옵티마이저의 3개 서브머신, Query Transformer, Plan Generator, Estimator 중 Query Transformer는
더 나은 실행계획을 위해 사용자가 작성한 쿼리를 같은 결과를 보장하는 한에서 수정하기도 한다.
서브쿼리
서브 쿼리는 쿼리 안의 쿼리로서, 문장에서 괄호로 묶인 쿼리 블록을 말한다.
서브 쿼리가
From 절에 있으면 Inline View,
Where 절에 있으면 Nested Subquery,
하나의 row가 아니라 하나의 row, 하나의 column으로 반환되면 Scalar Subquery라고 한다
일반적으로는 메인 쿼리가 where절의 서브쿼리의 칼럼을 참조하지만,
반대로 where 절에 있는 Nested Subquery가 그 밖의 메인 쿼리의 칼럼을 참조하면
상관관계 있는 서브쿼리(correlated subquery)라고도 한다.
메인 쿼리에 있는 칼럼 A와, 그 칼럼 A를 가지고 서브쿼리에서 따로 생산한 값 A'와 비교해서
메인 쿼리로 반환하는 경우 사용된다.
from 절의 Inline View를 풀어내는 것을 뷰 merging,
where 절의 nested subquery 를 풀어내는 것을 서브쿼리 unnesting 이라고 한다.
서브쿼리 unnesting
서브쿼리들을 풀어내면 다양한 액세스 경로와 조인 메소드를 평가할 수 있다.
특히 옵티마이저는 조인 테크닉이 많기 때문에
조인 형태로 변환하면 더 나은 실행계획을 찾을 가능성이 높아진다.
따라서 옵티마이저는 웬만하면 서브쿼리를 풀어내려고 하지만
예상 비용에 따라 할 수도 있고 안 할 수도 있다.
unnesting을 강제하려면 select 뒤에 /*+ unnest */,
안 하려면 /*+ no_unnest */ 를 한다.
예시
직원 테이블 emp와 부서 테이블 dept가 있다.
직원 테이블은 직원의 부서 코드를 나타내는 deptno 칼럼을 가지고 있다.
deptno 칼럼은 부서 테이블의 PK로, 이를 FK로 참조하고 있는 상태이다.
select * from emp
where deptno in (select deptno from dept)이때 위와 같은 쿼리를 unnesting 하지 않고 실행한다면
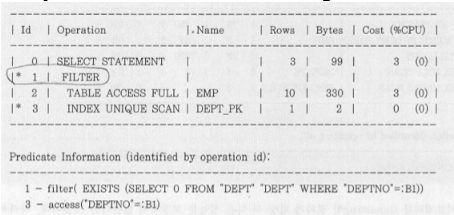
(실행계획은 밑에서 위로 본다)
위 실행계획과 같이 emp를 table full scan 하면서
각 row의 deptno를 인덱스로 하여 dept 테이블에 index unique scan해 filtering 하는 작업을 반복할 것이다.
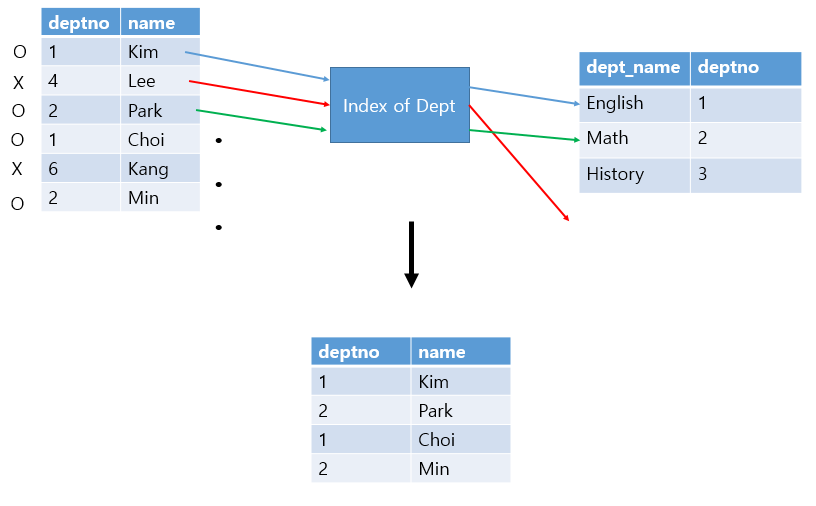
실행계획을 그림으로 나타낸 것이다.
이 실행계획은 DEPT로의 Index Unique Scan 을 EMP 의 전체 row만큼 반복한다.
unnesting을 진행한다면
select *
from (select deptno from dept) a, emp b
where b.deptno = a.deptno같은 쿼리가 된다.
여기서 from 절을 또 풀어내는 뷰 Merging을 진행하면
아래와 같은 일반 조인문으로 바뀐다.
select b.* from dept a, emp b where b.deptno = a.deptno
이를 실행하면
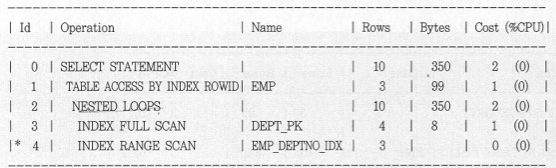
위와 같은 실행계획이 나오는데 이는 DEPT를 Index full scan 하면서
emp에서 deptno를 index range scan해서 찾은 결과들을 반환하는 방식이다.
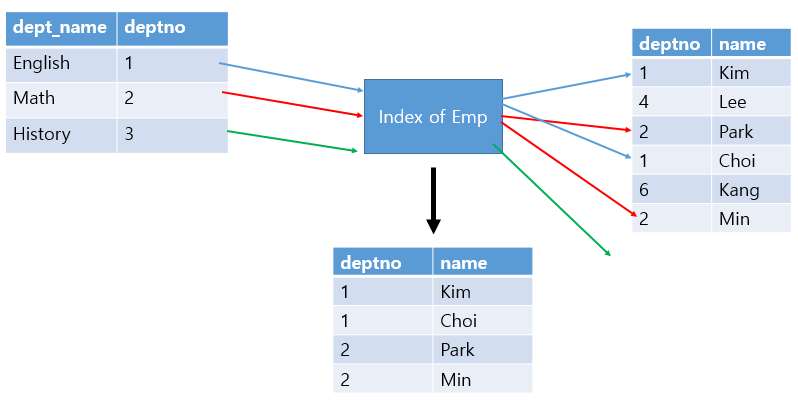
emp와 dept 테이블을 조인하면서 dept 테이블의 로우를 먼저 보고
거기서부터 시작해서(driving) emp의 테이블(driven)을 보았다.
즉, dept 테이블이 먼저 드라이빙 되었다고 할 수 있다.
(drive는 운전하다 말고도 이끌어낸다는 뜻도 있다.
이 경우 dept 테이블의 pk로 emp 테이블의 로우들을 검색하고 있기 때문에,
dept 테이블이 emp의 로우들을 이끌어내고 있다고 (driving) 볼 수 있으며
emp 테이블은 dept 테이블에게 driven 되고 있다고 할 수 있다.)
만약 emp 테이블이 먼저 드라이빙 되었다면, emp부터 봤다면,
서브쿼리 unnesting 을 안 한 것과 비슷하게 흘러갔을 것이다.
select * from emp
where deptno in (select deptno from dept)서브쿼리 unnesting을 안 했기 때문에
emp의 전체 로우를 일일히 보면서 deptno를 (select deptno from dept)에서 찾을 수 밖에 없다.
여기서 중요한 것은 일반적으로 직원보다 부서 테이블이 훨씬 작으며,
부서 안에 여러 명의 직원이 있다는 것이다.
또한 한 직원은 한 부서에만 속하는 일반적인 경우를 가정하면
직원 테이블과 부서 테이블의 관계는 M:1이 된다.
즉, 부서 테이블을 드라이빙하는 것이 직원 테이블을 드라이빙 하는 것보다 좋다.
이처럼 조인 시에 드라이빙을 하는 순서에 따라서 성능 차이가 발생하기도 한다.
M:1이라면 당연히 1쪽 테이블을 드라이빙하는 것이 좋다.
이를 조절하려면 leading(먼저 드라이빙 할 테이블 혹은 쿼리블록 이름)로 먼저 드라이빙할 것을 따로 지정하거나
ordered로 쿼리에 나타난 순서대로 드라이빙하도록 옵티마이저에게 힌트를 줄 수 있다.
이 경우에는 Dept와 Emp의 deptno가 PK-FK 로 연결되어 있기 때문에
옵티마이저가 자연스레 dept가 1쪽 테이블이라는 것을 알 수 있었다.
만일 그렇지 않다면 옵티마이저는 쿼리를 조인문으로 변환하지 않는다.
서브쿼리가 M쪽 집합이거나 Nonunique 인덱스일 때
위 쿼리는 조인으로 변경하여 emp를 먼저 보든 dept를 먼저 보든 결과는 의도한 것과 같았다.
(의도는 소속 부서가 지정되어 있는 직원들을 찾는 것이다)
select * from dept
where deptno in (select deptno from emp)예시에서 emp와 dept 위치만 바꿔서,
위와 같이 직원이 한 명이라도 있는 부서를 찾는다고 가정했을 때
일단 조인문으로는 변경할 수 없다.
왜냐하면 그냥 조인해버리고 dept를 드라이빙해서 emp에서 찾으면
결과가 dept 단위(select * from dept...)가 아닌
emp 단위(select * from emp...)의 테이블이 되어서
부서 정보가 중복해서 뜰 것이기 때문이다.
(정확히는 각 부서 정보가 그 부서 직원 수만큼 반복될 것이다.)
이것은 의도와 다르다.
위 예시에서 dept를 먼저 본 것은 의도한 결과가 emp 단위이기 때문에 가능했다.
다시 예시로 돌아와서,
select * from emp
where deptno in (select deptno from dept)위와 같은 쿼리를 PK/FK 제약이 없고, deptno에 unique한 인덱스가 없는 상황에서 사용한다면 어떻게 될까?
정답은 이 역시 단순한 조인이 불가능하다.
emp를 먼저 보고 dept를 찾은 것은, emp의 deptno로 dept를 unique하게 찾을 수 있었기 때문에 가능했다.
오라클은 테이블의 deptno가 unique 하게 만들기 위해 sort unique 와 semi join 방식을 수행한다.
뷰 Merging
from 뒤에 서브쿼리가 오면 인라인 뷰라고 하며
이를 메인쿼리의 테이블과 조인해서 서브쿼리를 풀어내는 것을 뷰 merging이라고 한다.
특히 그 서브쿼리에 조건문과 조인만 있으면 단순 View,
group by나 select에 distinct가 있으면 복합 View라고 한다.
뷰를 merge해서 메인쿼리와 조인 시키면 더 좋은 실행계획을 짤 수 있기 때문에, 현재 둘 다 default로 풀어낸다.
다음 조건에선 뷰 merging이 불가능하다.
- 집합 연산자 사용
- connected by 절
- ROWNUM pseudo 칼럼
- select에 전체 집계 함수 사용 (group by 를 사용하지 않은)
- 분석 함수
이때는 뷰 merging이 아니라 조건절 push로 최적화를 한다.
no_merge 힌트로 뷰 merging을 방지할 수 있다.
예를 들어
select d.dname, avg_sal_dept
from dept d
, (select deptno, avg(sal) avg_sal_dept
from emp
group by deptno) e
where d.deptno = e.deptno
and d.loc = 'CHICAGO'의 뷰를 Merge하면
select d.dname, avg(sal)
from dept d, emp e
where d.deptno = e.deptno
and d.loc = 'CHICAGO'
group by d.rowid, d.dname가 되는데, 기존 쿼리는 직원 테이블에서 부서별 평균 월급을 모두 구한 다음 조인한 후 CHICAGO로 필터링하지만
merge된 쿼리는 애초에 시카고 위치한 직원들만의 부서별 평균 월급을 구한다.
그리고 이는 조건절 pushing으로도 비슷하게 구현할 수 있다.
조건절 pushing
조건절 pushdown
옵티마이저가 뷰를 처리함에 있어, 1차적으로 뷰 merging을 고려하지만 조건절 pushing을 고려할 수 있다.
조건절 pushing은 서브쿼리 밖에 있는 조건절을 서브쿼리 안으로 밀어넣는 것을 의미한다.
서브쿼리의 결과가 전부 메인쿼리에서 필요한 것이 아닐 수 있기 때문이다.
위에서도 보면, 부서별 평균 월급을 구할 때 시카고가 아닌 일리노이나 뉴욕에 위치한 직원들은 굳이 group by 연산의 대상이 될 필요가 없기 때문에, 이들을 제외하고 group by 한 다음 avg를 구하는 것이 훨씬 빠를 것이다.
즉 위의 1번 쿼리보단
select d.dname, avg_sal_dept
from dept d
, (select deptno, avg(sal) avg_sal_dept
from emp
where d.deptno = e.deptno
group by deptno) e
and d.loc = 'CHICAGO'가 더 빠를 것이다.
이때 오라클이 서브쿼리 밖에 있던 where d.deptno = e.deptno 조건절을 안으로 밀었다.
조건절 pushdown이 일어난 것이다.
push_pred 힌트를 통해 조건절 pushdown을 유도할 수 있고
반대로 no_push_pred 로 방지할 수 있다.
참고로 이 힌트는 use_nl 이랑 같이 이용할 수가 없는데
use_nl 은 nested loop을 사용한다는 것 = 뷰 merging 을 한다는 것이기 때문이다.
그래서 use_nl을 쓰면 조건절 pushdown이 무시된다.
조건절 pullup
반대의 경우도 존재한다. 이는 서브쿼리에 있는 조건절이 밖으로 나가는 것을 의미한다.
이때 나온 조건절은 다른 서브쿼리로 pushdown 된다.
select * from (select deptno, avg(sal) from emp where deptno = 10 group by deptno) e1 ,
(select deptno, min(sal), max(sal) from empgroup by deptno) e2
where e1.deptno = e2.deptno첫번째 서브쿼리에 있는 where deptno = 10이 다시 밖으로 나가서 두번째 서브쿼리로 들어갈 것이다.
(복사 + 붙여넣기가 될 것이다.)
왜냐하면 둘은 deptno 기준으로 조인이 될 것인데, inner 조인이다 보니 첫번째 서브쿼리에서 deptno에 대한 조건이 걸리면 두번째 서브쿼리의 결과에서 deptno가 10이 아닌 것들은 조인에 사용되지 않을 것이기 때문이다.
따라서 두번째 서브쿼리에서 deptno=10 조건을 달아주면 불필요한 집계함수 사용을 피할 수 있다.
조인 조건 pushdown
select d.deptno, d.dname, e.avg_sal
from dept d ,(select deptno, avg(sal) avg_sal from emp group by deptno) e
where e.deptno(+) =d.deptnodept와 서브쿼리 e가 left join을 하고 있다.
직원의 부서별 평균 월급을 구해서 그 부서에 대한 정보를 얻으려는 쿼리이다.
직원 테이블에 있는 부서 중 부서 테이블에 없는 부서는 결과에서 제외되기 때문에 굳이 평균을 낼 이유가 없다.
그래서 emp의 deptno 중 dept 테이블에 있는 직원들에 대해서만 평균을 내야 한다.
조건절 이행
이행(transition)은 A=B이고 B=C면 A=C임을 유추해낼 수 있는 기능이다.
select *
from dept d, emp e
where e.job = 'MANAGER' and e.deptno = 10 and d.deptno = e.deptnoe.deptno=10이고 d.deptno=e.deptno 면 d.deptno=10이다.
즉 조건절이 e.deptno=10 and d.deptno=10이 가능하다.
위와 같이 변환한다면, Hash Join 또는 Sort Merge Join을 수행하기 전에 emp와 dept 테이블에 각각 필터링을 적용함으로써 조인되는 데이터량을 줄일 수 있다.
그리고 dept 테이블 액세스를 위한 인덱스 사용을 추가로 고려할 수 있게 돼 더 나은 실행계획을 수립할 가능성이 커진다.
조인 제거
A, B 두 테이블을 조인하는데 막상 B 쪽 테이블의 자료를 이용하지 않는다면 조인을 제거하는 기능이다.
select a.name, a.id, a.location
from a, b
where a.name = b.nameselect 에서 b의 자료를 참조하고 있지 않으므로 이 조인은 필요가 없다.
OR 조건을 union으로 변환
OR 조건이 있으면 full table scan해서 or 을 실제로 수행하거나
앞조건을 인덱스로 탐색한 결과와 뒤조건 인덱스로 탐색한 결과를 비트맵 연산으로 필터링할 수 있다.
후자대로 하려면 OR를 union all 로 바꿔줘야 하는데, 이를 오라클이 해준다.
후자가 더 빠르려면 둘의 교집합이 적어야 한다.
크면 그만큼 탐색을 두 번 하는 것이고, 중복도 제거해줘야 하기 때문이다.
use_concat 힌트를 쓰면 union all 로 바뀌고,
no_expand 를 쓰면 일반 OR로 동작한다.
참고로 a = b or a = c랑 a in (b, c)는 같은 문장이다.
그래서 In-List에서도 이 OR-Expansion 기능이 동작한다.
기타 쿼리 변환
집합 연산을 조인으로 변환
앞서 말했듯 집합연산을 사용하면 뷰 merging이 일어나지 않아서, 실행계획을 완전히 탐색하지 못한다.
select job, mgr
from emp
minus
select job, mgr
from emp
where deptno = 10 ;이 쿼리를 emp와 emp 를 hash anti join 하는 방향으로 바꿀 수 있다.
조인 칼럼에 IS NOT NULL 추가
inner 조인이거나 outer 조인 시 driven 되는 쪽이라면 null인 로우가 무시되기 때문에 굳이 조인 대상에 포함할 필요가 없다.
그래서 해당 칼럼에 null인 값이 5% 이상이면 조인할 때 is not null을 추가해준다.
필터 조건 추가, 조건절 비교 순서 변경
사용자가 조건절에 between 10 and 5 라고 적으면 먼저 필터를 보고 말이 안 되는 조건이라는 걸 예상한 다음 block I/O를 실행하지 않는다.
그리고 조건이 A and B가 있을 때 A의 선택도가 B 선택도보다 크다면 B를 먼저 실행한다.
A인 로우가 100개 있고 B인 로우가 10개 있으면, A먼저 비교하면 100개 중에서 B인 로우를 찾게 되고 B먼저 비교하면 10개 중에서 A인 로우를 찾게 될 것이다.
당연히 후자가 더 빠르므로 조건 A보단 B를 먼저 평가한다.
