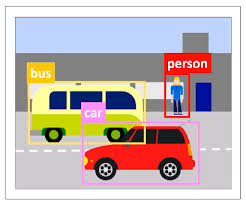
DETR
- Transformer를 Object Detection에 최초로 적용
- 기존의 Object Detection 모델들과 달리 Direct Prediction이 가능하여 Hand-crafted Process가 없어도 됨
- 하나의 Ground Truth에 오직 하나의 예측된 Bounding Box만 Matching(One-to-One) -> Post-processing 과정 불필요
DETR 장점과 단점
-
장점
-
object detection에서 발생하는 문제들을 해결하기 위해 위의 기법들이 각각 적용되는데 이렇게 복잡해지는 과정을 direct prediction으로 아주 단순하게 만들어 버렸다.
-
CNN 이후 Transformer를 사용하면 되는 구조로 매우 단순한 구조를 취하게 된다.
-
-
단점
-
Transformer의 특성상 학습하는데 굉장히 많은 시간이 필요하다.
-
small object 탐지력이 약하다.
-
Original Transformer vs DETR Transformer
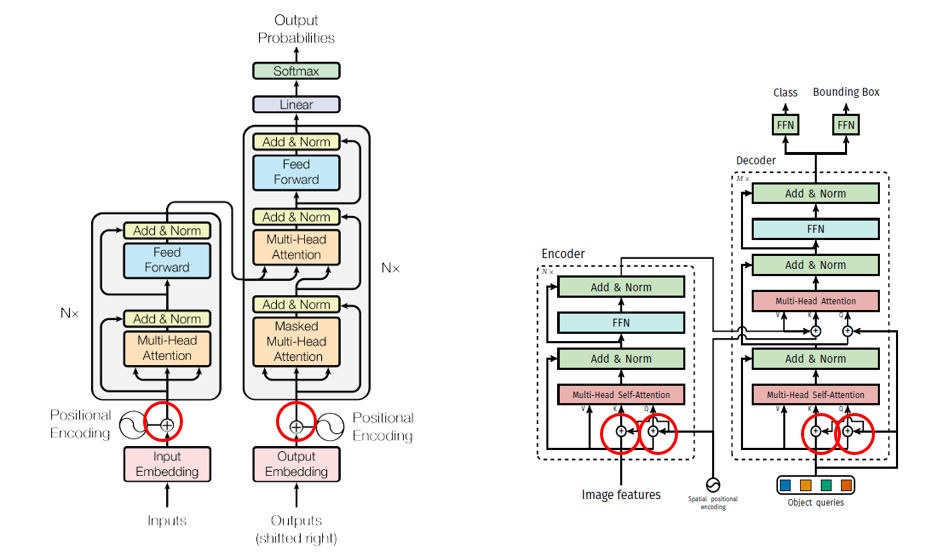
- positional encoding하는 위치가 다르다. Vaswani의 original transformer는 transformer module(encoder, decoder)에 한 번만 encoding을 하지만 DETR은 모든 encoder, decoder module에서 positional encoding을 한다. 이 때 attention에서만 positional encoding을 하는데 이 방법이 성능이 더 좋다는걸 이론적으로 설명하진 않고 실험적으로 증명하고 있다.
- Vaswani의 transformer는 auto-regression방식으로 output하지만 DETR은 parallel 방식으로 output한다.
-
DETR는 encoder에서 이미지 feature map을 입력받는 반면, Transformer는 문장에 대한 embedding을 입력받습니다. Transformer는 sequence 정보를 입력받는데 적합하기 때문에 DETR은 CNN backbone에서 feature map을 추출한 이후, 1x1 convolution layer를 거쳐 차원을 줄인 다음, spatial dimension을 flatten하여 encoder에 입력합니다. h, w가 height, width이며, C가 channel 수, d가 C보다 작은 channel 수라고 할 때 C×h×w 크기의 feature map을 d×hw로 변환시켰다고 볼 수 있습니다.
-
positional encoding에서 차이가 있습니다. Transformer는 입력 embedding의 순서와 상관 없이 동일한 값을 출력하는 permutation invariant한 성질을 가졌기 때문에 positional encoding을 더해줍니다. DETR은 x, y axis가 있는 2D 크기의 feature map을 입력받기 때문에 기존의 positional encoding을 2D 차원으로 일반화시켜 spatial positional encoding을 수행합니다. 입력값의 차원이 d라고 할 때 x, y 차원에 대하여, row-wise, column wise로 2/d 크기로 sine, cosine 함수를 적용합니다. 이후 channel-wise하게 concat하여 d channel의 spatial positional encoding을 얻은 후 입력값에 더해줍니다.
-
Transformer는 decoder에 target embedding을 입력하는 반면, DETR은 object queries를 입력합니다. object queries는 길이가
N인 학습 가능한 embedding입니다. object query에 대한 구체적인 설명은 Method 파트에서 살펴보겠습니다. -
Transformer는 decoder에서 첫 번째 attention 연산 시 masked multi-head attention을 수행하는 반면, DETR은 multi-head self-attention을 수행합니다. 이는 Transformer는 auto-regressive하게 다음 token을 예측하기 때문에 attention 연산 시 다음 token에 대한 정보를 활용하는 것을 방지하기 위해 후속 token에 대한 정보를 masking합니다. masking은 attention 연산에서 softmax 함수 입력에 후속 token 위치에 -inf를 입력하는 방식으로 수행됩니다. 하지만 DETR은 입력된 이미지에 동시에 모든 객체의 위치를 예측하기 때문에 별도의 masking 과정을 필요로 하지 않습니다.
-
Transformer는 Decoder 이후 하나의 head를 가지는 반면, DETR는 두 개의 head를 가집니다. Transformer는 다음 token에 대한 class probability를 예측하기 때문에 하나의 linear layer를 가지는 반면, DETR은 이미지 내 객체의 bounding box와 class probability를 예측하기 때문에 각각을 예측하는 두 개의 linear layer를 가집니다.
Method
본 논문에서는 object detection 시 direct set prediction을 위해 두 가지 요소가 필수적이라고 합니다.
-
predicted bounding box와 ground truth box 사이의 unique matching을 가능하도록 하는 set prediction loss
-
한 번의 forward pass로 object model 사이의 relation을 예측하는 architecture
Object detection set prediction loss
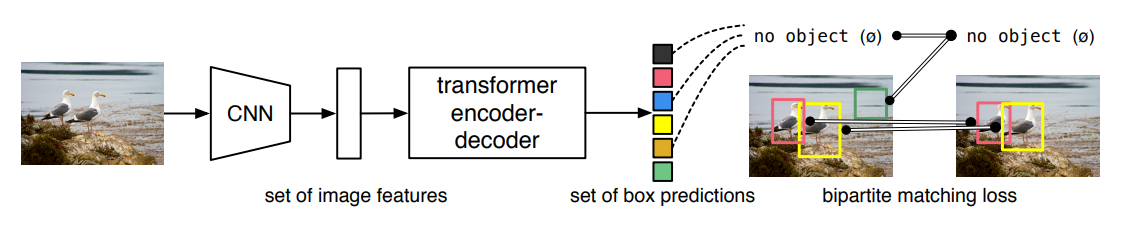
loss를 계산하는 과정은 두 단계로 구분됩니다. 첫 번째로, predicted bounding box와 ground truth box 사이의 unique한 matching을 수행하는 과정입니다. 두 번째 단계에서는 matching된 결과를 기반으로 hungarian loss를 연산합니다.
Hungarian algorithm은 두 집합 사이의 일대일 대응 시 가장 비용이 적게 드는 bipartite matching(이분 매칭)을 찾는 알고리즘
System Architecture

- Backbone + Transformer + MLP 구조로 이루어져 있다
- transformer encoder는 image feature vector를 입력으로 받는다. image feature vector는 CNN으로 부터 오는데 AvgPooling Layer를 거치기 전의 input이미지의 stride 32 크기를 가진 feature map를 가져온다. 예를 들어 input image resolution이 224x224 라면 7x7 feature map을 가져오게 된다. 그러나 transformer encoder는 3차원 tensor가 아닌 2차원으로 이루어진 sequence를 입력으로 받기 때문에 flatten 하는 과정이 필요하다. 즉 49개의 feature vector를 encoder에 넣게된다
- Decoder는 object query를 입력으로 받게되는데 이 때 object 는 DETR이 prediction하고자 하는 모든 object class를 의미한다.
Transformer
- Attention을 통해 전체 이미지의 문맥 정보를 이해
- 이미지 내 각 인스턴스의 상호작용(Interaction) 파악 용이
- 큰 Bounding Box에서의 거리가 먼 픽셀 간의 연관성 파악 용이
Transformer Encoder
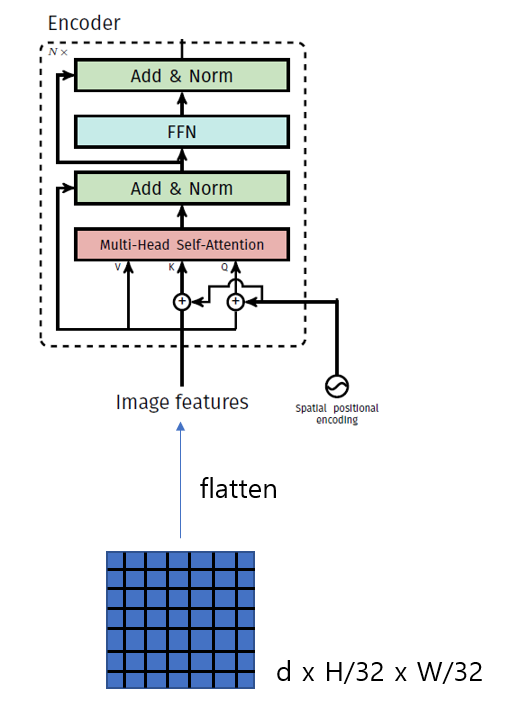
- 이미지의 특징(Feature) 정보를 포함하고 있는 각 픽셀 위치 데이터를 입력받아 인코딩 수행
Transformer Decoder
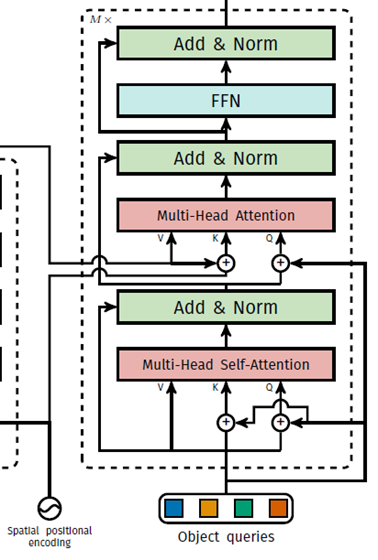
- N개의 Object query를 초기 입력으로 받으며 인코딩된 정보를 활용
- 각 Object query는 이미지 내 서로 다른 고유한 인스턴스를 구별
Group DETR
- End-to-End 방식으로 여러 개의 Positive 개체 쿼리를 지원
- 중복 예측을 피하기 위해 Group DETR에서는 그룹 별 One-to-Many를 도입
- One-to-One : 하나의 Ground Truth 객체는 정확히 하나의 Positive Sample에만 할당될 수 있다.
- One-to-Many : 각 Ground Truth 객체는 여러 Positive Sample에 할당될 수 있다.
One-to-Many 할당의 바람직하지 않은 효과 중 하나는 중복된 예측을 생성하여 Non-maximum suppresion(NMS)와 같은 후처리 단계가 제거되는 것을 방지한다는 것이다.
DETR은 One-to-One 할당을 채택하여 End-to-End 훈련을 달성하였지만, 수렴 속도가 느린 문제점이 있다.

총 개체 쿼리 수와 Ground Truth 개체당 일치하는 긍정적인 개체 쿼리 수를 점차적으로 늘렸을 떄, 총 개체 쿼리 수와 일치하는 Positive 개체 쿼리 수가 증가할 수록 탐지 성능이 크게 향상되는 반면, 총 개체 쿼리 수만 늘리면 약간의 이득만 얻을 수 있다는 것을 확인할 수 있다.
Training Process
- K개 그룹의 객체 쿼리 채택
- 동일한 매개변수를 사용하여 각 객체 쿼리 그룹에 대해 디코더 셀프 어텐션을 수행
- 각 그룹에 대해 One-to-One 할당을 수행하여 각 Ground Truth 개체에 대해 K개의 긍정적인 개체 쿼리로 이어짐.
이 설계는 빠른 훈련 수렴을 달성하고 중복 예측을 제거하며 엔드투엔드 훈련을 가능하게 한다.
추론에 하나의 개체 쿼리 그룹만 사용하고 아키텍처나 프로세스를 수정하지 않으므로 원래 모델에 비해 추가 비용이 발생하지 않는다.
RELATED WORKS
- Label Assignment in Object Detection.
- Accelerating DETR Training
Original DETR vs Our Group DETR
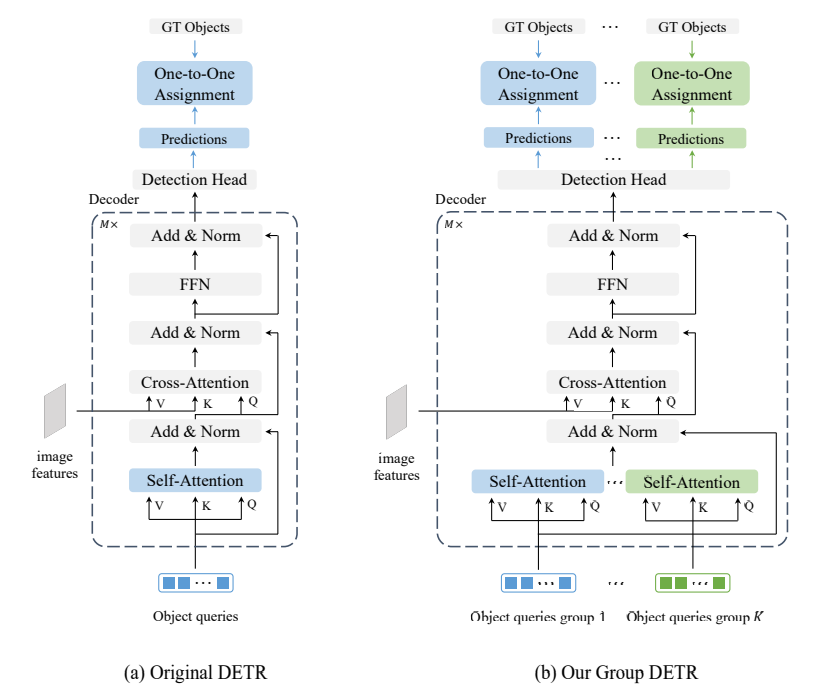
우리는 K개의 쿼리 그룹을 디코더에 제공하고 공유 매개변수를 사용하여 각 쿼리 그룹에 대해 self-attention을 수행한다. 그런 다음 각 그룹에 대해 일대일 할당을 수행한다.
Group-wise One-to-Many Assignment
중복 예측을 피하면서 긍정적인 쿼리 수를 늘리기 위해 그룹별 일대다 할당 전략을 제안한다. 각 gt 개체와 일치시키려는 긍정적인 쿼리 수 K가 주어지면 K개의 쿼리 그룹(원본 그룹 포함)을 생성한다.
총 K개의 그룹은 병렬로 디코더에 공급되지만, 동일한 매개변수로 디코더 self-attention을 수행할 때 각 그룹은 다른 그룹과 상호 작용하지 않는다. 그런 다음 일대일 할당이 각 그룹의 출력에 독립적으로 적용되고 K개의 일치 결과를 얻을 수 있다.
CONCLUSION
우리는 여러 긍정적인 개체 쿼리를 지원하기 위해 그룹 DETR을 제시합니다. 그룹 DETR
엔드투엔드 개체 감지를 달성하기 위해 그룹별 일대다 레이블 할당을 도입합니다. 세부적으로는 다수의 긍정적 객체 쿼리를 다수의 독립적인 그룹으로 분리하고 각 그룹에서 일대일 할당을 수행합니다.
CO-DETR
- end-to-end 장점을 유지하면서 기존의 detector보다 우수한 DETR 기반 detector를 만들려고 하였다. 이 문제를 해결하기 위해 덜 positive한 query를 탐색하는 일대일 집합 매칭의 직관적인 단점에 중점을 두었다.
-Co-DETR의 핵심 통찰력은 다목적 일대다 레이블 할당을 사용하여 인코더와 디코더 모두의 학습 효율성과 효과를 개선하는 것이다.
RELATED WORKS
- One-to-many label assignment
- One-to-one set matching
Method
- 표준 DETR 프로토콜에 따라 입력 이미지가 backbone과 인코더에 공급되어 latent feature를 생성한다. 여러 사전 정의된 object query는 나중에 cross-attention을 통해 디코더에서 상호 작용한다. Co-DETR을 도입하여 인코더의 feature 학습과 디코더의 attention 학습을 공동 하이브리드 할당 학습 방식과 맞춤형 positive query 생성을 통해 개선한다.
Collaborative Hybrid Assignments TrainingPermalink
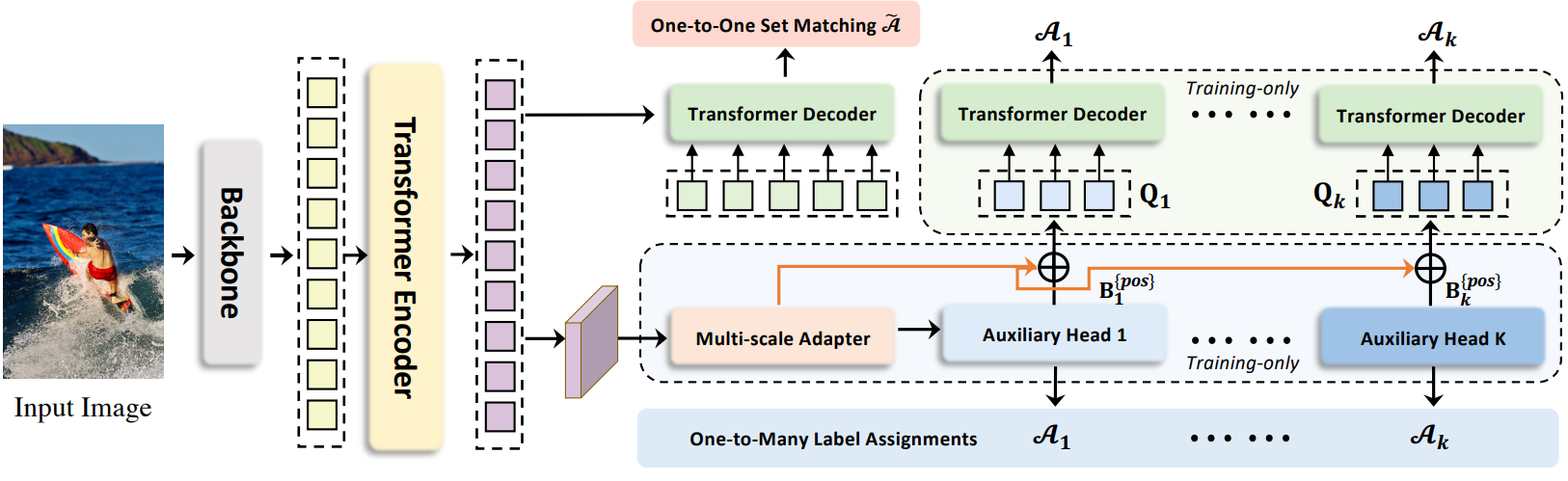
디코더에서 적은 수의 positive query로 인해 발생하는 인코더 출력에 대한 희박한 supervision을 완화하기 위해 다양한 일대일 레이블 할당 패러다임 (ex. ATSS, Faster R-CNN)이 있는 다목적 보조 head를 통합한다.
Customized Positive Queries Generation
일대일 집합 매칭 패러다임에서 각 ground-truth 박스는 supervised 타겟으로 하나의 특정 query에만 할당된다. Positive query가 너무 적으면 transformer 디코더에서 비효율적인 cross-attention 학습이 발생한다.이를 완화하기 위해 충분한 맞춤형 positive query를 정교하게 생성한다
인코더의 Supervision 강화
직관적으로 positive query가 너무 적으면 각 ground-truth에 대한 regression loss에 의해 하나의 query만 supervise되므로 supervision이 희박해진다. 일대다 레이블 할당 방식의 positive sample은 latent feature 학습을 향상시키는 데 도움이 되는 더 많은 localization supervision을 받는다. 저자들은 희박한 supervision이 모델 학습을 방해하는 방법을 자세히 알아보기 위해 인코더에서 생성된 latent feature를 자세히 조사하였다. 인코더 출력의 discriminability score를 양자화하기 위해 IoF-IoB 곡선을 도입하였다 (IoF: 전경 교차, IoB: 배경 교차).
Hungarian 매칭의 불안정성을 줄여 Cross-attention 학습을 개선
Hungarian 매칭은 일대일 집합 매칭의 핵심이다. Cross-attention은 positive query가 풍부한 개체 정보를 인코딩하는 데 도움이 되는 중요한 task이다. 이를 위해서는 충분한 학습이 필요하다. 동일한 이미지의 특정 positive query에 할당된 ground-truth 정보가 학습 과정 중에 변경되기 때문에 Hungarian 매칭은 제어할 수 없는 불안정성을 도입한다.
Comparison with other methodsPermalink
-
Group-DETR, H-DETR, SQR은 중복된 그룹과 반복된 ground-truth 박스의 일대일 매칭을 통해 일대다 할당을 수행한다. Co-DETR은 여러 공간 좌표를 각 ground-truth에 대한 positive로 명시적으로 할당한다. 따라서 이러한 조밀한 supervision 신호는 latent feature map에 직접 적용되어 더 식별할 수 있다. 반대로 Group-DETR, H-DETR, SQR에는 이 메커니즘이 없다. 더 positive한 query가 이러한 상대에 도입되었지만 Hungarian 매칭에 의해 구현된 일대다 할당은 여전히 일대일 매칭의 불안정성 문제로 어려움을 겪고 있다.
-
본 논문의 방법은 기존 일대다 할당의 안정성으로부터 이점을 얻고 positive query와 ground-truth 박스 사이의 특정 매칭 방식을 상속한다. Group-DETR과 H-DETR은 일대일 매칭과 기존의 일대다 할당 사이의 상보성을 밝히지 못한다. 본 논문은 전통적인 일대다 할당과 일대일 매칭을 사용하여 detector에 대한 정량적 및 정성적 분석을 최초로 제공하였다. 이를 통해 차이점과 보완성을 더 잘 이해할 수 있으므로 추가로 전문화된 일대다 디자인 경험 없이 기존 일대다 할당 디자인을 활용하여 DETR의 학습 능력을 자연스럽게 향상시킬 수 있다
-
디코더에 negative query가 도입되지 않는다.Permalink
중복된 object query는 필연적으로 디코더에 대한 많은 양의 negative query와 GPU 메모리의 상당한 증가를 가져온다. 그러나 본 논문의 방법은 디코더에서 positive 좌표만 처리하므로 메모리를 덜 사용한다.
- 참고 문헌
DETR
-> End-to-End Object Detection with Transformers, https://arxiv.org/pdf/2005.12872.pdf
-> https://powerofsummary.tistory.com/205
-> https://herbwood.tistory.com/26
Group DETR
-> GROUP DETR: FAST DETR TRAINING WITH GROUPWISE ONE-TO-MANY ASSIGNMENT, https://arxiv.org/pdf/2207.13085.pdf
CO-DETR
-> DETRs with Collaborative Hybrid Assignments Training,
https://arxiv.org/pdf/2211.12860v5.pdf
-> https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/co-detr/
