1. 다음 중 데이터베이스 연결(Connection)과 관련한 설명으로 가장 부적절한 것은?
-
데이터베이스 서버와 클라이언트 간 연결상태를 유지하면 서버 자원을 낭비하게 되므로 동시 사용자가 많은 OLTP 환경에선 SQL 수행을 마치자마자 곧바로 연결을 닫아주는 것이 바람직하다.
-
연결 요청에 대한 부하는 쓰레드 기반 아키텍처보다 프로세스 기반 아키텍처에서 더 심하게 발생한다.
-
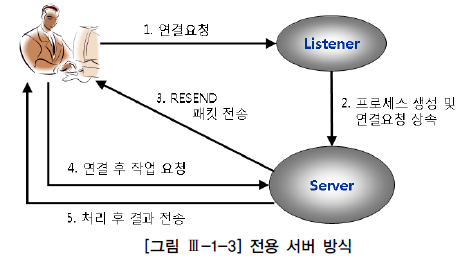
전용 서버 (Dedicated Server) 방식으로 오라클 데이터베이스에 접속하면 사용자가 데이터베이스 서버에 연결 요청을 할 때마다 서버 프로세스가 생성된다.
-
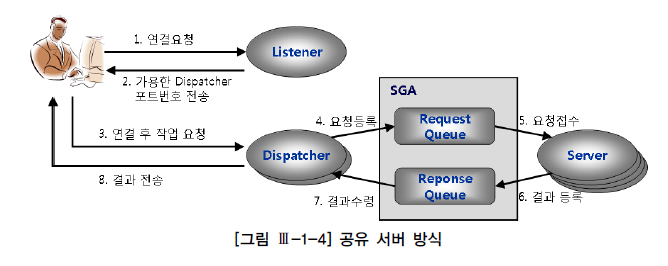
공유 서버 (Shared Server) 방식으로 오라클 데이터베이스에 접속하면 사용자 프로세스는 서버 프로세스와 직접 통신하지 않고 Dispatcher 프로세스를 거친다.
정답: 4
참고-
SQL 수행을 마치자마자 곧바로 연결을 닫는다는 건 쿼리를 날릴 때마다 연결을 했다가 끊었다가 한다는 뜻이다. 연결을 한다는 것은 서버 프로세스를 새로 실행한다는 뜻이므로, 연결을 하는 자체에 큰 오버헤드가 발생한다. 따라서 SQL을 마치자마자 연결을 끊는 것보단, 또 쿼리가 들어올 수도 있으니 연결을 열어두는 것이 좋다.
-
일반적으로 context switch는 스레드보다 프로세스에서 오버헤드가 크다.
-
-
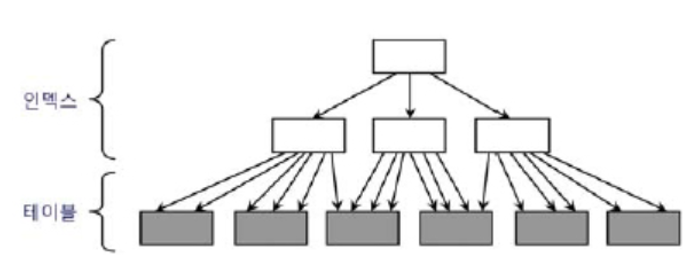
2. 다음 중 Oracle이나 SQL Server 같은 데이터베이스의 저장 구조를 설명한 것으로 가장 부적절한 것은?
- 데이터를 읽고 쓰는 단위는 블록(=페이지)이다.
- 데이터파일에 공간을 할당하는 단위는 익스텐트다.
- 같은 세그먼트(테이블, 인덱스)에 속한 익스텐트끼리는 데이터파일 내에서 서로 인접해 있다.
- SQL Server에서는 한 익스텐트에 속한 페이지들을 여러 오브젝트가 나누어 사용할 수 있다.
정답: 3
-
DBMS 는 데이터를 블록 단위로 읽고 쓴다. SQL 성능을 좌우하는 것은 DBMS가 처리하는 블록의 수이다.
-
DBMS 는 익스텐트 단위로 테이블에 공간을 할당한다.
-
익스텐트 내 블록들은 연속하지만, 세그먼트 내 익스텐트는 연속하지 않는다.
세그먼트를 구성하는 익스텐트들은 여러 데이터 파일에 흩어져 있을 수 있다. -
오브젝트는 테이블이나 뷰, 인덱스 등 실체가 있으며 독립적으로 존재했을 때 의미가 있는 저장공간이다. Oracle은 한 익스텐트에 속한 모든 블록을 단일 오브젝트가 사용하지만, SQL Server에서는 2개 이상 오브젝트가 나누어 사용할 수도 있다.
3. 데이터 변경 사항을 일단 데이터 버퍼 캐시에만 기록했다가 시간 간격을 두고 데이터 파일에 일괄 반영하려면 반드시 Redo(또는 Transaction) 로그의 도움이 필요하다. 그래야 DBMS에 문제가 발생하더라도 안전하게 복구할 수 있다. 이런 Redo 로그(또는 트랜잭션 로그) 메커니즘의 특징을 설명하는 여러 가지 용어가 있는데, 다음 중 아래와 관련된 것으로 가장 적절한 것은?
정답/해설“버퍼 캐시 블록을 갱신하기 전에 변경사항을 먼저 로그 버퍼에 기록 해야 하며, Dirty 버퍼를 디스크에 기록하기 전에 해당 로그 엔트리를 먼저 로그 파일에 기록해야 한다.”
정답: Write Ahread Logging
DBWR가 dirty 버퍼를 디스크에 저장하기 전에 Redo 로그를 남기는 (= Redo 버퍼를 비우고 Redo 로그 파일에 저장하는) 이유는 나중에 복구하기 위해서이다.
이렇게 하지 않으면(커밋 여부를 기록하지 않고 데이터 파일에 바로 기록하게 되면) 나중에 redo 로그를 보고 복구된 (roll-forward) 캐시에서 커밋되지 않은 트랜잭션을 undo 할 수가 없다. (rollback)
이렇게 데이터 파일에 쓰기 전에 로그부터 남기는 것을 Write Ahead Logging 방식이라고 한다.
4. 다음 중 메모리 구조에 대한 설명으로 가장 부적절한 것은?
- DB 버퍼 캐시는 데이터 파일로 읽어 들인 데이터 블록을 담는 캐시 영역이다.
/*+ append */힌트를 사용하면 Insert 시 DB 버퍼 캐시를 거치지 않고 디스크에서 직접 쓴다.- 클러스터링 팩터가 좋은 인덱스를 사용하면 Buffer Pinning 효과로 I/O를 줄일 수 있다.
- LRU(Least Recently Used) 알고리즘에 따라, Table Full Scan 한 데이터 블록이 Index Range Scan 한 데이터 블록보다 DB 버퍼 캐시에 더 오래 머무른다.
정답: 4
-
데이터 블록을 읽으면 DB 버퍼 캐시에 올라간다.
나중에 찾을 때 해시버킷에서 찾아서 쓴다.
DB 버퍼 캐시는 LRU 알고리즘으로 관리된다. -
/*+ append */힌트를 사용하면 direct-path로 INSERT 할 수 있다. direct-path 란 데이터가 지금 있는 공간을 사용하지 않고 그 바로 뒤에 새로 추가하는 것을 말하며, 버퍼 캐시를 우회해서 데이터 파일에 바로 쓰여진다. 그 결과로 direct-path INSERT는 기존 INSERT 보다 훨씬 빠르다. -
클러스터링 팩터가 좋다는 것은 인덱스로 찾아 들어갔을 때 leaf가 같은 블록에 모여있다는 것이다.
그렇다면 인덱싱 한 칼럼의 특정 범위로 찾을 수 있는 테이블의 row들은 한 블록에 모여있을 가능성이 크다.
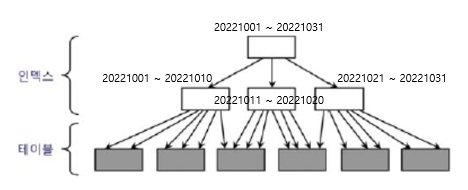 위의 경우 2022년 10월 13일부터 15일까지에 해당하는 데이터는 한 블록에 모여있을 것이다. 이때 같은 블록을 여러 번 읽으므로, 그 블록을 pin 해두면 I/O 성능이 좋아진다.
위의 경우 2022년 10월 13일부터 15일까지에 해당하는 데이터는 한 블록에 모여있을 것이다. 이때 같은 블록을 여러 번 읽으므로, 그 블록을 pin 해두면 I/O 성능이 좋아진다. -
Table Full Scan 한 데이터 블록은 LRU end에 위치하기 때문에 버퍼 캐시에 오래 머물지 않는다. 오라클은 tabel full scan 에서 찾아진 블록들을 LRU end에 둔다. 왜냐면 full scan은 아주 가끔 있는 일이라고 판단해서 다른 블록보다 캐싱될 확률이 적다고 생각하기 때문이다.
참조
5. 다음 중 Response Time Analysis 성능 관리 방법론을 설명할 때, 아래 괄호 안에 들어갈 가장 적절한 용어 2개를 고르시오.
정답/해설정답: Response Time = Service Time + Wait Time = CPU Time + Queue Time
출처
Response Time = Service Time + Wait Time = CPU Time + Queue Time
6. DB 인스턴스를 기동한 직후, 아래 SQL1)을 포함하는 프로그램을 사원 A와 B가 아래와 같이 각각 4회씩 연속적으로 수행하였다. SQL1)에 대한 Hard Parsing은 몇 번 발생하겠는가?
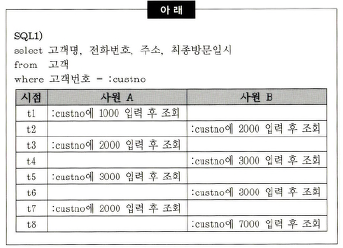
정답: 1
1회 발생한다. custno는 바인드 변수이기 때문에, 1000을 넣어도 2000을 넣어도 같은 쿼리, 같은 실행 계획으로 실행된다.
따라서 해당 SQL문은 Hard Parsing이 1회 실행된다.
7. SQL*Plus나 TOAD같은 쿼리 툴로 오라클 데이터베이스 ORDER 계정에 접속해서 아래 SQL을 각각 한번씩 순차적으로 실행했다. 다음 중 SQL 파싱에 대한 설명으로 가장 적절한 것은?

정답: 1
1. 첫 번째 수행될 때 각각 하드파싱을 일으키고, 다른 캐시 공간을 사용할 것이다.
SQL문을 실행하면 하드 파싱 되어 SGA 내 공유 풀, 공유 풀 내 라이브러리 캐시에 저장된다.
다만 이는 SQL문으로 찾을 수 있기 때문에, 같은 SQL문이라도 토씨 하나 틀리면 다른 문이 된다.
따라서 위 세 SQL문은 각각 하드파싱이 반복된다.
8. 공통가술팀에서개발표준 업무를담당하는 고성능싸는개발팀에 SQL 작성을 위한 표준 가이드라인을 제시했다. OLTP 환경의 시스템인 점을 고려해 가급적 바인드 변수를 사용하도록 권고하지만, “Literal 상수 조건을 사용하는 것이 더 낫거나 바인드 변수를 사용하려고 애쓰지 않아도 돠는 경우”를 보기와 같이 제시했다. 다음 중 가장 부적절한 것은?
- 수행빈도가 낮고 한 번 수행할 때 수십 초 이상 수행되는 SQL일 때.
- 조건절 칼럼의 값 종류(Distinct Value)가 소수이고, 값 분포가 균일하지 않을 때
- 사용자가 선택적으로 입력할 수 있는 조회 항목이 다양해서 조건절이 동적으로 바뀔 때
- 사용자가 입력할 수 있는 조회 항목이 아니어서 해당 조건절이 불변일 때
정답: 3
해설
-
바인드 변수를 쓰는 이유는 캐싱된 SQL을 재사용하기 위함이다. 수행빈도가 낮으면 어차피 캐시 버퍼에서 빠지게 돼서 굳이 바인드 변수를 안 써도 된다.
-
값의 분포가 균일하지 않다면 바인드 변수를 쓰는 게 더 느릴 수도 있다. 옵티마이저는 값이 균일하게 분포돼있다는 가정하에 최적하를 수행하기 때문이다.
-
조건절이 복잡한 거랑은 상관 없다. 비교문은 바인드 변수를 쓰는 것이 일반적으로 좋다.
-
불변이면 애초에 바인드 변수를 쓰지 못한다.
9. 다음 중 프로그램을 아래와 같이 작성할 때의 문제점과 가장 거리가 먼 것을 2개 고르시오.

정답: 1, 2
- 불필요한 하드파싱을 많이 일으킨다.
- 테이블 통계정보를 활용하지 못한다.
- 인덱스 전략 수립이 어렵다.
- 실행계획을 제어하기 어렵다.
해설
- 불필요한 하드파싱을 막으려고 바인드 변수를 쓴다.
- 바인드 변수를 쓰면 칼럼 히스토그램을 사용하지 못한다. 다만 다른 통계정보는 활용할 수 있다.
- 선택도에 따라 인덱스 전략이 달라진다. 선택도가 높으면 Full scan, 낮으면 인덱스를 활용하는 것이 좋은데 바인드 변수를 사용하면 이 선택도의 차이가 없이 모두 균일하다고 가정하고 최적화를 하기 때문에 인덱스 전략 수립에 방해를 받는다.
- 바인드 변수를 쓰면 옵티마이저의 실행 계획을 제어하기 어렵다.
10. 다음 중 SQL 작성 방식에 대해 설명으로 가장 부적절한 것은?
- Static SQL이란, String형 변수에 담지 않고 코드 사이에 직접 기술한 SQL문을 말한다.
- Dynamic SQL이란, String형 변수에 담아서 실행하는 SQL문을 말한다.
- Static SQL을 지원하는 개발환경에선 가급적 Static SQL로 작성하는 것이 바람직하다.
- 루프(Loop) 내에서 반복적으로 수행되는 SQL에 Dynamic SQL을 사용하면, 공유 메모리에 캐싱된 SQL을 공유하지 못해 하드 파싱이 반복적으로 일어난다.
정답: 4
해설
Dynamic SQL은 라이브러리 캐시랑은 상관 없다.
애플리케이션 커서 캐싱이 안 되는 것이다.
