
본 게시물은 프로젝트 및 대회 참여 8일차에 작성되었습니다.
동기들과 팀을 이뤄 캐글 대회에 참여하게 되었다. 본 과정에서 기대하던 '대회 경험'을 얻게 된 시기인 만큼 매일이 호기심, 열의로 가득하면서도 수 시간의 삽질, 과부하와 같은 이면도 공존하고 있다(..)
지금까지 EDA, Statistic, ML 이론과 실습의 단계를 밟아오며 주어진 데이터로 모델을 학습하고 결과를 낼 수 있는 '어정쩡하지만 실현 가능한' 수준까지 왔다.
이번 단계에선 Kaggle 대회에 팀 프로젝트 형태로 참가, Leaderboard에서 실시간으로 경쟁하는 경험을 겪게 된다. (두근두근)
대회 및 팀 선택
해당 팀 프로젝트 구간은 총 2주 동안 진행된다. 대회는 계속 진행되더라도, 일단 Upstage 과정에서는 종료된다.
수강생 전원에게 구글폼으로 선택지가 주어졌다. 현재 진행 중인 Active 대회 2개, Inactive 대회 2개 중에서 참여하고 싶은 대회를 골라 제출하면, 패스트캠퍼스 측에서 팀을 구성해주었다.
따라서 팀원은 누굴 만날지 알 수 없다. 이는 장점이자 단점이기도 한데, 다양한 사람들과 팀 프로젝트를 경험해볼 수 있지만 단점은... 말을 아끼겠다.
나는 실시간으로 LB에서 경쟁하고 싶었기에 Active 대회 중 하나로 선택했고, 같은 대회를 선택한 팀원 3명과 함께 해당 대회에 참가하게 되었다.
Multi-Class Prediction of Obesity Risk
참가 대회
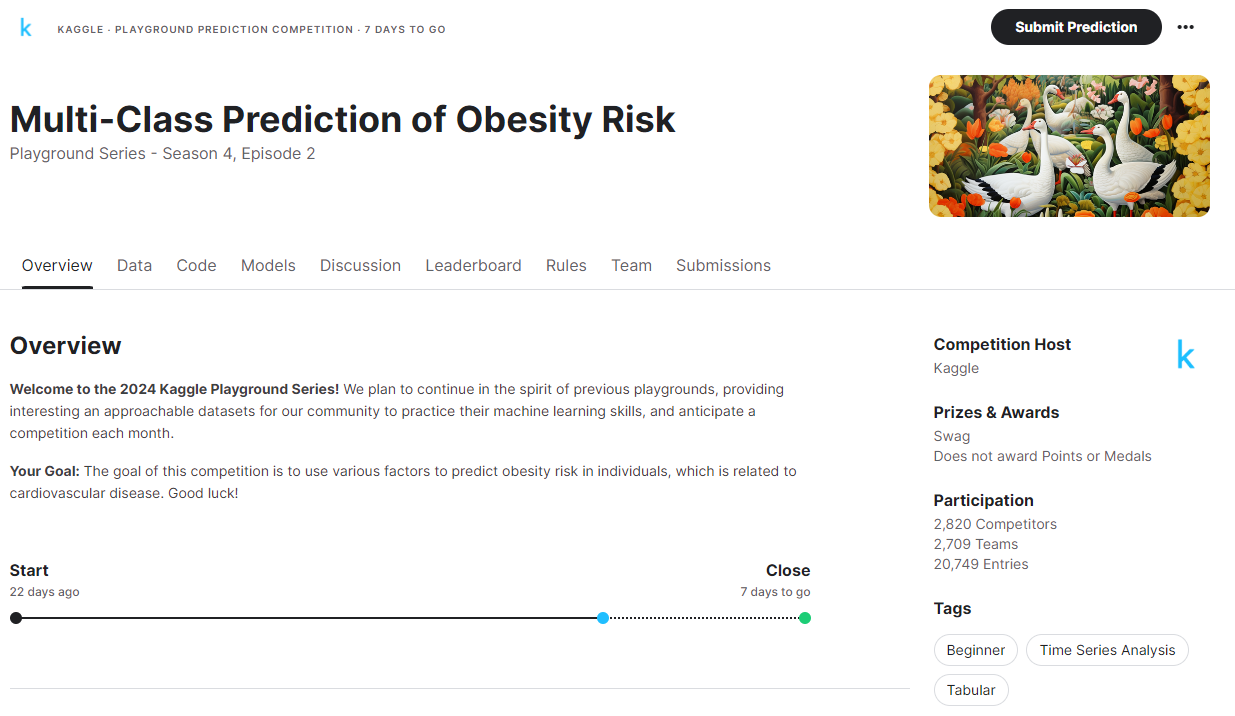
대회 이름처럼 내가 참가하게 된 캐글 대회는 Playground Series: 비만 위험도 예측. 쉽게 설명하면 나이, 몸무게, 하루 물 섭취량, 간식 섭취 빈도 등의 데이터로 저체중, 정상, 과체중, 비만 등의 7가지의 등급으로 분류하는 대회이다.
총 30일 동안 진행되는 대회이고, 내가 참여한 시기는 중간인 15일차 즈음이었다(사진은 방금 찍음)
Playground Series는 캐글 입문자들을 위해 만들어진 대회이다. 여러모로 나에게 적합한 대회!
모델 선택
train 데이터셋에 정답이 주어지고, 7가지의 등급으로 분류한다는 점에서 Classifier 종류의 모델이 적합하다고 판단했다.
그림 출처: 생활코딩
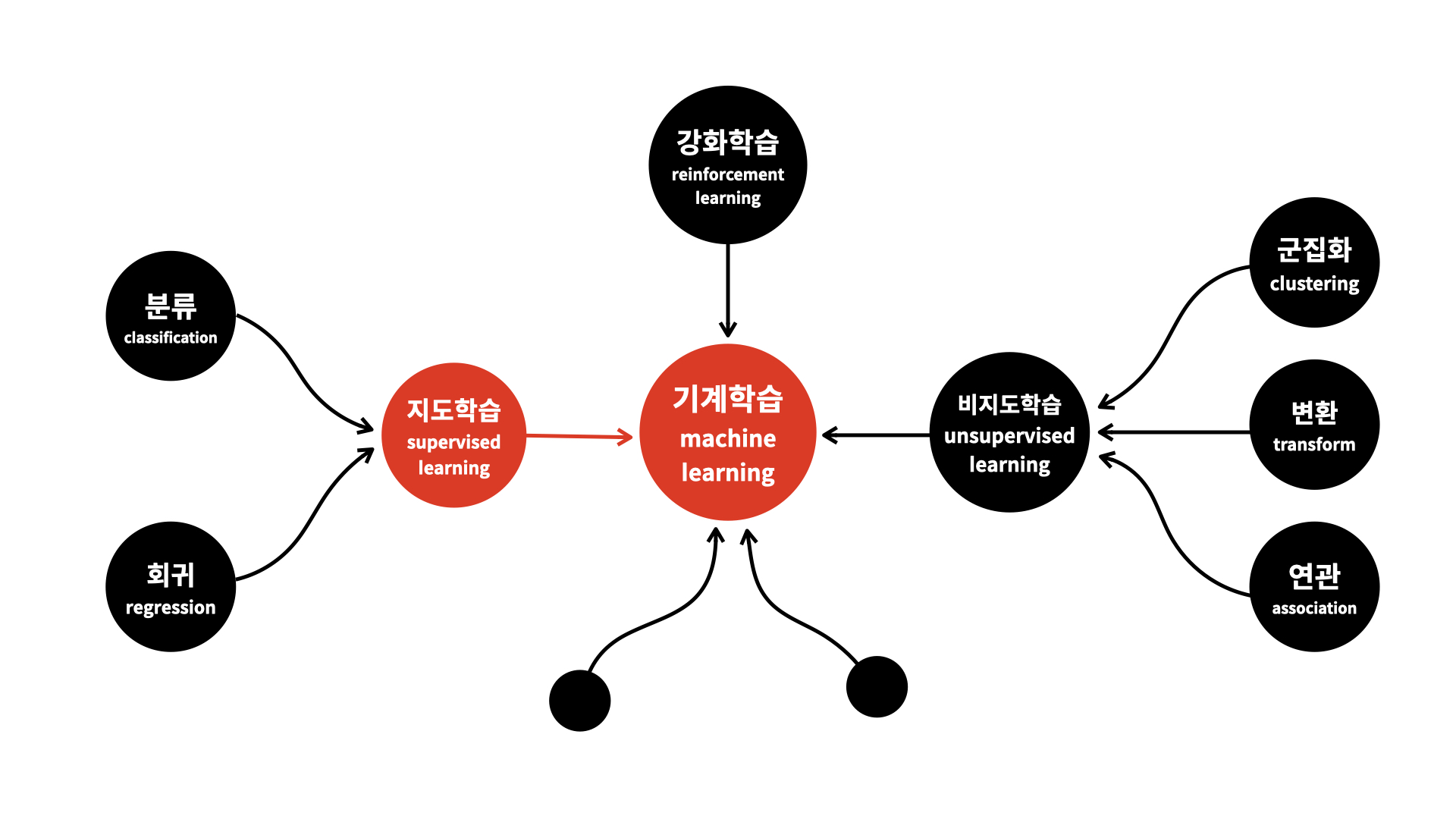
(정답이 주어지기에 지도학습, 분류 문제이기에 Classification)
해당 대회의 Discussion이나 code를 살펴보아도 LGBM Classifier, XGB CLassifier, 그리고 Cat Boost 세 모델이 대부분이었다.
1~4일차
(슬랙 팀 채널)
매일 회의를 통해
- 각자의 진행 상황
- 오늘 목표
위 사항을 공유했다. 현재 진행 중인 작업의 진행 상황을 공유하고, 오늘은 여기까지 해보자. 같은 방식으로 그날의 목표를 정했다.
위 사진이 예가 될 수 있는데, 오전회의에서 각자 사용해볼 모델을 골랐고, 해당 모델로 submit 해보는 것까지 목표로 잡았다. 완료되면 팀 채널에 해당 사항을 공유했다.
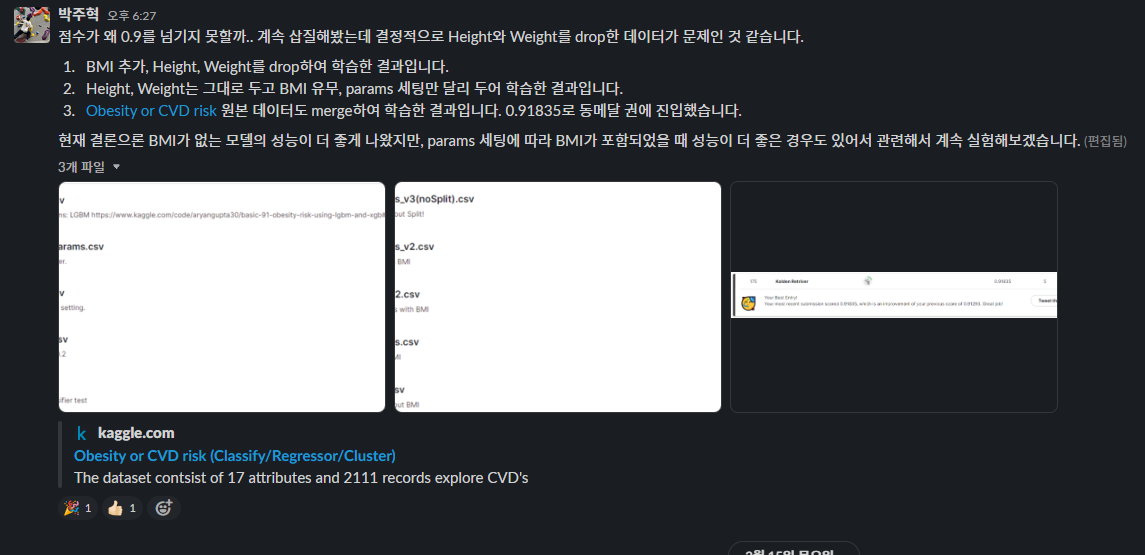
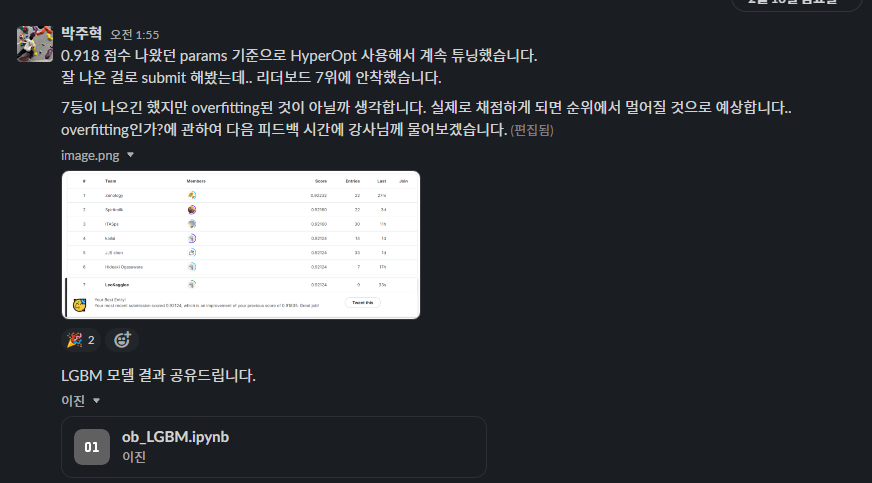
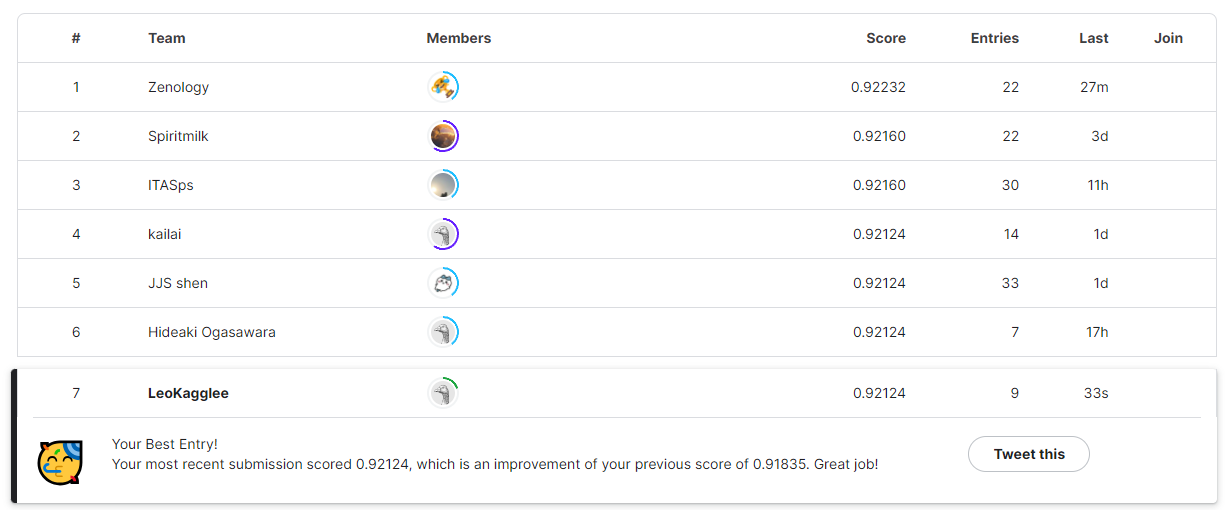
3일차에 약 2100개의 팀 중에서 개인으로 LB 7위를 기록했다!
5일차: 팀원 이탈과 팀 합병
첫 주가 지나고 나서 4명이서 시작했던 팀원 중 한 분이 취업 성공(!)으로 인해 팀 탈퇴 및 과정 하차를 선언하셨다.
축하하며 보내드렸지만, 팀의 중요한 전력(?)이셨기에 아쉬운 마음도 다소 있었다 ㅎㅎㅎㅎ
그러다가 같은 대회에 참가 중인 다른 조에서 의견 공유 제안이 오셔서 다른 조원분들 4명, 우리 팀 3명 총 7명이서 줌 미팅으로 각 팀의 진행상황을 공유했고, 이내 팀을 합치자는 제안도 주셔서 우리 팀 모두 흔쾌히 수락했다.
총 7명이 된 만큼 가설 증명 등의 실험도 더 다양하게 진행할 수 있었고, 여러 인사이트가 나오는 것 같아 긍정적인 면이 컸다.
6~8일차(현재)
합치게 된 새로운 팀원 분들께서 데이터셋의 이상치에 대한 인사이트를 공유주셨고, 이상치를 제거/변환하는 코드를 두 분이서 만들어서 공유 주셨다.
처음 프로젝트 및 대회를 시작할 때, 그리고 첫 주차에도 "도대체 어떻게 협업을 하는 거지?"와 같은 의문이 있었는데, 위 사례에서 '협업'이라는 걸 제대로 느끼게 되었다.
나는 첫 주차에 낸 성과 및 경험에 따라 하이퍼 파라미터 튜닝을 도맡아 진행했다.
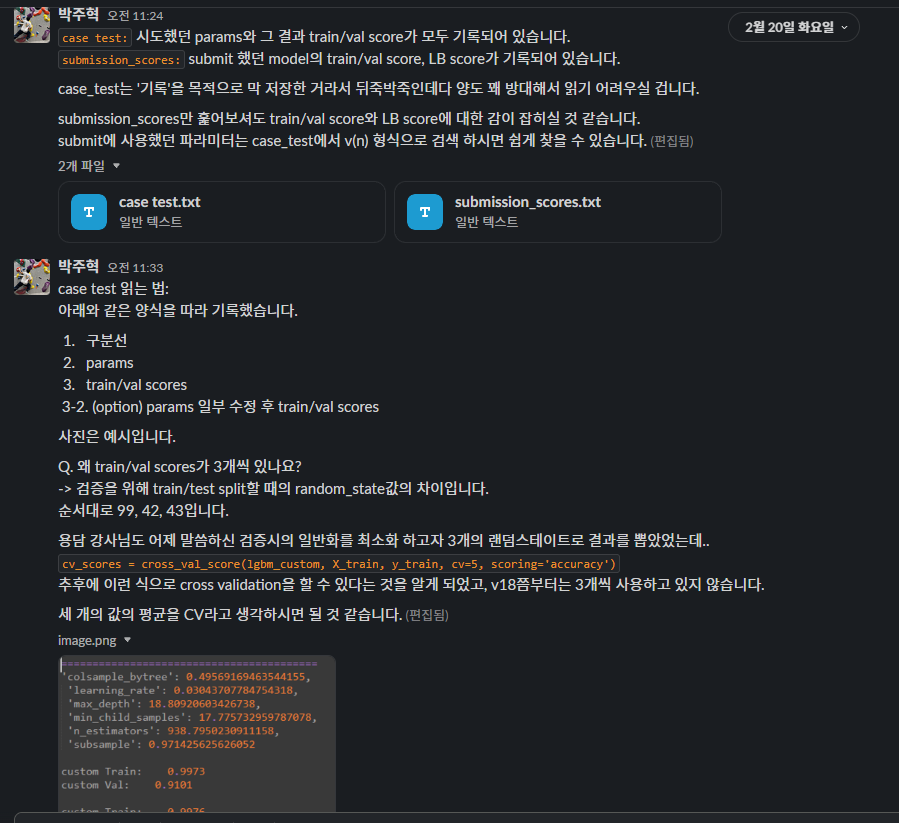
뒤죽박죽 기록된 파라미터들과 결과를 공유드렸는데, 뒤죽박죽인 이유는.. 혼자 보려고 양식없이 저장했던 탓..
때문에 공유하기에 적합하지 않음을 직감적으로 느꼈다.
기록이 중요하다는 것도 배우게 된 만큼, 다음 프로젝트에서는 "더 형식화해서 제대로 기록해야겠다" 라고 다짐하며..
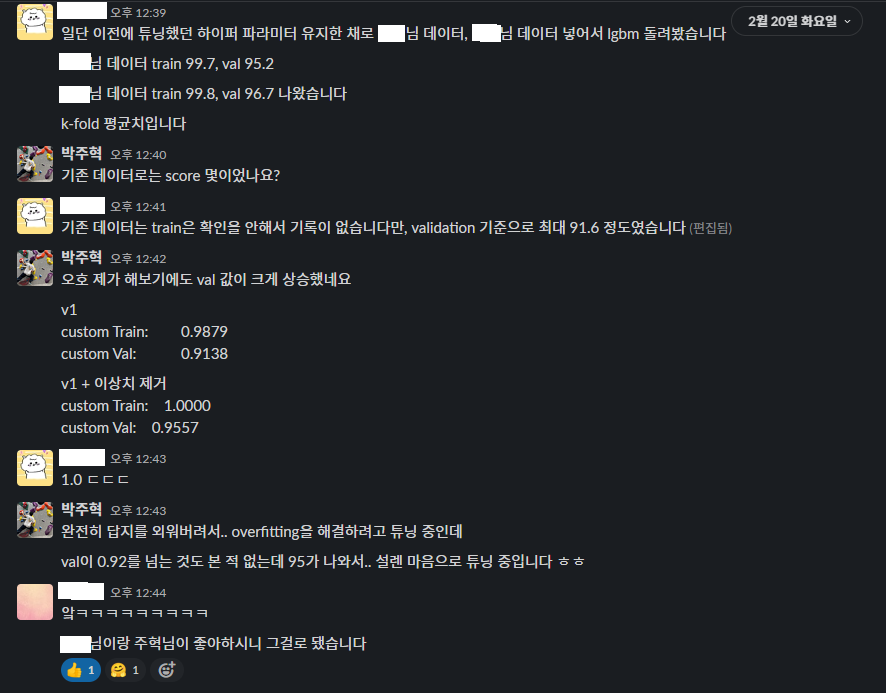
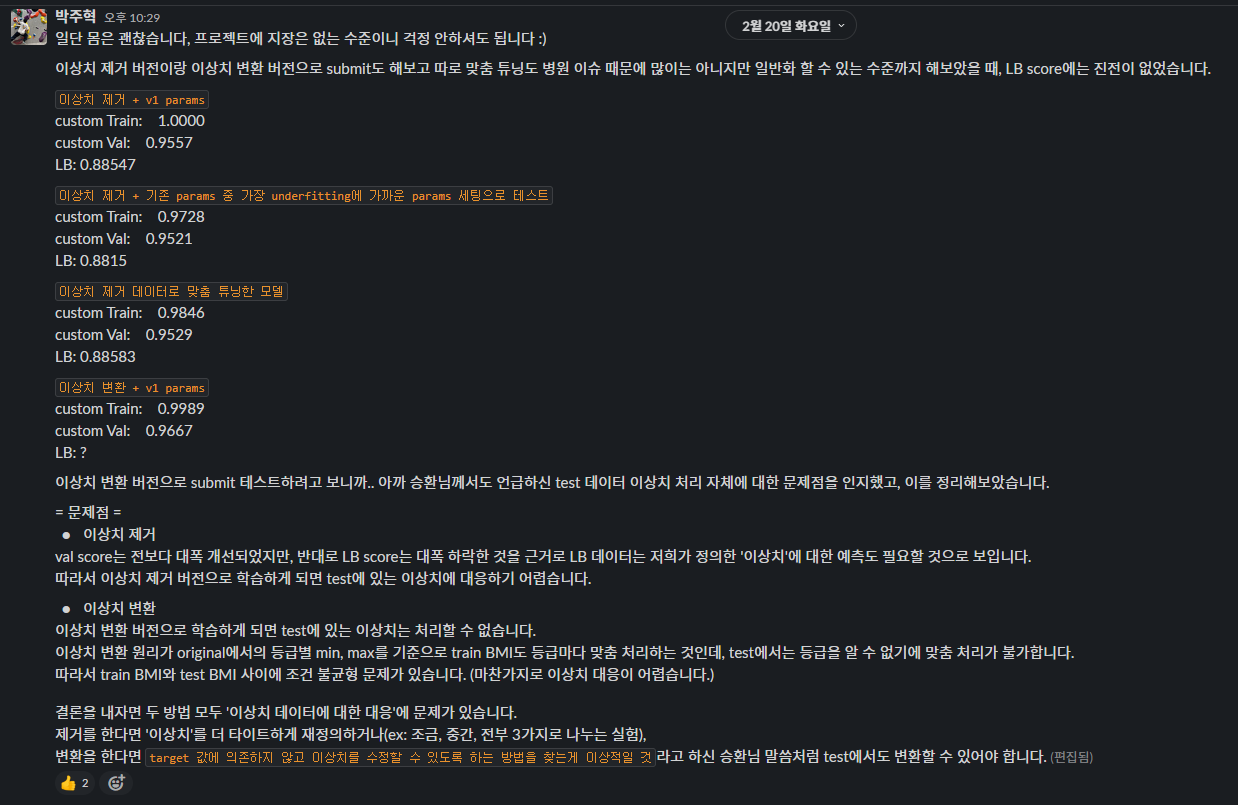
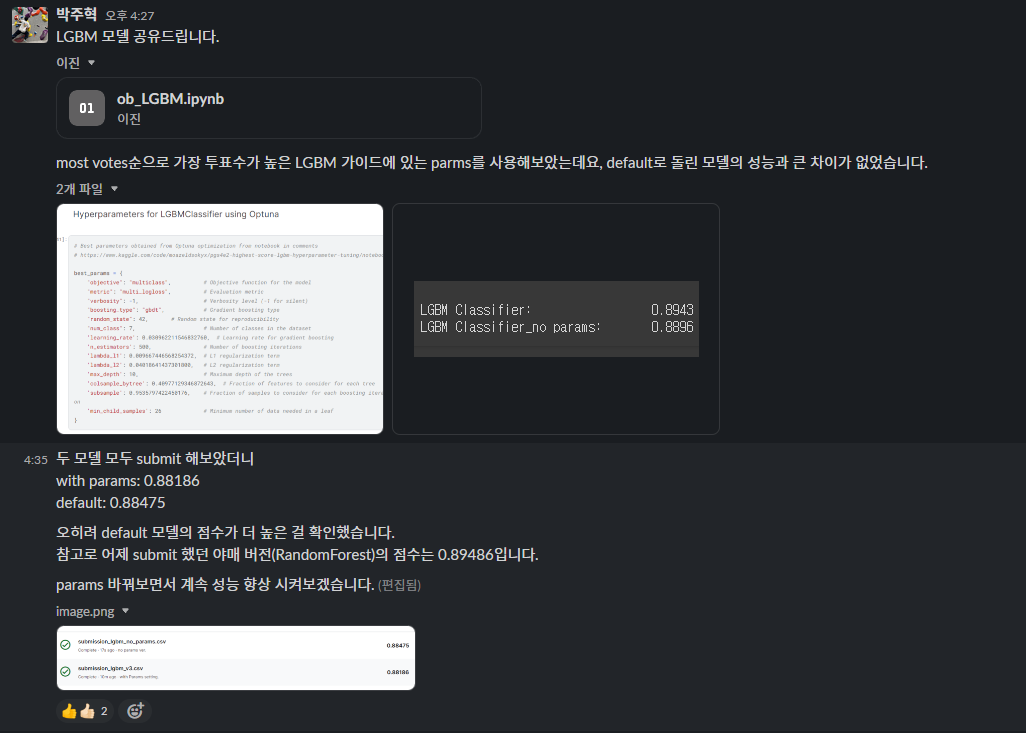
위에서 말한 이상치 제거/변환 데이터를 적용해서 submit까지 작업 중이었는데.. 문제점을 발견했고 정리해서 공유했다.
- 이상치를 제거/변환으로 모델의 성능을 개선하자!
-> 이제 더 예측을 잘하겠지?
-> (LB 점수가 낮아짐)
?
사진에 언급된 내용대로 이상치 제거/변환에는 큰 결함이 존재했는데, submit 해보기 전까지는 전혀 예상할 수 없었다. 결론적으로 실패한 개선 시도였다.
다만 이 실패로부터 이상치를 제거하는 등의 feature processing이 효과적일 순 없고 오히려 아무 의미 없을 수도 있다는 사실 등 경험을 통해 배운 점이 있었다.
마무리
금일까지 열심히 달렸다. 평균 하루 12시간씩 하이퍼 파라미터 튜닝에만 몰두하다보니 잠깐 외출을 나갈 때에도 머릿속에 train 0.988.. val 0.9138.. accuracy score 숫자가 둥둥 떠다닌다..
매일을 몰두하다보니 각 params에 대한 감각이 절로 생겼다. learning rate나 n estimator를 높이면 overfitting을 의도할 수 있고, lambda를 수정함으로써 같은 val score에서 overfitting을 완화할 수 있다는 점 등등.. 본 과정에 지원할 때 기대했던 '프로젝트 경험을 통한 기술 체화'를 제대로 체감하고 있음을 느낀다.
아직 대회 및 프로젝트는 끝나지 않았다. 내일은 프로젝트 발표 전 마지막 날이기에 지금까지 해온 작업들을 정리하는 날이 될 것 같다.
앞으로 정진!
