YOLOv1 ~ YOLOv8
-
YOLOv1 : 2016년에 발표된 최초 버전으로, 실시간 객체 검출을 위한 딥러닝 기반의 네트워크
-
YOLOv2 : 2017년에 발표된 두 번째 버전으로, Anchor Box가 도입되었으며, K-means로 Opti- mal한 크기와 개수를 정해줌. 또한 FC Layer가 사라져, 다양한 Size의 Input을 넣을 수 있게 됨.
-
YOLOv3 : 2018년에 발표된 세 번째 버전으로, 네트워크 구조와 학습 방법을 개선하여 객체 검출의 정확도와 속도를 모두 개선, YOLO의 고질적인 문제인 Small Object를 잘 못 찾는다는 문제점을 3 Scale로 예측하면서 크게 해소.
-
YOLOv4 : 2020년 4월에 발표된 네 번째 버전으로, Mosaic, MixUp 등 다양한 Augmentation을 적용하여 성능을 향상시킴. 또한 CSP Layer를 활용하여 정확도는 향상시키되, 속도는 줄이는데 큰 역할. SPP와 PAN 등의 기술이 적용되어 더욱 정확한 객체 검출과 더 높은 속도를 제공
-
YOLOv5 : 2020년 6월에 발표된 버전으로 YOLOv4와 비교하여 객체 검출 정확도에서 10% 이상 향상되었으며, 더 빠른 속도와 더 작은 모델 크기를 가짐. YOLO v4까지는 DarkNet 기반 Backbone을 사용했으나, YOLO v5부터 Pytorch로 구현된 Backbone을 사용.
-
YOLOv7 : 2022년 7월 발표된 버전으로, 훈련 과정의 최적화에 집중하여 훈련 cost를 강화화는 최적화된 모듈과 최적 기법인 trainable bag-of-freebies를 제안
-
YOLOv6 : 2022년 9월 발표된 버전으로, 여러 방법을 이용하여 알고리즘의 효율을 높이고, 특히 시스템에 탑재하기 위한 Quantization과 distillation 방식도 일부 도입하여 성능 향상
-
YOLOv8 : 2023년 1월 발표된 버전으로, YOLO 모델을 위한 완전히 새로운 리포지토리를 출시하여 개체 감지, 인스턴스 세분화 및 이미지 분류 모델을 train하기 위한 통합 프레임워크로 구축됨
-
20년 7월 PP-YOLO, 21년 2월 Scaled-YOLOv4, 21년 5월 YOLOR, 21년 7월 YOLOX라는 모델이 나왔다.
YOLOv1 (2016)
-
통합인식(Unified Detection) : 기존 Bounding Box 잡은 후 -> 탐지된 Bounding Box에 대해 분류 수행하는 2 Stage Detection 이었지만 YOLOv1은 Bounding Box 조정 + 분류를 동일한 신경망 구조를 통해 동시에 실행하는 1 Stage Detection 이기 때문에 학습 파이프 라인이 기존 Detection 모델들에 비해 간단하기 때문에 학습과 예측의 속도가 빠름
-
n모든 학습 과정이 이미지 전체를 통해 일어나기 때문에 단일 대상의 특징 뿐만 아니라 이미지 전체의 맥락을 학습하고, 대상의 일반적인 특징을 학습하기 때문에 다른 영영으로의 확장에서도 뛰어난 성능
-
S x S 크기의 Grid Cell로 Input Image를 분리하고, Cell 마다 B개의 Bounding boxes, Confidence score, Class probabilities를 예측 -> 인접한 Cell이 같은 객체를 예측하는 Bounding Box를 생성하는 문제 발생 -> Confidence score와 IOU를 계산하여 가장 높은 Confidence score의 Bounding Box 선택 (NMS)
YOLOv1의 한계:
- 여러 물체들이 겹쳐 있으면 제대로 된 예측이 어렵
- 물체가 작을수록 정확도 감소
- Bounding Box 형태가 data를 통해 학습되므로 새로운 형태의 Bounding Box의 경우 정확히 예측X
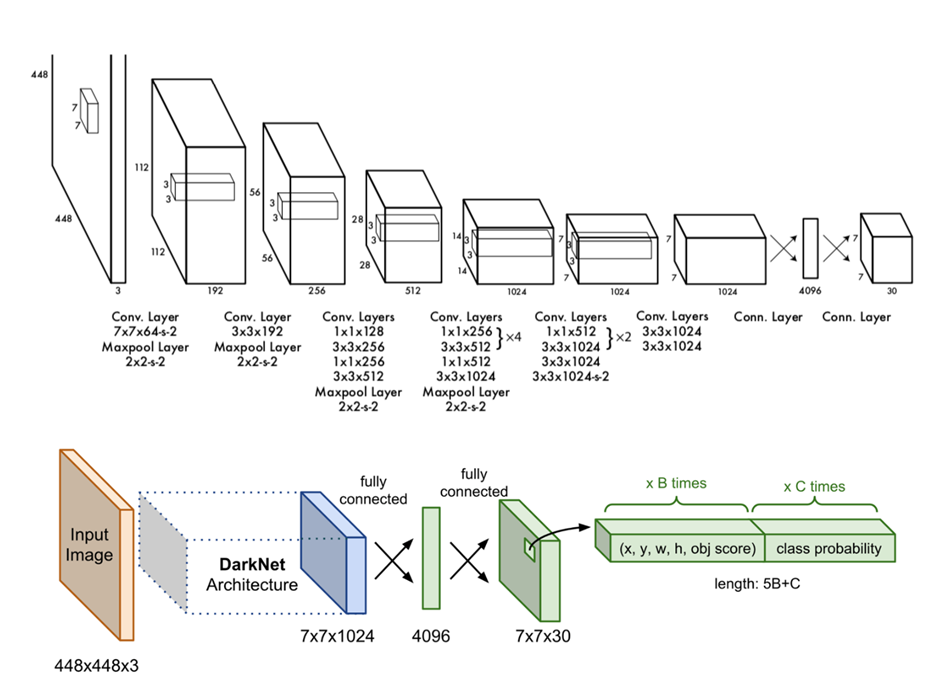
YOLOv1 Architecture
- Image -> CNN -> FC -> PT(Prediction Tensor)
- 24개의 Conv layer와 2개의 FC layer로 구성되어 있다. Darknet network라고 부르며, 224x224 ImageNet dataset으로 Pre-trained된 network를 사용한다. 이후 448x448 이미지를 Input Image로 받아 1x1 Conv layer와 3x3 Conv layer의 교차를 통해 Parameter 감소시킨다.
- Final Output : S x S x ( B * 5 + C ) [ S : Num of Cell, B : Num of Bounding boxes, C : Num of Classes]
YOLOv1 Loss
- MULTI Loss = Coordinate Loss + Confidence-Score Loss + No-object Penalties + Classification Loss
- Coordinate Loss: x, y, w, h, Confidence-Score의 값이 예측값과 Ground-truth 값의 차를 구해 모두 더함
- No-object Penalties: 찾지 못한 물체들에 대한 패널티를 부여합니다. 다시 말해 물체로 찾아냈어야 하는데 찾지 못한 인덱스에 대해 C의 값의 차를 구해 loss에 더함
- Classification Loss: 마지막 단락에서 모든 물체가 있다고 판단된 인덱스들에 대해 모든 클래스들에 대해 예측 값과 실제 값의 차를 구해서 더해줍니다.
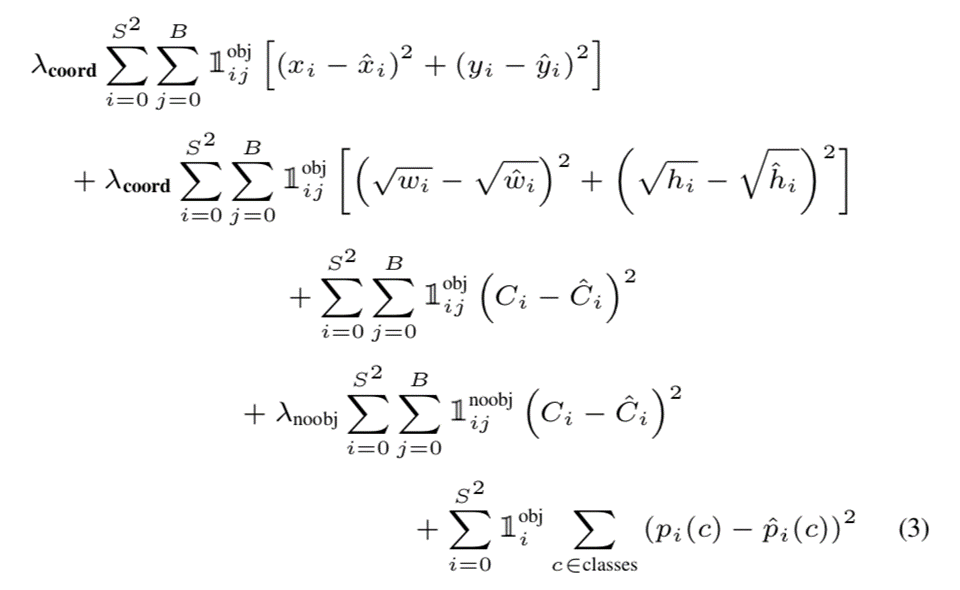
YOLOv2 (2017)
-
Batch Normalization 적용: 기존 모델에서 Dropout Layer를 제거하고 Convolution Layer에 Batch Normalization을 적용하였다.
-
High Resolution Classifier: YOLOv1은 VGG16 모델을 기반으로 224x224 크기의 해상도로 학습을 하고, 448x448 크기의 이미지에 대해서 Object Detection을 수행하도록 설계되어 성능이 좋지 않았다. YOLOv2에서는 학습 전 이미지 분류 모델을 큰 해상도의 이미지에 대해 fine-tuning 단계를 거쳐 고해상도 이미지로 CNN 신경망을 학습 할 수 있었다.
-
Convolutional With Anchor Boxes: 기존의 YOLOv1은 24개의 Conv layer와 마지막 단락의 2개의 Fully Connected layer로부터 Bounding Box의 좌표 정보를 예측했다. YOLOv2는 마지막 단의 Fully Connected layer을 떼어내고 Convolutional Network 형태로 Prediction을 계산합니다. 또한, Faster R-CNN에서의 Anchor Box의 개념을 도입하여 Bounding Box의 좌표를 예측하기 보다는 사전에 정의한 앵커 박스에서 offset을 예측하여 더욱 간단하게 학습을 할 수 있게 되었다. Anchor Box의 핵심은 사전에 크기와 비율이 모두 결정되어 있는 박스를 전제로, Dimension Clustering(k-means Clustering)을 통해 Ground Truth Box 와 가장 유사한 Optimal Anchor box를 탐색함으로써 데이터셋 특성에 적합한 Anchor Box를 생성한다.
클러스터링 개수 k가 커지면 높은 정확도를 얻을 수 있지만 속도가 느려지기 때문에 YOLOv2에서는 k=5라는 값을 사용합니다.(= Anchor Box 5개 사용) -
Direct location prediction: YOLOv2에서는 앵커 박스에 따라 하나의 셀에서 5차원 벡터로 이루어진 바운딩 박스를 예측하며, 경계 박스가 그리드 Cell에서 벗어나지 않도록 제약을 둔다. 기존의 YOLOv1가 그리드의 중심점을 예측하였다면 v2에서는 Left Top 꼭지점으로부터 얼마나 이동하는지 예측하게 된다.
-
Fine-Grained Features: YOLOv2는 13x13 Feature Map을 출력한다. 하지만 13x13의 크기는 작은 물체 검출에 대해서 약하다는 단점이 있다. 이와 같은 문제 해결을 위해 상위 레이어의 Feature Map을 하위 Feature Map에 합쳐주는 Passthrough Layer를 도입했다. 이전 Layer의 26x26 Feature Map을 가지고 와서 13x13 Feature Map에 이어 붙인다. 크기가 달라 그냥 이어 붙일 수 없으므로 26x26x512의 Feature Map을 13x13x(512*4)의 Feature Map으로 변환합니다. 26x26 크기의 Feature Map에 고해상도 특징(지역적 특성)이 담겨 있기때문에 이를 활용 하는 것이다.
-
Multi-Scale Training: YOLOv2는 작은 물체도 Detection 하기 위해 여러 스케일의 이미지를 학습하도록 하였다. 10 epoch 마다 {320, 352, …, 608} 과 같이 32 픽셀 간격으로 입력 이미지의 해상도를 바꿔주며 학습을 진행한다. 따라서 다양한 입력 크기에도 예측을 잘할 수 있다.
YOLOv2 Architecture
- YOLOv2는 기존의 Darknet을 개선한 Darknet 19 신경망을 구축하여 이용했습니다. VGG-16 신경망에서 대부분의 가중치가 쓰인 FC layer를 제거하여 1✕1 Convolution Layer로 대체하였다. Global Average Pooling을 사용해 가중치 파라미터 수를 줄여 때문에 훨씬 빠른 속도로 detection이 가능하게 되었다.
- Anchor Box 도입으로 인해 학습이 안정화되었다.
- YOLOv1에서는 Grid 당 2개의 B-Box 좌표를 예측하는 방식이었다면 YOLOv2에서는 Grid 당 5개의 Anchor Box를 찾는다.

YOLOv3 (2018)
- Multilabel Classification: 한 물체에 대해 Multi Class Label을 가질 수 있다. 그러나 Softmax는 한 박스 안에서 여러 객체가 존재할 경우 적절하게 포착할 수 없었다. 따라서 v3에서는 이것이 가능하도록 마지막에 Loss function을 Softmax가 아닌 모든 Class에 대해 Sigmoid를 취해 각 Class별로 Binary Classification을 하도록 바꾸었다(Binary cross entropy)
YOLOv3 Architecture
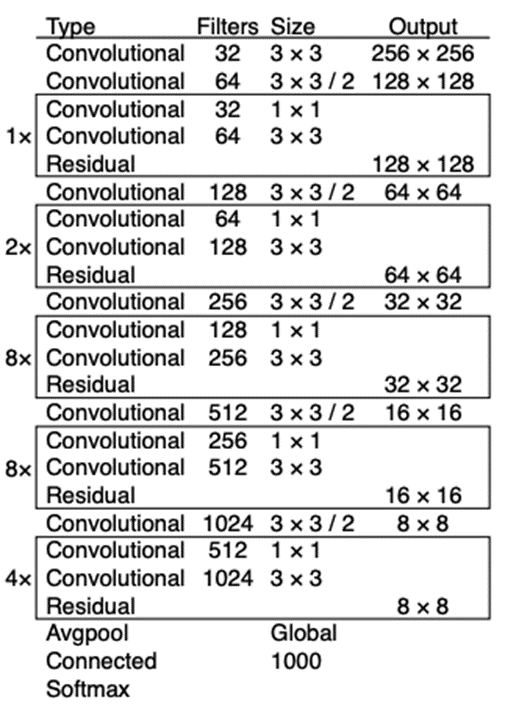
- Backbone 네트워크를 Darknet-19에서 Darknet-53로 변경하였다.
- 이전 Darknet-19에 ResNet에서 제안된 Skip Connection 개념을 적용하고 Pooling layer를 삭제하였다.
- SSD 모델의 Multi-Scale Feature Layer와 Retinanet의 FPN(Feature Pyramid Network)과 유사한 기법을 적용하였다. (SSD의 Multi-Scale Feature Layer는 서로 다른 크기의 Feature Map에 각 포인트마다 Object Detection을 수행해주는 기법)
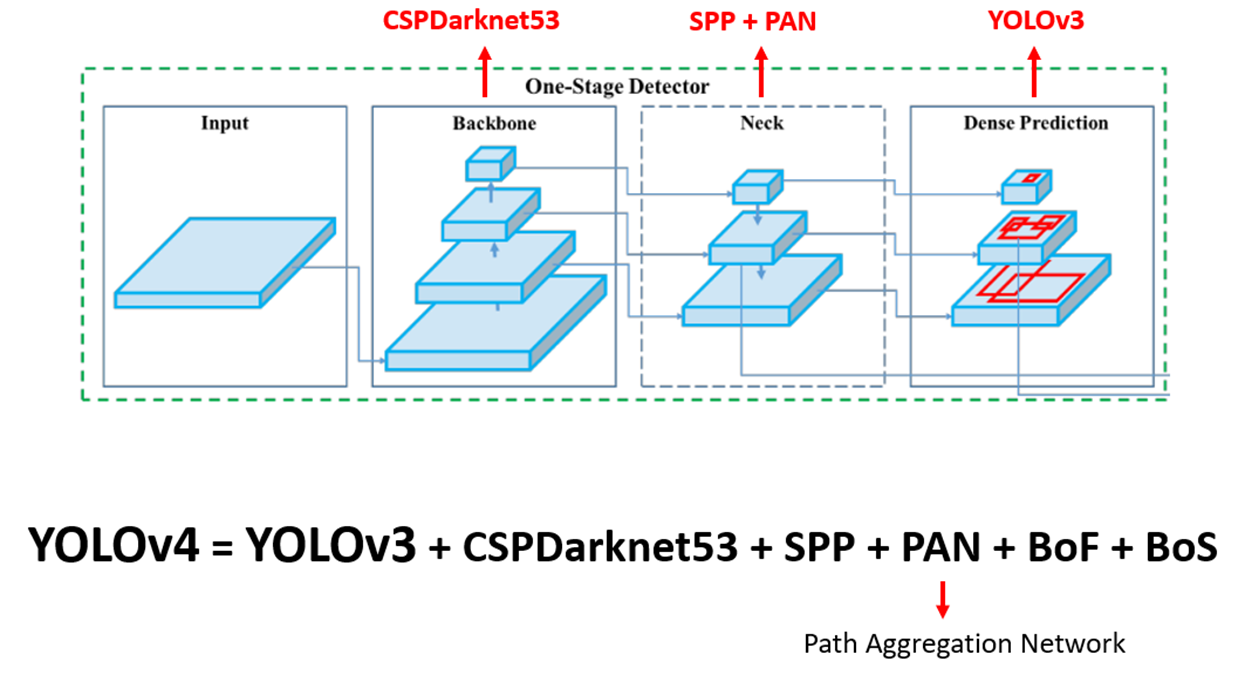
YOLOv4 (2020.04)
-
기존 YOLO 시리즈의 작은 객체 검출 문제를 해결하고자 했다.
-
YOLO v4 = YOLO v3 + CSPDarknet53(Backbone) + SPP + PAN + BoF + BoS
-
다양한 작은 Object들을 잘 검출하기 위해 Input 해상도를 크게 사용하였다. 기존에는 224, 256 등의 해상도를 이용하여 학습을 시켰다면, YOLOv4에서는 512을 사용하였다.
-
Receptive field를 물리적으로 키워 주기 위해 Layer 수를 늘렸으며, 하나의 Image에서 다양한 종류, 다양한 크기의 Object들을 동시에 검출하려면 높은 표현력이 필요하기 때문에 Parameter 수를 키워주었다.
-
YOLOv4는 다양한 데이터셋을 이용한 데이터 증강 기술과 Quantization 기술도 함께 도입하여 더 높은 성능과 더 낮은 모델 크기를 가지게 되었다.
YOLOv4 Architecture
- 정확도를 높이는 반면에 있어서의 속도 문제는 아키텍처의 변경을 통해 해결하였다.
- FPN(Feature Pyramid Network)과 PAN(Path Aggregation Network) 기술을 도입했다.
- CSP (Cross Stage Partial connections) 기반의 Backbone 연결과 SPP (Spatial Pyramid Pooling) 등의 새로운 네트워크 구조를 도입하여 성능을 향상하였다.
- Bag of Freebies (BOF)
BOF는 inference cost의 변화 없이 (공짜로) 성능 향상(better accuracy)을 꾀할 수 있는 딥러닝 기법들이다. 대표적으로 데이터 증강(CutMix, Mosaic 등)과 BBox(Bounding Box) Regression의 loss 함수(IOU loss, CIOU loss 등)이 있다. - Bag of Specials (BOS)
BOS는 BOF의 반대로, inference cost가 조금 상승하지만, 성능 향상이 되는 딥러닝 기법들이다. 대표적으로 enhance receptive filed(SPP, ASPP, RFB), feature integration(skip-connection, hyper-column, Bi-FPN) 그리고 최적의 activation function(P-ReLU, ReLU6, Mish)이 있다. - FPN: 이 방법은 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지하는 방법이다.
- PAN: 하위 계층 정보를 상위로 더 쉽게 전파할 수 있도록 하는 방법이다.
- CSP(Cross-Stage Partial connections) : 기존의 CNN 네트워크의 연산량을 줄이는 기법으로, 학습할 때 중복으로 사용되는 기울기 정보를 없앰으로써 연산량을 줄이면서도 성능을 높인다.
- SPP는 local spatial bins를 pooling함으로써 spatial 정보를 유지할 수 있다. 여기에서 spatial bins란, spatial pyramid(11 회색, 44 녹색, 16*16 파란색)에서 1칸짜리 공간을 의미한다. SPP를 이용함으로써, image size는 어떤 크기든 사용할 수 있다. 이것은 임의의 aspect ratiois와 scales을 사용할 수 있게 한다. 따라서 우리는 어떤 scale로든 input image를 resize할 수 있다.
- Bag of Freebies (BOF)
YOLOv5 (2020.06)
-
Yolo v5는 Yolo v4와 마찬가지로 CSPNet을 이용하는데, BottleneckCSP를 사용하여 각 계층의 연산량을 균등하게 분배해서 연산 Bottleneck을 없애고 CNN layer의 연산 활용을 업그레이드 시켰다.
-
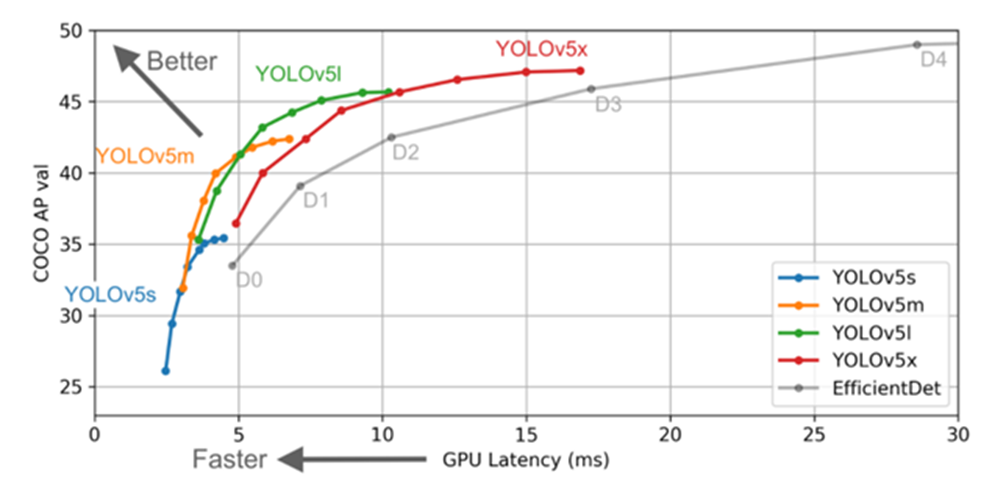
다른 Yolo 모델들과 다른 점은 Backbone을 Depth multiple과 Width multiple를 기준으로 하여 크기별로 yolo v5 s, yolo v5 m yolo v5 l, yolo v5 x로 나눈다는 것이다. 이는 아래 그림과 같이 yolo v5 s가 가장 빠르지만 정확도가 비교적 떨어지며 yolo v5 x는 가장 느리지만 정확도는 향상된다.
YOLOv7 (2020.07)
-
Real-time Object Detection 이면서 Inference Cost를 증가시키지 않고도 정확도를 향상시킬 수 있는 Trainable Bag-of-freebies 방법을 제안하는데, 해당 방법들이 적용된 모델이 YOLOv7이다.
-
Model reparameterization: 학습 시 여러 개의 레이어들을 학습하고 Inference시에는 해당 레이어들을 하나의 레이어로 Fusing하였다.
-
Label assignment: Ground truth를 그냥 사용하는 것이 아니라 모델의 Prediction, Ground truth의 Distribution을 고려하여 새로운 Soft Label 생성한다.
-
Parameters와 Computation을 효과적으로 활용할 수 있는 Real-time Object Detector를 위한 ‘Extend' 및 ‘Compound Scaling' 방법을 제안한다.
-
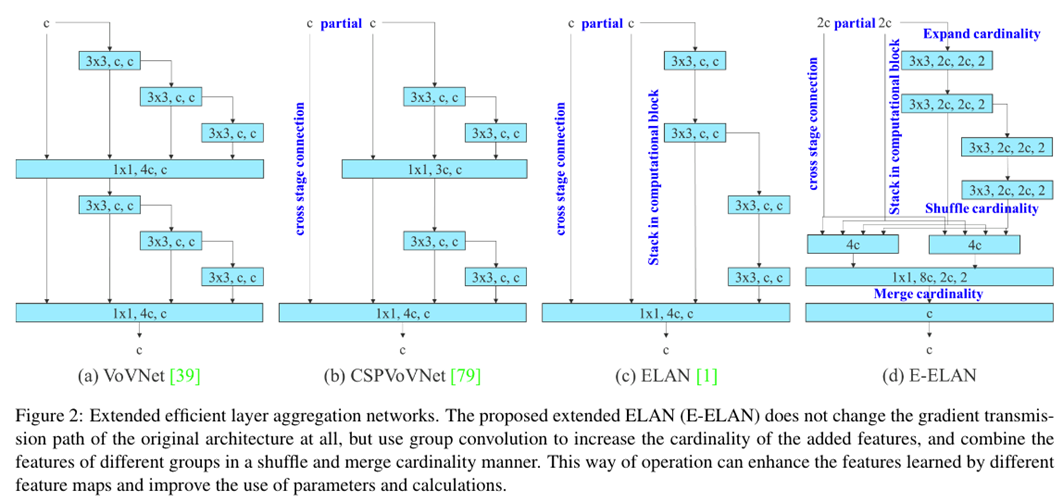
기존 연구들에서 제안된 ELAN은 Computation block을 어느정도 많이 쌓아도 잘 학습되지만 무한대 가까이로 쌓을 경우 Parameter Utilization이 낮아지는 문제가 있었다. 따라서 YOLOv7에서는 마음껏 쌓아도 학습이 잘되도록 하기 위해 E-ELAN을 제안하였다.
YOLOv7 Architecture
- E-ELAN은 오직 Computational Block만 바뀌고(Scaling에 따라), Transition Layer는 절대 바뀌지 않음
- Expand, Shuffle, Merge Cardinality를 통해 Computational Block을 많이 쌓아도 학습능력이 뛰어남
- Process
- Computational Block들에 대해 Channel 수를 Multiplier 하는 Group Conv를 적용
- CSP로 나눠진 Feature와 Computational Block의 Output Feature들이 Shuffle 후 Concatenate됨
- Merge Cardinality 수행
YOLOv6 (2020.09)
-
Yolov6는 여러 방법을 이용하여 알고리즘의 효율을 높이고, 특히 시스템에 탑재하기 위한 Quantization과 Distillation 방식도 일부 도입하여 성능을 높혔다.
-
자기 증류 기법 수행 시 모든 학습 단계에서 학생 모델이 지식을 보다 효율적으로 학습할 수 있도록 교사와 레이블의 지식을 동적으로 조정 가능
-
RepOptimizer 및 채널 별 증류로 객체 탐지를 위한 양자화 체계를 개선하였다.
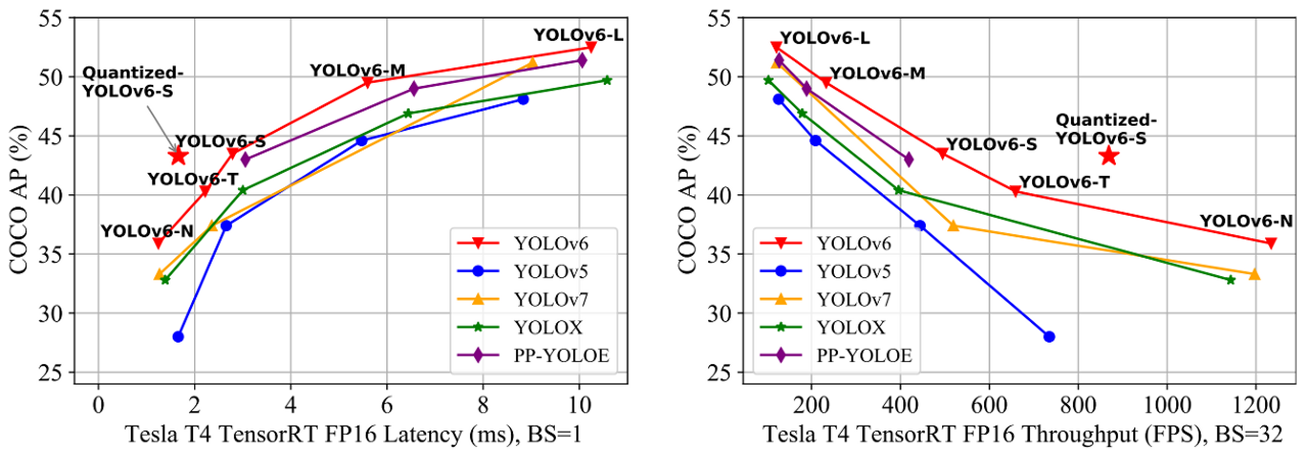
YOLOv6 Architecture
-
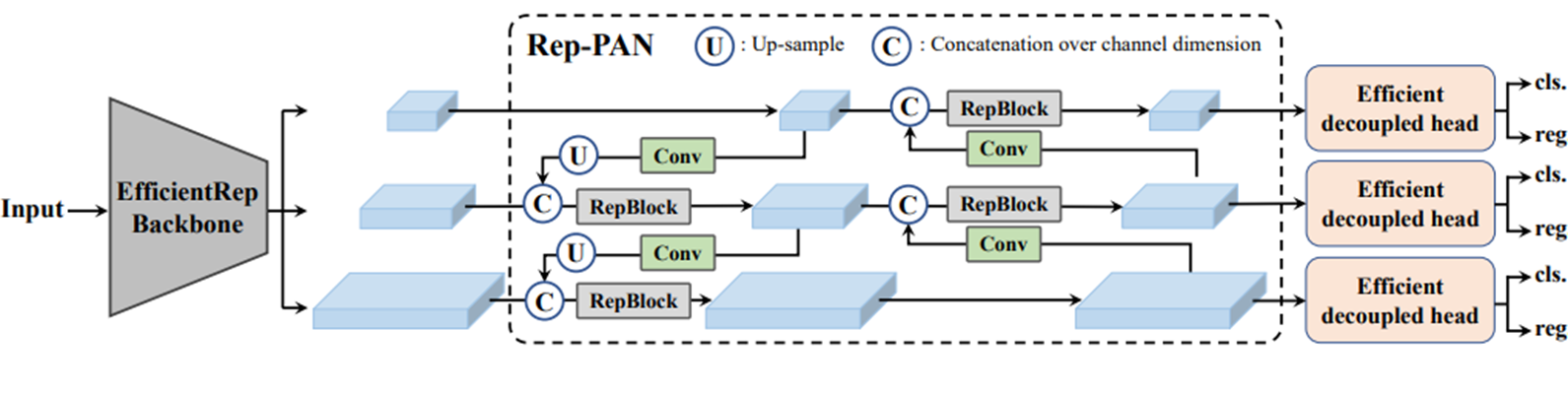
Backbone은 EfficientRep Backbone이 사용되었다. Neck 부분은 Rep-PAN이 사용되었다. Head는 Efficient Decoupled Head가 사용되었다.
-
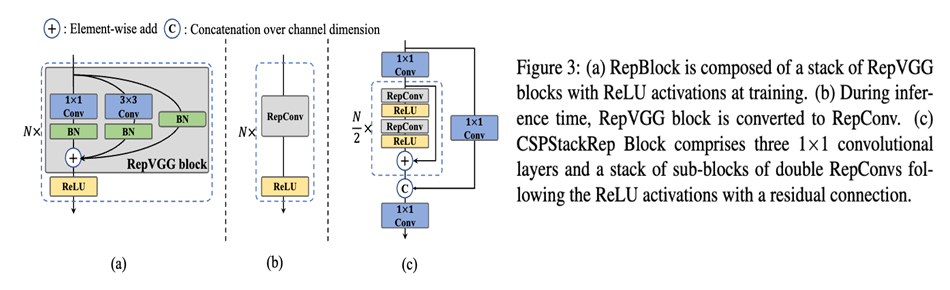
먼저 네트워크 구조에서 가장 핵심이 되는 기여는 CSPstackRep Block이다. CSPstackRep Block은 CSP(cross stage partial) + RepVGG 방식이다. 이 방식은 Backbone에 사용된다.
-
소형 모델은 일반 단일 경로 백본을 특징으로 하고 대형 모델은 효율적인 다중 분기 블록을 기반으로 구축
-
Backbone: 이전 YOLO Backbone보다 higher Parallelism을 자랑하는 EfficientRep 사용
-
Neck: RepBlocks으로 강화된 PAN 사용(더 큰 모델의 경우 CSPStackRep Block을 사용)
-
Head: Efficient Decoupled Head 사용 (from YOLOX)

다양한 크기의 모델을 수용하기 위해 2개의 재 매개변수가 가능한 Backbone과 Neck를 제시하였고, Head 부분에 하이브리드 채널 전략을 사용하는 Decoupled Head를 사용했습니다.
Backbone – EfficientREP: RepVGG는 작은 network에서는 inference time을 크게 증가시키지 않으면서 좋은 feature representation 능력을 가지고 있으나, 큰 네트워크에서는 single path로 인해 parameter와 computation cost가 크게 증가하는 단점이 있습니다.(Residual Connection을 없앴으므로) 따라서 작은 네트워크에서는 RepBlock을, 큰 네트워크에서는 CSPStackRep block을 사용했습니다.
Neck - RepPAN(RepBlocks으로 강화된 PAN): YOLO v4, v5 에서 사용된 PAN이 v6의 base가 되었고, 위에서 설명한 이유로 작은 모델에는 RepBlock을, 큰 모델에는 CSPStackRep을 사용하였고 이를 YOLO v6에서는 Rep-PAN이라고 칭합니다.
2021년에 나온 YOLOR에서 사용된 기법으로, 이전에는 Classification branch와 Regression branch가 parameter를 공유했으나 classification confidence와 localization accuracy 간의 misalignment가 있을 수 있어 두 branch를 각각 다른 head로 분리하였습니다.
YOLOv6 Loss
-
메인 스트림 앵커가 없는 객체 탐지 모델의 손실 함수에는 Classification Loss, Box Regression Loss, Object Loss가 포함된다.
-
New classification and regression losses.
-> Classification : VariFocal Loss
-> Regression : SIoU / GIoU Loss -
A self-distillation strategy: For the regression and classification tasks
-
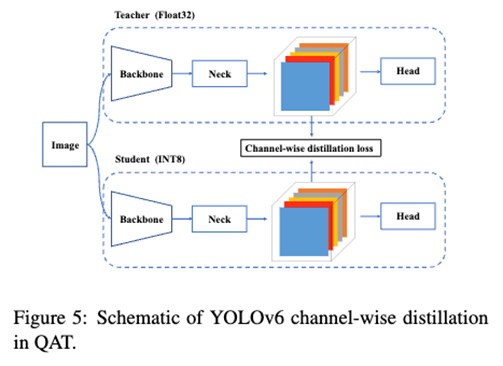
A quantization scheme: For detection using RepOptimizer and channel-wise distillation that helped to achieve a faster detector.
-
VariFocalLoss를 분류 손실로, SIoU/GIoU 손실을 회귀 손실로 선택하였습니다.
-
Classification Loss로는 VFL(VariFocal Loss)을 사용했다. 기존의 객체 검출에서 사용되던 Cross-Entropy 손실 함수는 모든 예측 박스에 대해 동일한 가중치를 부여하는 데 비해, VariFocalLoss는 예측 박스의 어려운 예제에 더 높은 가중치를 부여하여, 예측 오류가 큰 예제에 더 많은 비중을 둬서 모델 학습을 개선하려는 목적을 가지고 있습니다.
-
Box regression loss는 큰 모델에는 GIoU, 작은 모델에는 SIoU를 사용했습니다.
-
Object Loss는 FCOS(Fully Convolutional One-Stage Object Detection)라는 방식을 사용했지만, 부정적인 효과가 나타나기 때문에 최종적으로는 사용하지 않았습니다.
-
Post-training Quantization(PTQ)과 Quantization-aware Training (QAT) 두가지 방법을 사용하여 실험을 진행하였습니다. PTQ는 작은 Calibration Data Set 만을 사용해서 학습이 완료된 후에 Model 의 Weight를 Quantize 하는 방법이고, QAT는 Training Set을 사용해서 학습 도중에 Quantize 하였을 때를 시뮬레이션하여 최적의 weight를 구하는 것과 동시에 Quantization을 하는 방법입니다. QAT는 주로 Distillation과 함께 사용합니다.
-
YOLOv8 (2023.01)
-
YOLO 모델을 위한 완전히 새로운 리포지토리를 출시하여 개체 감지, 인스턴스 세분화 및 이미지 분류 모델을 train하기 위한 통합 프레임워크로 구축되었다.
-
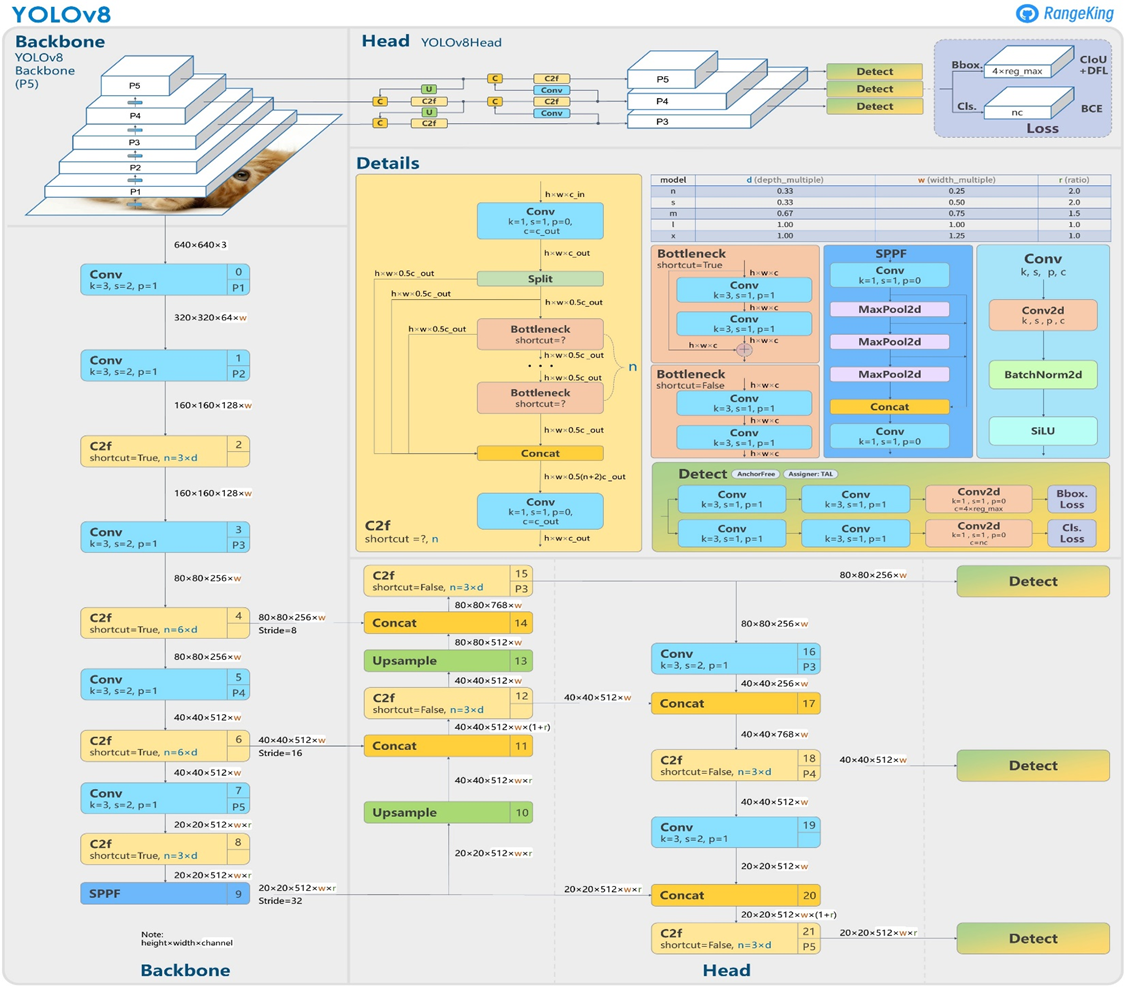
YOLOv5와 비교했을 때 변경된 사항
- C3 모듈을 C2f 모듈로 교체
- Backbone에서 첫 번째 6x6 Conv를 3x3 Conv으로 교체
- 두 개의 컨볼루션 레이어 삭제
- ConvBottleneck에서 첫 번째 1x1 Conv를 3x3 Conv로 교체
- 분리된 Head 사용 및 Objectness 분기 삭제
-
Anchor Free Detection
YOLOv8 Architecture
YOLOv6-v3.0(2023.01)
YOLOv6-v3.0 모델은 Real-time Object Detection의 SOTA 모델입니다.
-
Renew the neck of the detector with a Bi-directional Concatenation (BiC)
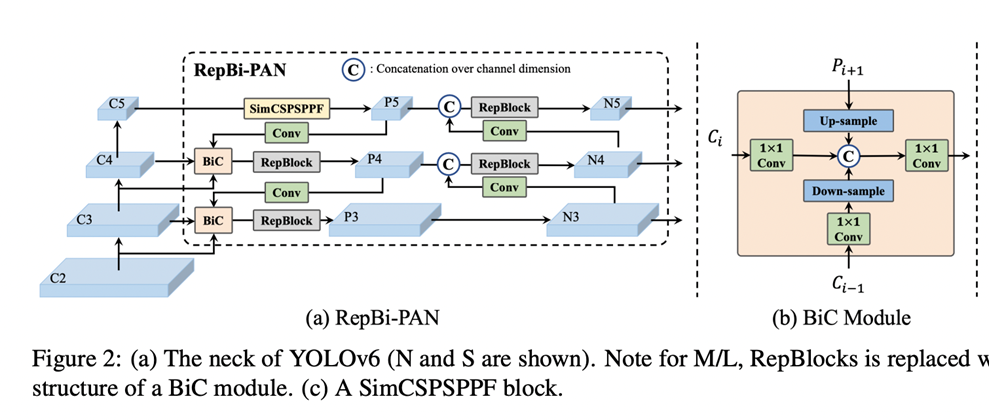
Detector의 neck을 BiC로 대체한다. 세개의 인접한 layer의 feature map을 Inregrate하기 위해 Bi-directional Concatenation(BiC) module을 제안합니다.
-
Anchor-Aided Training (AAT)
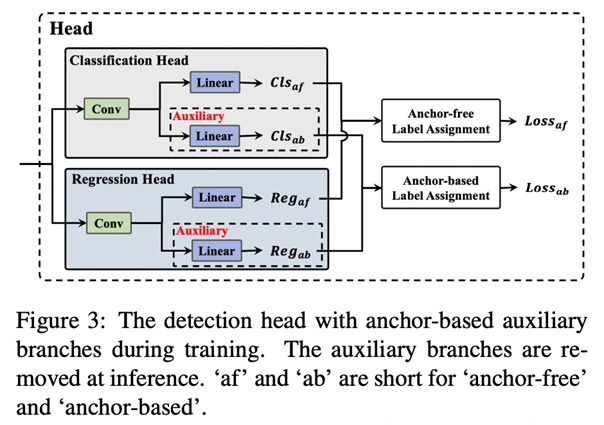
Inference efficiency에 영향을 주지 않으면서 Anchor-Based와 Anchor-Free의 장점을 모두 가져가기 위해 Anchor-Aided Training을 적용합니다. AAT는 Anchor-Based에서 오는 성능 향상을 위해 학습을 할 때 Anchor-Based를 사용하는 보조 브랜치를 함께 학습합니다. Inference할 때는 보조 브랜치를 제거하여 속도 감소를 피합니다.
-
Deepen YOLOv6 to have another stage in the backbone and the neck
Backbone과 Neck에 stage를 추가하여 모델의 깊이를 깊게 합니다.
-
New self-distillation strategy, in which the heavier branch for DFL is taken as an Enhanced Auxiliary Regression Branch
YOLOv6의 small model의 성능을 높이기 위해 새로운 self-distillation을 제안한다. 학습 중에는 regression branch의 DFL(Distribution Focal Loss)을 enhanced auxiliary regression branch로 바꾸어 사용하고 inference 시에는 속도를 위해 제거합니다.
YOLOv6-v3.0 Architecture
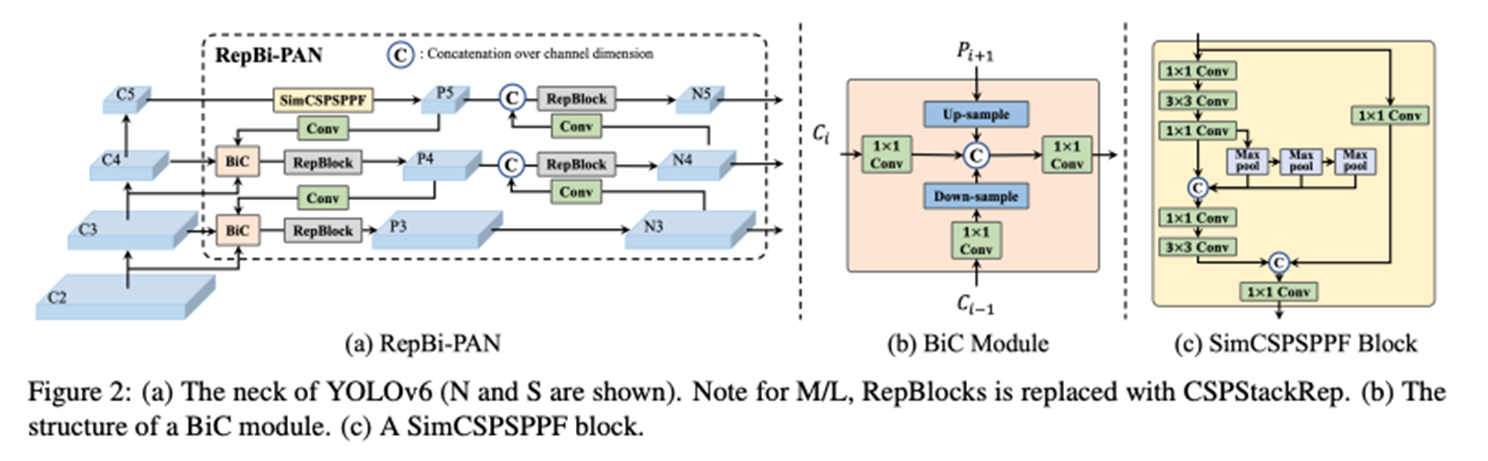
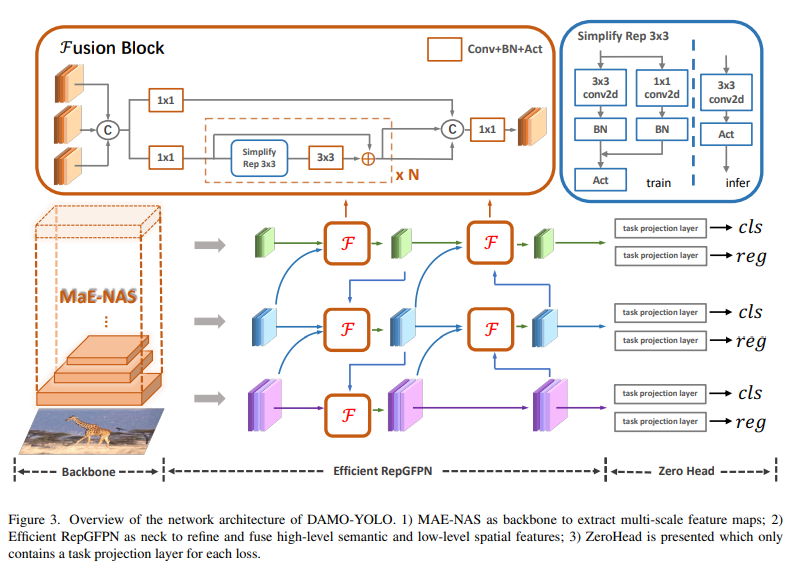
DAMO-YOLO(2023.04)
- MAE-NAS backbone
- Efficient RepGFPN neck
- ZeroHead
- AlignedOTA label assignment
- distillation enhancement.
DAMO-YOLO Architecture