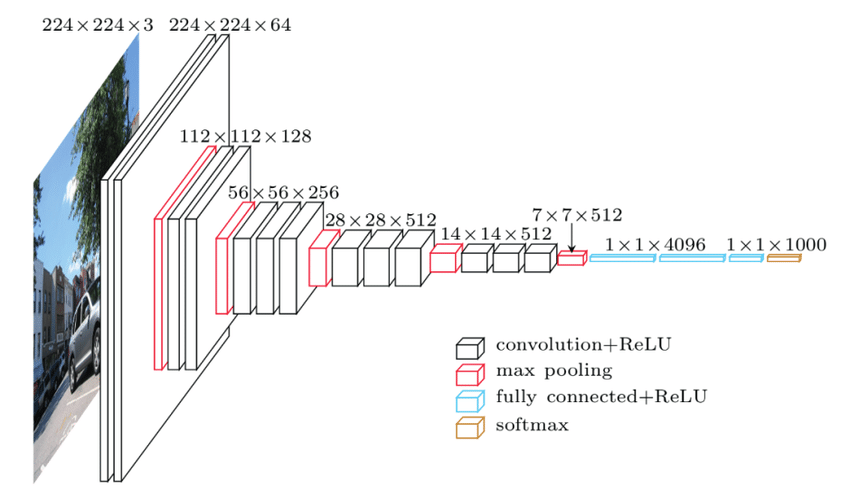
- VGG 16은 13개의 Convolution layer와 3개의 Fully-Connected layer로 구성됩니다.
VGG 16 의 구조
Input : VGGNet은 224 x 224의 이미지 입력 크기를 받습니다. ImageNet 대회의 경우 모델 작성자는 이미지의 입력 크기를 일관되게 유지하기 위해 각 이미지의 중앙 224 x 224패치를 잘라냈습니다.
Convolution layer :VGG의 컨볼루션 레이어는 최소 수용 필드, 즉 위/아래 및 왼쪽/오른쪽을 캡처하는 가능한 가장 작은 크기인 3×3을 활용합니다. 또한 입력의 선형 변환으로 작동하는 1x1 컨볼루션 필터도 있습니다. 그 다음에는 훈련 시간을 줄이는 AlexNet의 Activation Function ReLU가 뒤따릅니다. convolution stride는 convolution 이후에 공간 해상도를 유지하기 위해 1픽셀로 고정됩니다(stride는 입력 행렬에 대한 픽셀 이동 수입니다).
Hidden layer : VGG 네트워크의 모든 hidden layer는 ReLU를 사용합니다. VGG는 메모리 소비와 훈련 시간을 증가시키기 때문에 일반적으로 LRN(Local Response Normalization)을 활용하지 않습니다.
Fully-connected layer : VGGNet에는 3개의 완전 연결 계층이 있습니다. 세 개의 레이어 중 처음 두 레이어에는 각각 4096개의 채널이 있고 세 번째 레이어에는 클래스당 1개씩 1000개의 채널이 있습니다.
VGG 16 Architecture