
1. GoogLeNet
- GoogLeNet 특징
- 22개의 Layer
- Inception Module
- No Fully-Connected layers
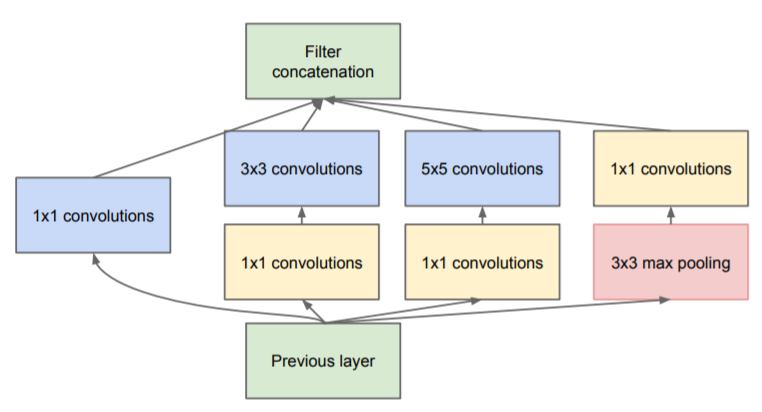
- Inception Module : Inception Module은 입력값에 대해, 4가지 종류의 Convolution, Pooling을 수행하고, 4개의 결과를 채널 방향으로 합칩니다. 이러한 Inception Module이 모델에 총 9개가 있습니다.
- Inception Module에서 4가지의 연산
- 1 x 1 Convolution
- 1 x 1 Convolution + 3 x 3 Convolution
- 1 x 1 Convolution + 5 x 5 Convolution
- 3 x 3 MaxPooling + 1 x 1 Convolution
▶ 이 4개의 연산결과를 Channel-wise Concat합니다. 즉, Feature Map을 쌓는 것입니다.
- Inception Module에서 Feature Map을 효과적으로 추출하기 위해 1x1, 3x3, 5x5의 Convolution 연산을 각각 수행하며, 3x3 Max Pooling에서 입력과 출력 Matrix의 Height, Width를 같게해야하므로 Pooling 연산에서 Padding을 추가해 줍니다.
- Feature Map을 추출하는 과정에서 엄청나게 많은 연산과정을 거쳐야 하는 문제가 생기게 되는데, 이를 해결하기 위해 3x3, 5x5 Conv 연산 전에 3x3 MaxPooling 이후 1x1 Conv가 먼저 진행되는 것입니다.
GoogLeNet Architecture
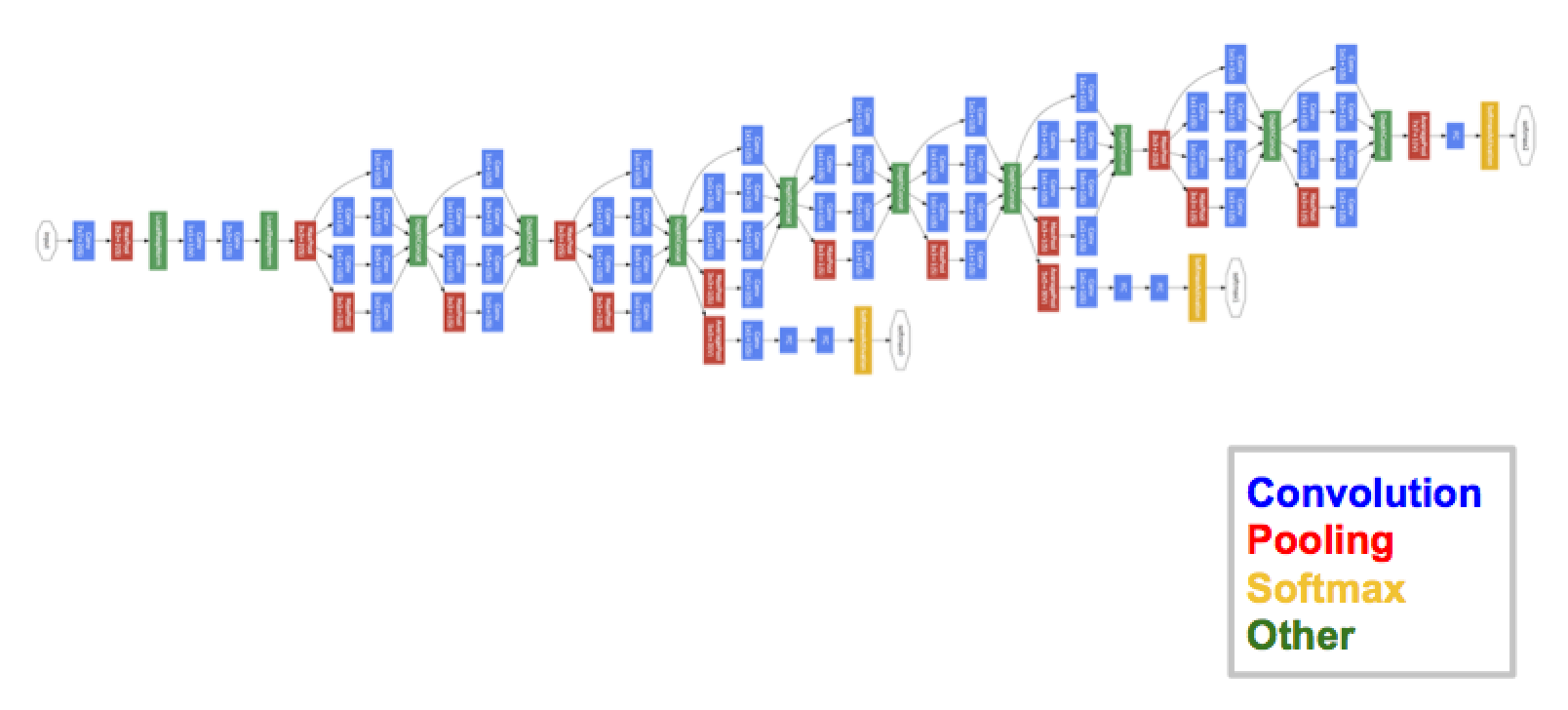
- 위에 그림이 GoogLeNet의 구조입니다. GoogLeNet이 그림처럼 아주 Deep한 신경망으로 구성되어 학습이 가능했던 것은 위에서 설명드린 Inception Module 때문입니다.
Inception Module의 기능
Inception Module에서 1x1 convolution은 핵심 역할을 하는데, 1x1 Conv을 넣어 channel을 줄였다가, 다음의 3x3, 5x5 Conv에서 다시 확장하여 필요한 연산량을 감소 시킵니다.
- 1. Channel Size를 조절 하는 기능
Channel Size를 조절한다는 의미는, 채널 간의 Correlation을 연산하는 의미입니다. 기존의 Conv 연산, 3x3의 필터로 연산 할 경우, 3x3 크기의 지역 정보와 함께 채널 간의 정보 또한 같이 고려하여 하나의 값으로 나타냅니다. 즉, 하나의 커널이 2가지의 역할을 모두 수행해야하는 것입니다.만약, 1x1 convolution을 사용한다면, 1x1은 채널을 조절하는 역할을 하기 때문에, 최적화 과정에서 채널 간의 특징을 추출 할 것이고, 3x3은 이미지의 지역정보에만 집중하여 특징을 추출하려 할 것입니다 (필터 크기 세분화). 채널간의 관계정보는 1x1 convolution에 사용되는 파라미터들 끼리, 이미지의 지역정보는 3x3 convolution에 사용되는 파라미터들 끼리 연결된다는 점에서 노드 간의 연결을 줄였다고 볼 수 있습니다.
- 2. Decrease Channel (Decrease Parameter)
1x1 Conv연산으로 이미지의 채널을 줄여준다면, 3x3과 5x5 Convolution layer에서 파라미터 개수를 절약할 수 있다. 이 덕에 망을 기존의 CNN 구조들 보다 더욱 깊게 만들고도 파라미터의 크기가 크지 않습니다.v1모델에서 첫번째 계층을 Stem Layer라고 하는데 v3모델까지 사용합니다. 이 첫번째 계층은 Convolution 연산을 하는데, 학습에 큰 영향을 주며 일반적인 CNN 모델과 같습니다. 이 모델의 마지막에는 Feature Map의 크기와 같은 필터크기로 Average Pooling을 수행한 후 Fully-Connected layer를 지나 softmax 함수로 예측 결과물을 보여줍니다. 여기서 파라미터 수를 결정하는 큰 요인 중 하나인 Fully-Connected layer에서 적게 사용하면 파라미터 수를 더욱 절약할 수 있습니다.
파라미터에 대한 연산량을 개선한 Model_v1
참고
https://ikkison.tistory.com/86
논문
https://arxiv.org/abs/1409.4842

please bbbbbbbbb 😂