InternImage
- Brand-New CNN-based Backbone Network
- Characteristics
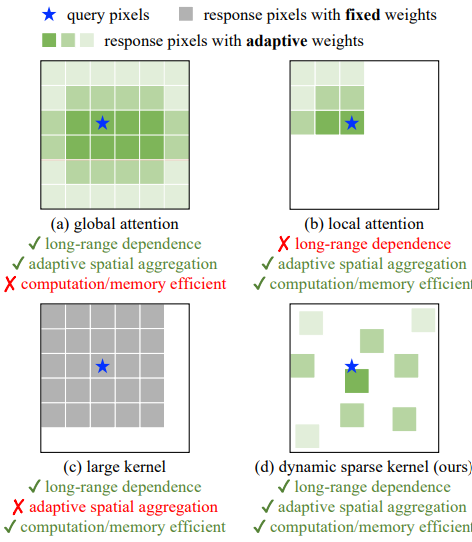
Dynamic sparse convolutional layer
- Only with 3x3 kernels
- Adaptive spatial aggregation
- Reduce inductive bias
- Low computational cost compared to large convolutional layers
Overall Architecture of ViT
Contributions
- 1st CNN-based backbone with more than 1 billion params.
- Add long-rage dependencies and adaptive spatial aggregation with 3x3 DCN
- SOTA accuracy in COCO dataset
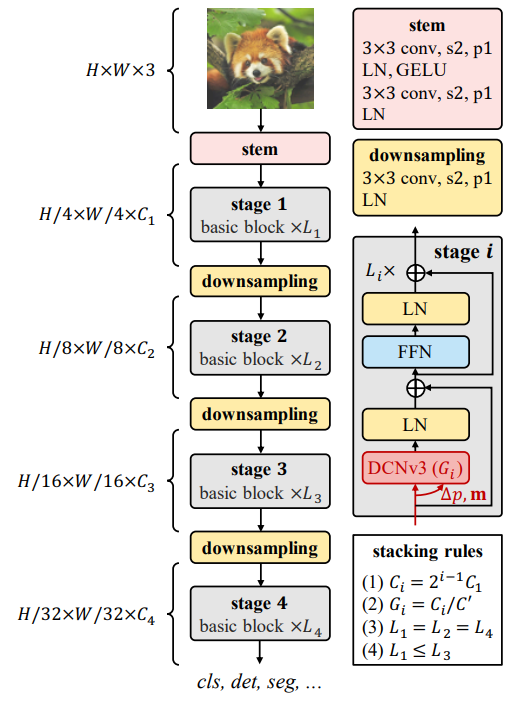
Deformable Convolution v3
Convolution vs MHSA
- 이전 연구에서 CNN과 ViT의 차이점에 대해 다양하게 논의
- InterImage의 Core Operator를 결정하기 전에 먼저 Regular Convolution과 MHSA의 차이에 대해 설명
- (1) Long-Range Dependencies
- Effective Receptive Field가 큰 Model은 대개 Downstream Vision Task에서 더 잘 수행된다는 것이 오랫동안 인식됨
- 3x3 Regular Convolution에 의해 Stacked CNN은 실질적인 Effective Field는 상대적으로 작음
- Very Deep Model에서도 CNN Based Model은 Long-Range Dependencies를 얻을 수 없음
- (2) Adaptive Spatial Aggregation
- Weight가 Input에 의해 Dynamic하게 조정되는 MHSA와는 다르게 Regular Convolution은 Static Weight를 가지고 2D Locality, Neightborhood Structure, Translation Equivalence 특성을 가진 Operation
- Bias가 높은 특성을 이용하여 Regular Convolution Model은 ViT에 비해 빨리 수렴되고 Training Data가 덜 필요할 수 있지만 CNN이 Web-Scale의 Large-Scale Data에 정보를 학습하는 것을 제한하기도 함
