데이터 사이언스 스쿨 에서 공부한 내용입니다.
3.5 PCA
N개의 M차원 데이터가 있으면 보통 그 데이터들은 서로 다른 값을 가진다. 하지만 이러한 데이터 간의 변이(variation)는 무작위가 아니라 특정한 규칙에 의해 만들어지는 경우가 있다. 예를 들어 붓꽃의 꽃받침 길이는 꽃마다 다르지만 꽃받침 길이가 약 2배 커지면 꽃받침 폭도 약 2배 커지는 것이 일반적이다. 이러한 데이터 간의 변이 규칙을 찾아낼 때 PCA를 이용할 수 있다.
PCA(Principal Component Analysis)는 주성분 분석이라고도 하며 고차원 데이터 집합이 주어졌을 때 원래의 고차원 데이터와 가장 비슷하면서 더 낮은 차원 데이터를 찾아내는 방법이다. 차원축소(dimension reduction) 라고도 한다. 더 낮은 차원의 데이터값 변화가 더 높은 차원의 데이터값 변화를 설명할 수 있다는 것은 얼핏 보기에 복잡해 보이는 고차원 데이터의 변이를 몇 가지 원인으로 설명할 수 있다는 뜻이다.
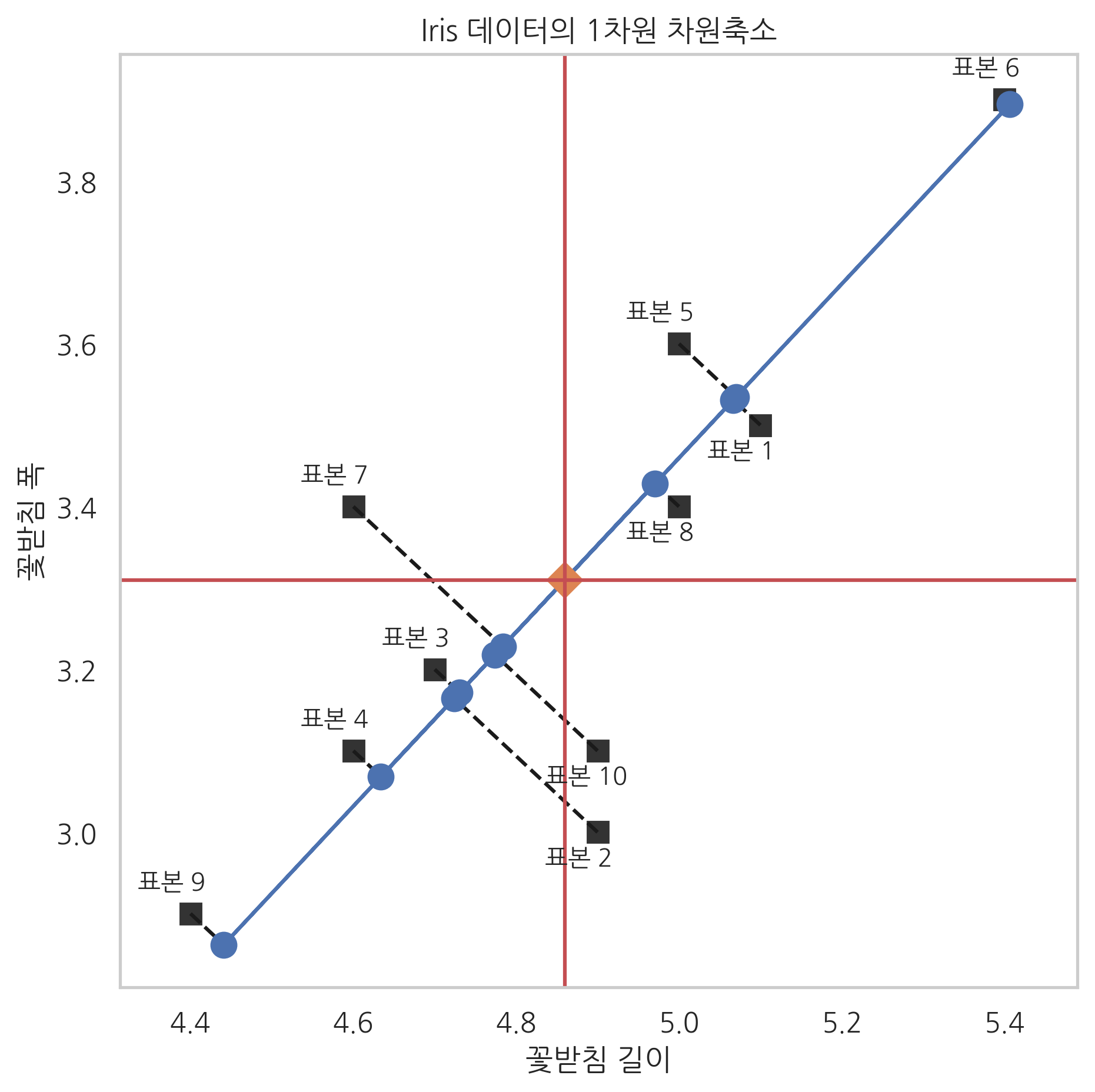
붓꽃 데이터의 차원축소
꽃받침 길이가 크면 꽃받침 폭도 커지며 그 비율은 거의 일정하다. 그 이유는 (꽃받침 길이, 꽃받침 폭)이라는 2차원 측정 데이터는 사실 "꽃의 크기"라는 근본적인 데이터가 두 개의 다른 형태로 표현된 것에 지나지 않기 때문이다. 바로 측정되지는 않지만 측정된 데이터의 기저에 숨어서 측정 데이터를 결정짓는 데이터를 잠재변수(latent variable) 라고 부른다.
PCA에서는 잠재변수와 측정 데이터가 선형적인 관계로 연결되어 있다고 가정한다. 즉, i번째 표본의 측정 데이터 벡터 xi의 각 원소를 선형조합하면 그 뒤에 숨은 i번째 표본의 잠재변수 ui의 값을 계산할 수 있다고 가정한다. 이를 수식으로 나타내면 다음과 같다.
ui=wTxi(3.5.1)
이 식에서 w는 측정 데이터 벡터의 각 원소를 조합할 가중치 벡터다.
붓꽃의 예에서는 꽃받침 길이와 꽃받침 폭을 선형조합하여 꽃의 크기를 나타내는 어떤 값을 찾은 것이라고 생각할 수 있다.
ui=w1xi,1+w2xi,2(3.5.2)
스포츠 선수의 경우에는 경기 중 발생한 다양한 기록을 선형조합하여 기량을 나타내는 점수를 계산하는 방법을 많이 사용한다. 일례로 미식축구의 쿼터백의 경우에는 패서 레이트(passer rate)라는 점수를 이용하여 선수를 평가는데 이 값은 패스 성공 횟수(completions), 총 패싱 야드(passing yards), 터치다운 횟수(touchdowns), 인터셉션 횟수(interceptions)를 각각 패스 시도 횟수(attempts)로 나눈 값을 선형조합하여 계산한다.
passer rating=5⋅attemptscompletions+0.25⋅attemptspassing yards+20⋅attemptstouchdowns−25⋅attemptsinterceptions+0.125(3.5.3)
선수의 실력이라고 하는 잠재변수의 값이 이 4개 수치의 선형조합으로 표현될 것이라고 가정한 것이다. 차원축소의 관점에서 보면 4차원의 데이터를 1차원으로 축소한 것이다.
차원축소와 투영
차원축소문제는 다차원 벡터를 더 낮은 차원의 벡터공간에 투영하는 문제로 생각하여 풀 수 있다. 즉, 특이분해에서 살펴본 로우-랭크 근사(low-rank approximation) 문제가 된다. 이 문제는 다음과 같이 서술할 수 있다.
N개의 M차원 데이터 벡터 x1,x2,⋯,xN를 정규직교인 기저벡터 w1,w2,⋯,wK로 이루어진 K차원 벡터공간으로 투영하여 가장 비슷한 N개의 K차원 벡터 x1∥w,x2∥w,⋯,xN∥w를 만들기 위한 정규직교 기저벡터 w1,w2,⋯,wK를 찾는다.
다만 원래의 로우-랭크 근사문제와 달리 근사 성능을 높이기 위해 직선이 원점을 지나야 한다는 제한조건을 없애야 한다. 따라서 문제는 다음과 같이 바뀐다.
N개의 M차원 데이터 벡터 x1,x2,⋯,xN에 대해 어떤 상수 벡터 x0를 뺀 데이터 벡터 x1−x0,x2−x0,⋯,xN−x0를 정규직교인 기저벡터 w1,w2,⋯,wK로 이루어진 K차원 벡터공간으로 투영하여 가장 비슷한 N개의 K차원 벡터 x1∥w,x2∥w,⋯,xN∥w를 만들기 위한 정규직교 기저벡터 w1,w2,⋯,wK와 상수 벡터 x0를 찾는다.
N개의 데이터를 1차원 직선에 투영하는 문제라고 하면 원점을 지나는 직선을 찾는게 아니라 원점이 아닌 어떤 점 x0을 지나는 직선을 찾는 문제로 바꾼 것이다.
이 문제의 답은 다음과 같다.
x0는 데이터 벡터 x1,x2,⋯,xN의 평균벡터이고 w1,w2,⋯,wK는 가장 큰 K개의 특잇값에 대응하는 오른쪽 특이벡터 v1,v2,⋯,vK이다.
PCA의 수학적 설명
M 차원의 데이터 x가 N개 있으면 이 데이터는 특징 행렬 X∈RN×M로 나타낼 수 있다.
이 데이터를 가능한 한 쓸모 있는 정보를 유지하면서 더 적은 차원인 K(K<M) 차원의 차원축소 벡터 x^으로 선형변환하고자 한다.
예를 들면 3차원 상의 데이터 집합을 2차원 평면에 투영하여 새로운 데이터 집합을 만들 때 어떤 평면을 선택해야 원래의 데이터와 투영된 데이터가 가장 차이가 적을까? 이 평면을 찾는 문제와 같다. 여기에서는 설명을 단순하게 하기 위해 데이터가 원점을 중심으로 퍼져 있다고 가정한다.
데이터가 원점을 중심으로 존재하는 경우에는 벡터에 변환행렬을 곱하는 연산으로 투영 벡터를 계산할 수 있다. 다음처럼 데이터 x에 변환행렬 W∈RK×M를 곱해서 새로운 데이터 x^i를 구하는 연산을 생각하자.
x^i=Wxi(3.5.4)
x∈RM,W∈RK×M,x^∈RK(3.5.5)
모든 데이터 xi(i=1,⋯,N)에 대해 변환을 하면 벡터가 아닌 행렬로 표현할 수 있다.
X^=XWT(3.5.6)
X∈RN×M,X^∈RN×K,WT∈RM×K(3.5.7)
이 식에서 행렬 X는 벡터 xi(i=1,⋯,N)를 행으로 가지는 행렬이고 행렬 X^는 벡터 x^i(i=1,⋯,N)를 행으로 가지는 행렬이다.
PCA의 목표는 변환 결과인 차원축소 벡터 x^i가 정보가 원래의 벡터 xi가 가졌던 정보와 가장 유사하게 되는 변환행렬 W값을 찾는 것이다.
그러나 x^i는 K 차원 벡터로 원래의 M 차원 벡터 xi와 차원이 다르기 때문에 직접 두 벡터의 유사도를 비교할 수 없다. 따라서 x^i를 도로 M 차원 벡터로 선형 변형하는 역변환행렬 U∈RM×K도 같이 찾아야 한다.
그러면 원래의 데이터 벡터 x를 더 낮은 차원의 데이터 x^=Wx으로 변환했다가 다시 원래의 차원으로 되돌릴 수 있다. 도로 M차원으로 변환된 벡터를 x^^라고 하자.
x^^=Ux^(3.5.8)
x^∈RK,U∈RM×K,x^^∈RM(3.5.9)
물론 이렇게 변환과 역변환을 통해 원래의 차원으로 되돌린 벡터 Ux^은 원래의 벡터 x와 비슷할 뿐 정확히 같지는 않다. 다만 이 값을 다시 한번 차원 축소 변환하면 도로 x^가 된다. 즉,
Wx^^=WUx^=x^(3.5.10)
따라서 W와 U는 다음 관계가 있다.
WU=I(3.5.11)
역변환행렬 U을 알고 있다고 가정하고 역변환을 했을 때 원래 벡터 x와 가장 비슷해지는 차원축소 벡터 x^를 다음과 같이 최적화를 이용하여 찾는다.
argx^min∣∣x−Ux^∣∣2(3.5.12)
목적함수는 다음과 같이 바꿀 수 있다.
∣∣x−Ux^∣∣2=(x−Ux^)T(x−Ux^)=xTx−x^TUTx−xTUx^+x^TUTUx^=xTx−2xTUx^+x^Tx^(3.5.13)
이 목적함수를 최소화하려면 x^로 미분한 식이 영벡터가 되는 값을 찾아야 한다. 이 부분은 행렬의 미분과 최적화 부분에서 배우게 된다. 여기에서는 일단 미리 풀이 과정을 제시한다.
위 목적함수를 미분한 식은 다음과 같다.
−2UTx+2x^=0(3.5.14)
이 식을 정리하면
x^=UTx(3.5.15)
가 된다. 원래의 변환식
x^=Wx(3.5.16)
과 비교하면
U=WT(3.5.17)
임을 알 수 있다. 따라서 다음 식이 성립한다.
WWT=I(3.5.18)
이제 남은 문제는 최적의 변환 행렬 W을 찾는 것이다. 이 경우의 최적화 문제는 다음과 같이 된다.
argWmini=1∑N∣∣xi−WTWxi∣∣2(3.5.19)
모든 데이터에 대해 적용하면 목적함수는 다음처럼 바뀐다.
argWmin∣∣X−XWTW∣∣2(3.5.20)
이 문제는 랭크-K 근사문제이므로 W는 가장 큰 𝐾 개의 특잇값에 대응하는 오른쪽 특이벡터로 만들어진 행렬이다.