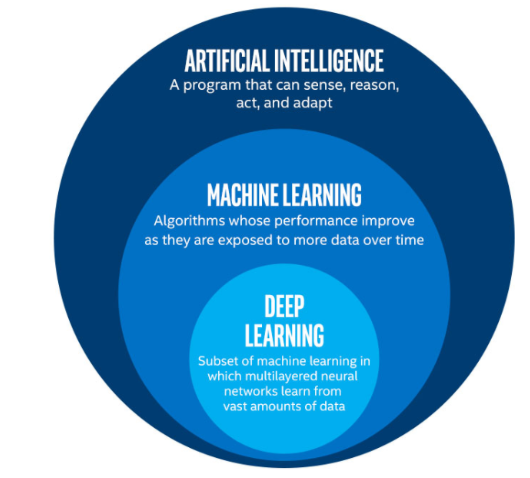
인공지능(AI : Artificial Intelligence)
인간의 지능이 가지고 있는 기능을 갖춘 컴퓨터 시스템을 뜻하며, 인간의 지능을 기계 등에 인공적으로 구현한 것을 말한다.
머신러닝/기계학습(ML : Machine Learning)
인공지능의 하위 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야를 뜻한다.
딥러닝(Deep Learning)
머신러닝의 하위 분야로 여서 비선형 변환기법의 조합을 통해 높은 수준의 추상화(다량의 복잡한 자료들에서 핵심적인 내용만 추려내는 작업)을 시도하는 기계학습 알고리즘의 집합을 뜻한다.
ANN(인공신경망 Artificial Neural Network)
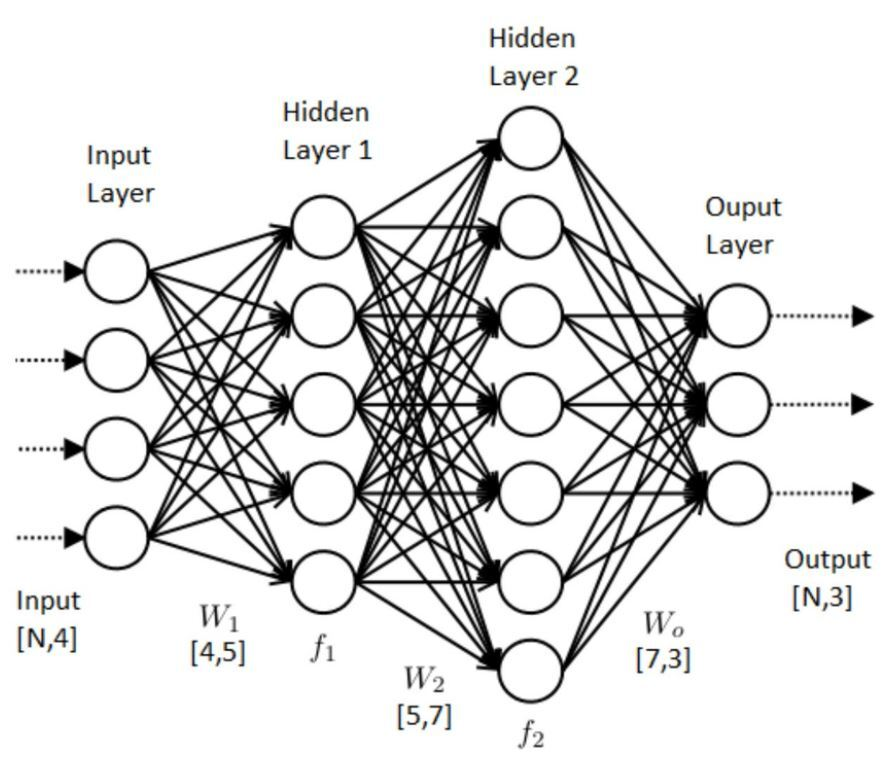
ANN 개념
위에서 설명한 머신러닝의 한 분야인 딥러닝은 인공신경망(Artificial Neural Network)를 기초로 하고 있다. 인공신경망이라고 불리는 ANN은 사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘이다.
인간의 뇌에서 뉴런들이 어떤 신호, 자극 등을 받고, 그 자극이 어떠한 임계값(threshold)을 넘어서면 결과 신호를 전달하는 과정에서 착안한 것으로 여기서 들어온 자극, 신호는 인공신경망에서 Input Data이며 임계값은 가중치(weight), 자극에 의해 어떤 행동을 하는 것은 Output데이터에 비교하면 된다.
ANN의 특징
- 사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘.
- 모든 비선형 함수를 학습
- 모든 입력을 출력에 매핑하는 가중치를 학습할 수 있는 능력.
- 구성
- 다수의 입력 데이터를 받는 입력층(Input)
- 데이터의 출력 담당하는 출력층(Output)
- 입력층과 출력층 사이에 존재하는 은닉층(Hidden Layer)
: 활성화 함수를 사용하여 최적의 가중치(Weight)와 Bias를 찾아내는 역할 - 모델을 구성 == hidden layer들의 갯수와 노드의 개수를 구성하는 것.
- 모델을 잘 구성하여 원하는 Output 값을 잘 예측해야 함.
ANN의 문제점
-
학습과정에서 파라미터의 최적값을 찾기 어려움
: 출력값을 결정하는 활성화함수의 사용은 기울기 값에 의해 weight가 결정되는데, 이런 gradient 값이 뒤로 갈수록 점점 작아져 0에 수렴하는 오류가 발생하기도 하고, 부분적인 에러를 최저 에러로 인식하여 더 이상 학습을 하지 않는 경우도 있음. -
느린 학습시간
→ 그래픽 카드의 발전으로 많은 연산량도 감당할 수 있을 정도로 하드웨어 성능 좋아짐.
: 은닉층이 많으면 학습하는데 정확도가 올라가지만 그만큼 연산량이 기하 급수적으로 늘어남. -
overfitting에 따른 문제
→ 사전훈련 통해 방지 가능
DNN(심층신경망 Deep Neural Network)
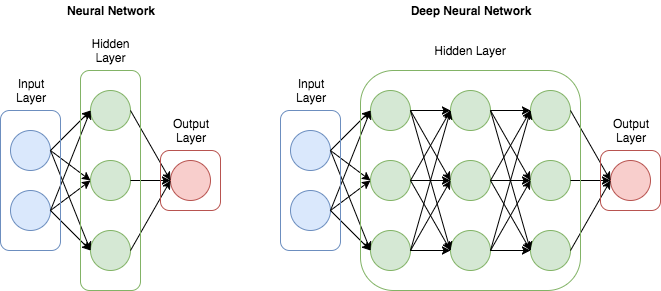
DNN의 개념 및 특징
-
ANN 문제 해결을 위해 은닉층 확대.
ANN기법의 여러문제가 해결되면서 모델 내 은닉층을 많이 늘려서 학습의 결과를 향상시키는 방법이 등장하였고 이를 DNN(Deep Neural Network)라고 한다. -
은닉층을 2개 이상 지닌 학습 방법. (보통 3개 이상)
DNN은 은닉층을 2개이상 지닌 학습 방법을 뜻한다. 컴퓨터가 스스로 분류레이블을 만들어 내고 공간을 왜곡하고 데이터를 구분짓는 과정을 반복하여 최적의 결과를 도출한다. 많은 데이터와 반복학습, 사전학습과 오류역전파 기법을 통해 현재 널리 사용되고 있다. -
DNN 응용하여 CNN, RNN, LSTM, GRU 발전.
그리고, DNN을 응용한 알고리즘이 바로 CNN, RNN이다.
이 외에도 LSTM, GRU 등이 있다.
CNN(합성곱신경망 Convolution Neural Network)

CNN의 개념 및 특징
- CNN은 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조
- 일반 DNN에서 이미지나 영상과 같은 데이터 처리할 때 발생하는 문제점 보완
- 정보추출, 문장분류, 얼굴인식 등의 분야에서 사용
- Convolution과정과 Pooling과정을 통해 진행됨.
- Convolution Layer와 Pooling Layer을 복합적으로 구성하여 알고리즘을 만듦
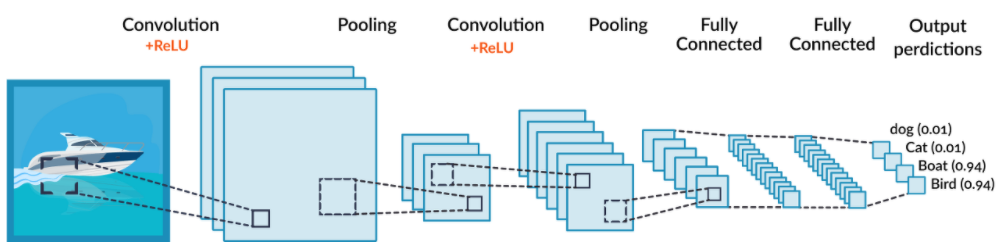
01. Convolution
- 데이터의 특징을 추출하는 과정.
- 데이터에 각 성분의 인접 성분들을 조사해 특징을 파악하고 파악한 특징을 한장으로 도출시키는 과정.
- 도출된 층을 Convolution Layer라고 함.
- 이 과정은 하나의 압축 과정이며 파라미터의 갯수를 효과적으로 줄여주는 역할을 함.
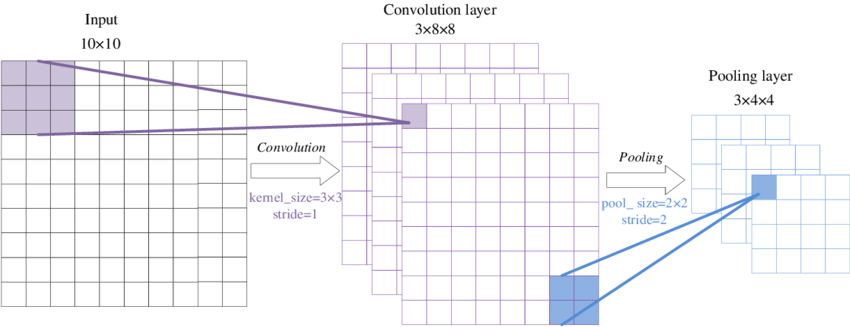
02. Pooling
- Convolution 과정을 거친 Layer의 사이즈를 줄여주는 과정.
- 단순히 데이터의 사이즈를 줄여주며, 노이즈를 상쇄시키고 미세한 부분에서 일관적인 특징을 제공.
Reference
https://dbrang.tistory.com/1537
https://ebbnflow.tistory.com/119
https://velog.io/@arittung/ANN-DNN-CNN-RNN
https://velog.io/@arittung/CNN-ResNet50
