특정한 조건의 데이터만 조회하는 <SELECT ... FROM ... WHERE>
SELECT 필드이름 FROM 테이블이름 WHERE 조건식만약 WHERE 조건 없이 다음을 조회해 보자.
USE sqldb;
SELECT * FROM usertbl;지금 usertbl은 우리가 10건의 데이터만 넣었지만, 만약 실제로 대형 인터넷 쇼핑몰의 가입 회원으로 생각하면 수백만 명이 될 수도 있다. 그렇다면 전체 데이터가 스크롤되어 넘어가는 데에도 많은 시간이 걸릴 것이다. 예로, 지금 찾는 이름이 '김경호'라면 수백만 건을 조회한 후에 스크롤해서 찾을 필요는 없다.
SELECT * FROM usertbl WHERE name = '김경호';쿼리 실행 결과

관계 연산자의 사용
1970년 이후에 출생하고 신장이 182 이상인 사람의 아이디와 이름을 조회해 보자.
SELECT userID, Name FROM usertbl WHERE birthYear >= 1970 AND height >= 182;'이승기','성시경' 등 두 고객만 결과에 나올 것이다.
이번에는 1970년 이후에 출생했거나 신장이 182 이상인 사람의 아이디와 이름을 조회해 보자.
SELECT userID, Name FROM usertbl WHERE birthYear >= 1970 OR height >= 182;7명의 결과가 나올 것이다. '...했거나','...또는' 등은 OR 연산자를 사용하면 된다. '...하고','...면서','...그리고'등의 조건은 AND 연산자를 이용하면 된다.
이렇듯 조건 연산자(=, <, >, <=, >=, <>, != 등)와 관계 연산자(NOT, AND, OR 등)를 잘 조합하면 다양한 조건의 쿼리를 생성할 수 있다.
BETWEEN...AND와 IN() 그리고 LIKE
이번에는 키가 180 ~ 183인 사람을 조회해 보자.
SELECT name, height FROM usertbl WHERE height >= 180 AND height <= 183;'임재범', '이승기' 등 2명이 나올 것임.
동일한 방식으로 BETWEEN...AND를 사용할 수 있다.
SELECT name, height FROM usertbl WHERE height BETWEEN 180 mANd 183;=키의 경우에는 숫자로 구성되어 있어서 연속적인 값을 가지므로 BETWEEN...AND를 사용했지만 지역이 '경남'이거나 '전남'이거나 '경북'인 사람을 찾을 경우에 연속된 값이 아니기 때문에 BETWEEN...AND를 사용할 수 없다.
지역이 '경남', '전남', '경북'인 사람의 정보를 확인해 보자.
SELECT name, addr FROM usertbl WHERE addr='경남' OR addr='전남' OR addr='경북';이와 동일하게 연속적인(Continuous) 값이 아닌 이산적인(Discrete)값을 위해 IN()을 사용할 수 있다.
SELECT name, addr FROM usertbl WHERE addr IN ('경남, '전남', '경북');문자열의 내용을 검색하기 위해서는 LIKE 연산자를 사용할 수 있다.
SELECT name ,height FROM usertbl WHERE name LIKE '김%';위 조건은 성이 '김'씨이고 그 뒤는 무엇이든(%) 허용한다는 의미이다. 즉, '김'이 제일 앞 글자인 것들을 추출한다. 그리고 한 글자와 매치하기 위해서는 '_'를 사용한다. 아래는 맨 앞 글자가 한 글자이고, 그 다음이 '종신'인 사람을 조회해 준다.
SELECT name, height FROM usertbl WHERE name LIKE '_종신'; 이 외에도 '%'와 ''를 조합해서 사용할 수 있다. 조건에 '용%'라고 사용하면 앞에 아무거나 한 글자가 오고 두 번째는 '용', 그리고 세 번째 이후에는 몇 글자든 아무거나 오는 값을 추출해 준다.
예를 들어 '조용필, '사용한 사람', '이용해 줘서 감사합니다' 등의 문자열이 해당될 수 있다.
** %나 가 검색할 문자열의 제일 앞에 들어가는 것은 MySQL성능에 나쁜 영향을 끼칠 수 있다. 예로 name열을 '%용'이나 '용필'등으로 검색하면, name열에 인덱스(index)가 있더라도 인덱스를 사용하지 않고 전체 데이터를 검색하게 된다. 지금은 데이터 양이 얼마 되지 않으므로 그 차이를 느낄 수 없겠으나 대용량 데이터를 사용할 경우에는 아주 비효율적인 결과를 낳게 된다.
ANY/ALL/SOME 그리고 서브쿼리(SubQuery, 하위쿼리)
서브쿼리란 간단히 얘기하면 쿼리문 안에 또 쿼리문이 들어 있는 것을 얘기한다. 예로 김경호보다 키가 크거나 같은 사람의 이름과 키를 출력하려면 WHERE 조건에 김경호의 키를 직접 써줘야 한다.
SELECT name, height FROM usertbl WEHRE height > 177;그런데 이 177이라는 키를 직접 써주는 것이 아니라 이것도 쿼리를 통해서 사용하려는 것이다.
SELECT name, height FROM usertbl
WHERE height > (SELECT height FROM usertbl WHERE Name = '김경호');후반부의 (SELECT height FROM usertbl WHERE Name ='김경호)는 177이라는 값을 돌려주므로, 결국 177이라는 값과 동일한 값이 되어서 위 두 쿼리는 동일한 결과를 내주는 것이다.
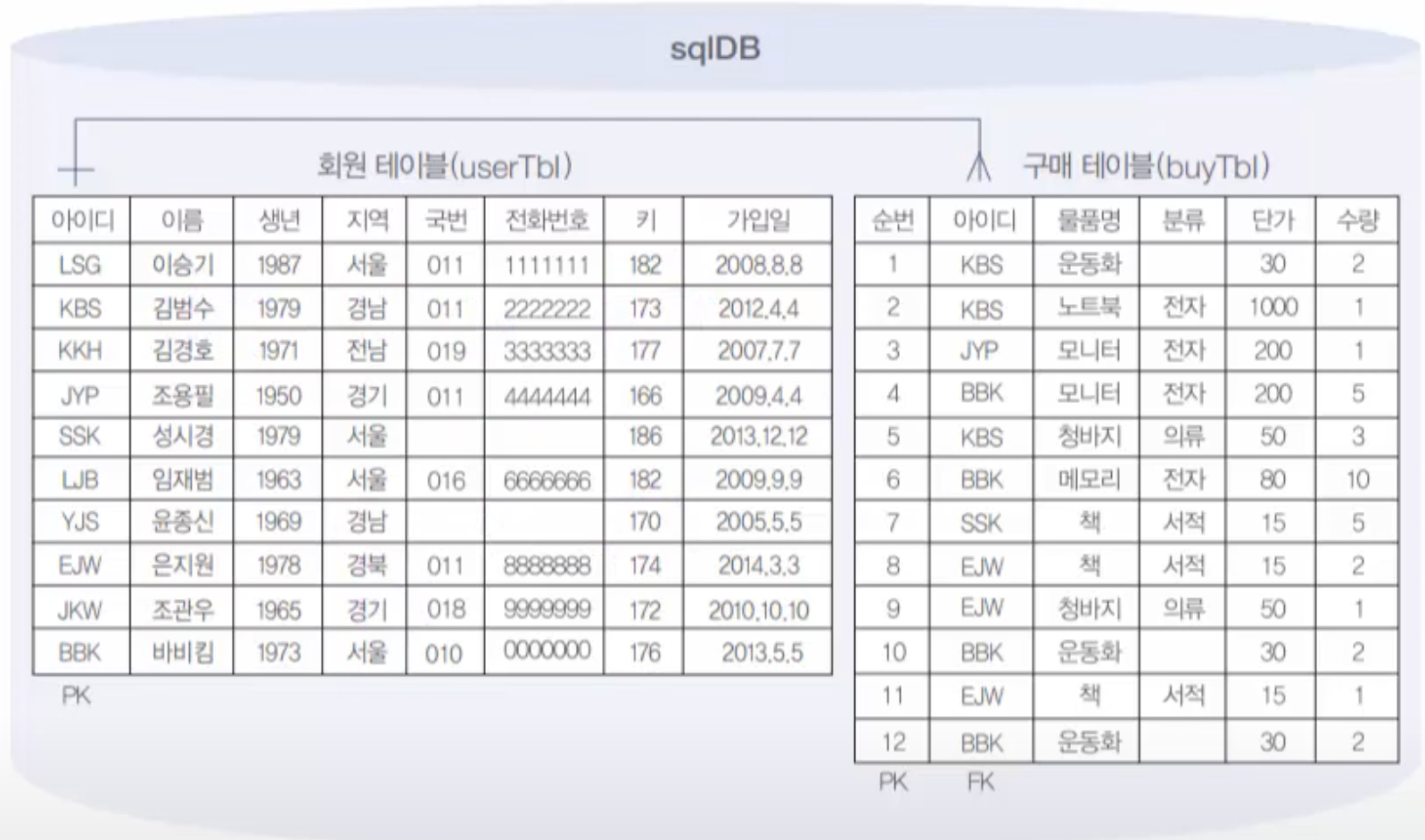
이번에는 지역이 '경남' 사람의 키보다 키가 크거나 같은 사람을 추출해 보자. 경남인 사람은 김범수(키 173)와 윤종신(키 170)이므로 173또는 170보다 작은 조용필을 제외한 나머지 9명이 출력된다.
SELECT name, height FROM usertbl
WHERE height >= (SELECT height FROM usertbl WHERE addr = '경남'); 
쿼리 실행 결과 논리적으로 틀린 것은 없는 듯하지만, 오류가 나온다. 오류 메시지를 보니 하위쿼리가 둘 이상의 값을 반환하기 때문이다. 즉 (SELECT height FROM usertbl WHERE addr='경남')이 173과 170이라는 두 개의 값을 반환하기 때문에 오류가 나는 것이다.
그래서 필요한 구문이 ANY 구문이다. 다음과 같이 고쳐서 실행해 보자.
SELECT name, height FROM usertbl
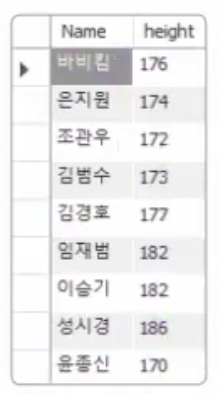
WHERE height >= ANY (SELECT height FROM usertbl WHERE addr = '경남'); 예상한대로 키가 173보다 크거나 같은 사람 또는 키가 170보다 크거나 같은 사람이 모두 출력될 것이다. 결국 키가 170보다 크거나 작은 사람이 해당된다.
이번에는 ANY를 ALL로 바꿔서 실행해 보자. 7명만 출력되었다. 그 이유는 키가 170보다 크거나 같아야 할 뿐만 아니라, 173보다 크거나 같아야 하기 때문이다. 결국 173보다 크거나 같은 사람만 해당된다.
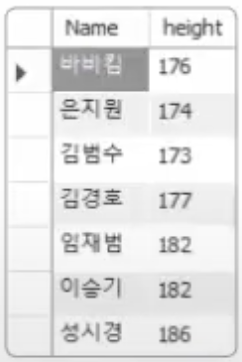
결론적으로 ANY는 서브쿼리의 여러 개의 결과 중 한 가지만 만족해도 되며, ALL은 서브쿼리의 여러 개의 결과를 모두 만족시켜야 한다. 참고로 SOME은 ANY와 동일한 의미로 사용된다.
이번에는 '>=ANY' 대신에 '=ANY'를 사용해 보자.
SLECT name, height FROM usertbl
WHERE height = ANY (SELECT height FROM usertbl WHERE addr = '경남'); 
정확히 ANY 다음의 서브쿼리 결과와 동일한 값인 173, 170에 해당하는 사람만 출력되었다.
이는 다음과 동일한 구문이다. 즉 '=ANY(서브쿼리)'는 'IN(서브쿼리)'와 동일한 의미다.
SELECT name, height FROM usertbl
WHERE height IN (SELECT height FROM usertbl WHERE addr = '경남');원하는 순서대로 정렬하여 출력: ORDER BY
ORDER BY절은 결과물에 대해 영향을 미치지는 않지만, 결과가 출력되는 순서를 조절하는 구문이다.
먼저 가입한 순서로 회원들을 출력해 보자.
SELECT name, mDate FROM usertbl ORDER BY mDate;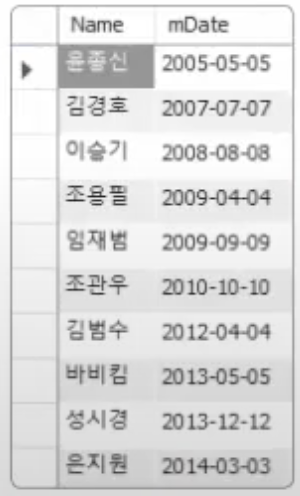
기본적으로 오름차순(ASCENDING)으로 정렬된다. 내림차순(DESCENDING)으로 정렬하기 위해서는 열 이름뒤에 DESC라고 적어주면 된다.
SELECT name, mDate FROM usertbl ORDER BY mDate DESC;이번에는 여러 개로 정렬해 보자. 키가 큰 순서로 정렬하되 만약 키가 같은 경우에 이름 순으로 정렬하려면 다음과 같이 사용하면 된다. ASC(오름차순)는 디폴트 값이므로 생략해도 된다.
SELECT name, height FROM usertbl ORDER BY height DESC, name ASC;ORDER BY절은 SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY 중에서 제일 뒤에 와야 한다.
** ORDER BY절은 MySQL의 성능을 상당히 떨어뜨릴 소지가 있다. 꼭 필요한 경우가 아니라면 되도록 사용하지 않는 것이 좋다.
중복된 것은 하나만 남기는 DISTINCT
회원 테이블에서 회원들의 거주지역이 몇 군데인지 출력해 보자.
SELECT addr FROM usertbl;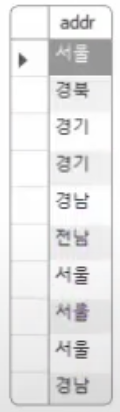
10개 행밖에 안 되는 데도 중복된 것을 새는 것이 어렵다. 조금 전에 배운 ORDER BY를 사용해 보자.
SELECT addr FROM usertbl ORDER BY addr; 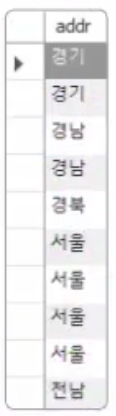
아까보다는 쉽지만 그래도 중복된 것을 골라서 세기가 좀 귀찮다. 또 몇 만 건이라면 정렬이 되어있어도 세는 것을 포기해야 할 것이다. 이때 사용하는 구문이 DISTINCT다.
SELECT DISTINCT addr FROM usertbl; 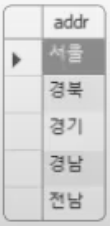
중복된 것은 1개씩만 보여주면서 출력되었다.
출력하는 개수를 제한하는 LIMIT
이번에는 employees DB를 잠깐 사용해 보자. hire_date(회사 입사일)열이 있는데, 입사일이 오래된 직원 5명의 emp_no(사원번호)를 알고 싶다면 어떻게 해야 할까? 조금 전에 배운 ORDER BY절을 사용하면 된다. 먼저 쿼리 창 상단의 개수 제한에서 제한 없음(Don't Limit)을 선택하고 다음 쿼리를 실행하자.
USE employees;
SELECT emp_no, hire_date FROM employees
ORDER BY hire_date ASC; 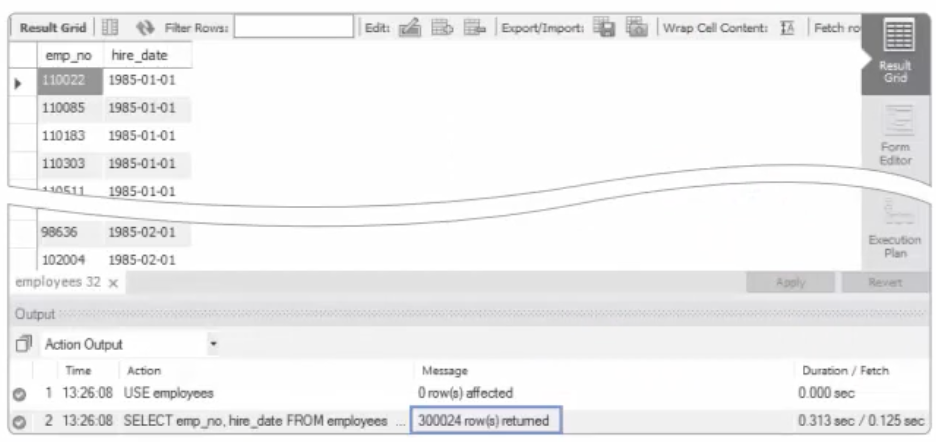
위의 결과에서 제일 앞의 5건만 사용하면 된다. 그런데, 5건을 보기 위해서 필요 없는 약 30만 건을 더 출력하였다. 어쩌면 이런 것이 별것 아니라고 생각할 수도 있겠지만, 이러한 조회가 자주 일어난다면 필요 없는 부담을 MySQL에게 많이 주는 것이다. 그래서 상위의 N개만 출력하는 'LIMIT N'구문을 사용하면 된다.
USE employees;
SELECT emp_no, hire_date FROM employees
ORDER BY hire_date ASC
LIMIT 5; 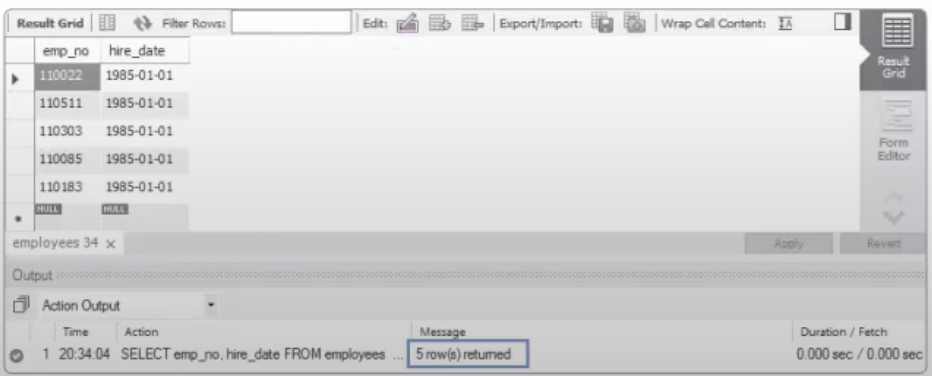
LIMIT절은 'LIMIT 시작, 개수'또는 'LIMIT 개수 OFFSET 시작'형식으로도 사용할 수 있다. 시작은 0부터 시작이다. 그러므로 5개를 출력하기 위해서는 다음과 같이 사용해도 된다.
SELECT emp_no, hire_date FROM employees
ORDER BY hire_date ASC
LIMIT 0, 5; -- LIMIT 5 OFFSET 0과 동일실무팁 - 악성 쿼리문
악성 쿼리문이란 서버의 처리량을 많이 사용해서 결국 서버의 전반적인 성능을 나쁘게 하는 쿼리문을 뜻한다. 비유를 하자면 많은 사람(쿼리문)이 표를 끊기 위해서(처리되기 위해) 줄 서 있는데, 어떤 사람(악성 쿼리문)이 계속 판매원에게 필요치 않은 질문을 던져서 뒤에 서 있는 다른 많은 사람이 표를 끊는데 시간이 오래 걸리는 것과 같은 이치다. 지금은 SQL문의 문법을 배우는 과정이므로 결과만 나온다면 잘 된 것처럼 느껴지겠지만, 실무에서는 얼만큼 효과적으로 결과를 얻느냐가 더욱 중요한 이슈가 된다. 잘못된 악성쿼리를 자꾸 만들지 않도록 더욱 신경을 써서 SQL문을 만들 필요가 있다.
테이블을 복사하는 CREATE TABLE...SELECT
CREATE TABLE...SELECT 구문은 테이블을 복사해서 사용할 경우에 주로 사용된다.
형식
CREATE TABLE 새로운 테이블 (SELECT 복사할열 FROM 기존테이블)다음은 buytbl을 buytbl2로 복사하는 구문이다.
USE sqldb;
CREATE TABLE buytbl2 (SELECT * FROM buytbl);
SELECT * FROM buytbl2;필요하다면 지정한 일부 열만 복사할 수도 있다.
CREATE TABLE buytbl3 (SELECT userID, prodName FROM buytbl);
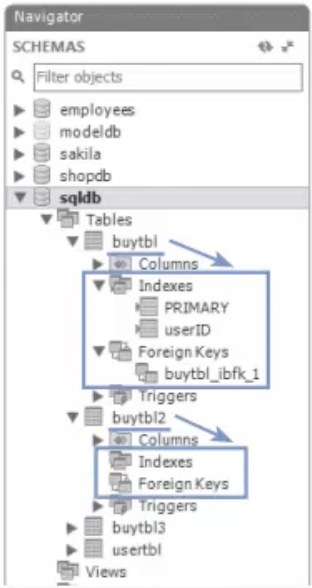
SELECT * FROM buytbl3;그런데, buytbl은 Primary Key 및 Foreign Key가 지정되어 있다. 그것들도 복사가 될까? Workbench의 [Navigator]에서 확인해 보면 PK나 FK 등의 제약조건은 복사되지 않는 것을 알 수 있다.