GROUP BY 및 HAVING 그리고 집계 함수
GROUP BY절
이제는 SELECT 형식 중에서 GROUP BY, HAVING절에 대해서 파악해 보자.
형식 :
SELECT select_expr
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name ¦ expr ¦ position}]
[HAVING where_condition]
[ORDER BY {col_name ¦ expr ¦ position}]먼저 GROUP BY절을 살펴보자. 이 절이 말 그대로 그룹으로 묶어주는 역할을 한다. sqlDB의 구매 테이블(buytbl)에서 사용자(userID)가 구매한 물품의 개수(amount)를 보려면 다음과 같이 하면 된다.
USE sqldb;
SELECT userID, amount FROM buytbl ORDER BY userID;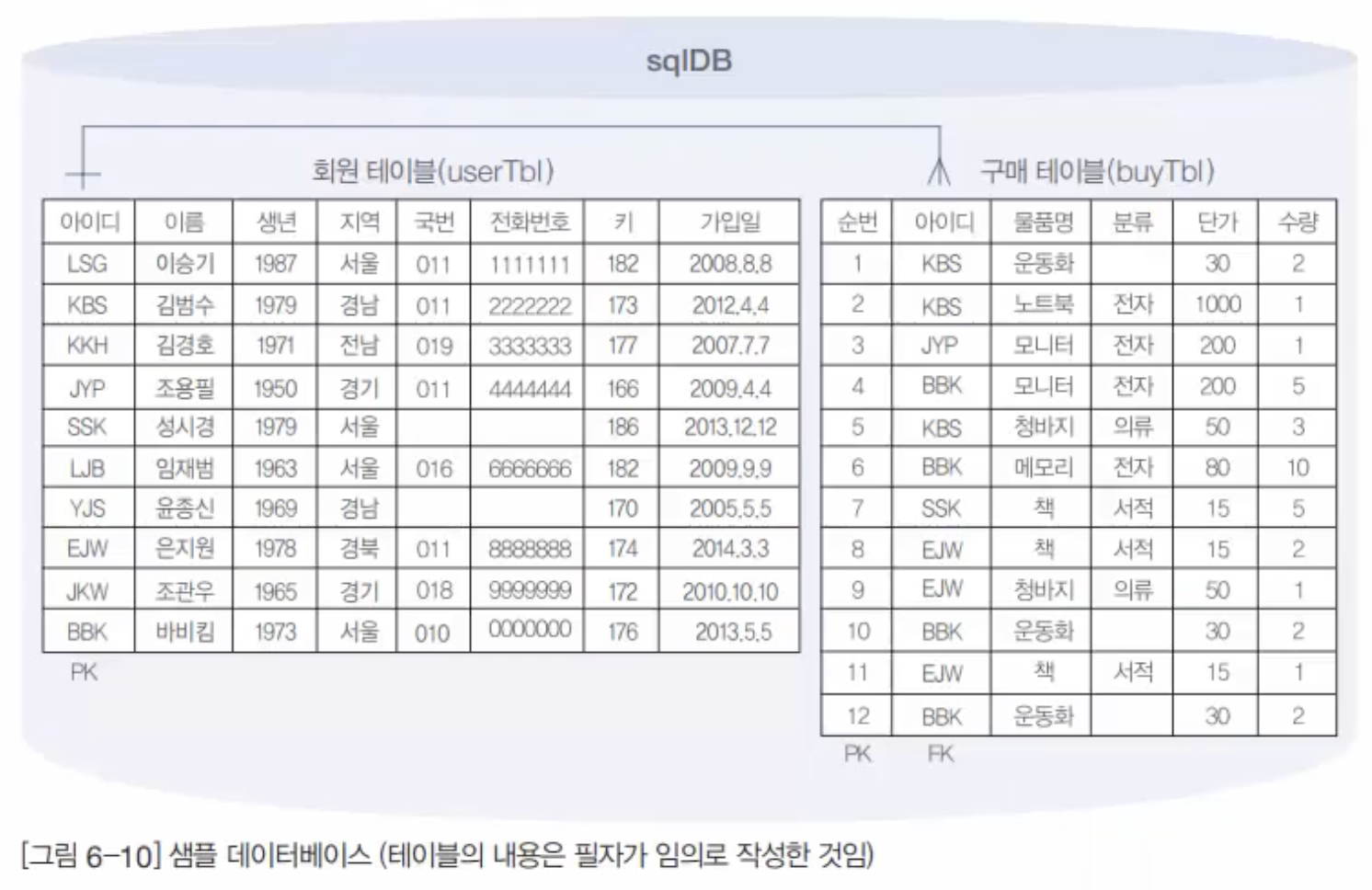
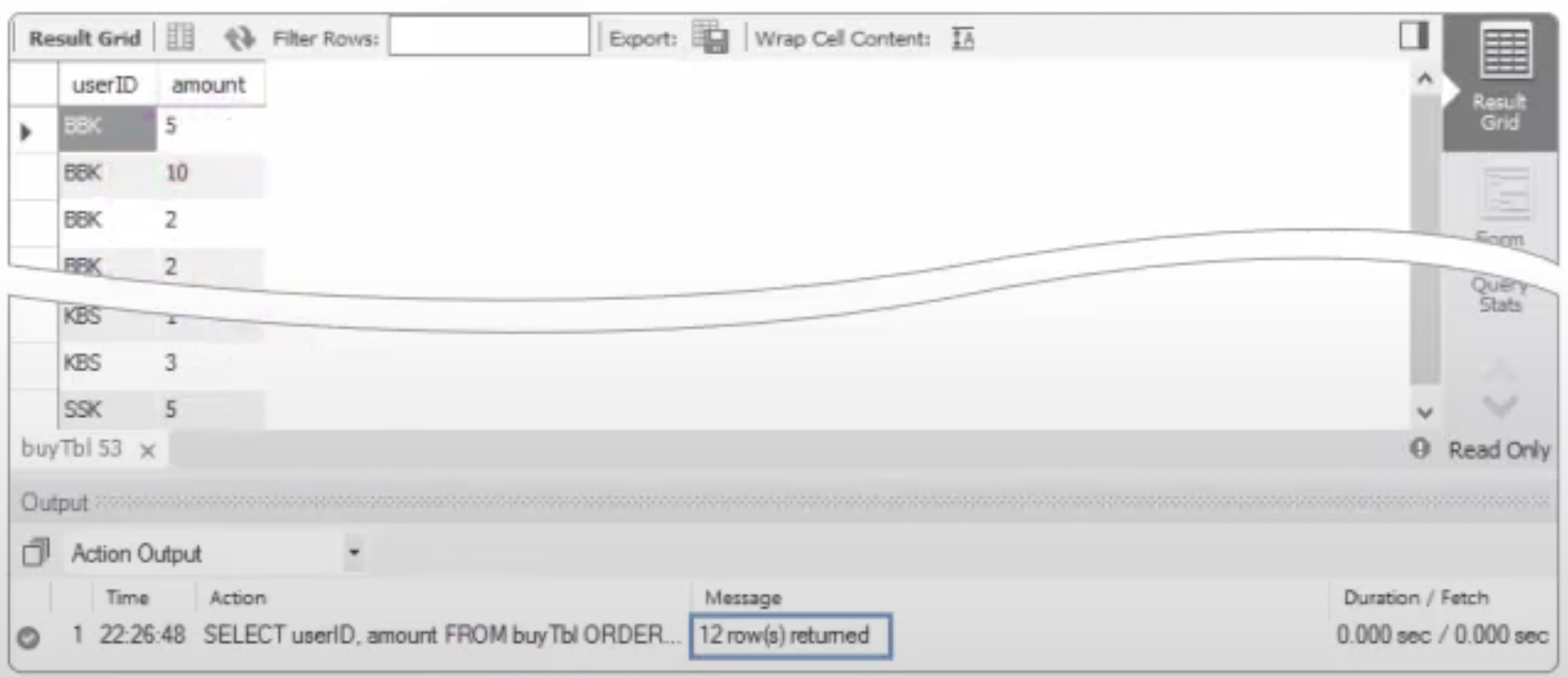
결과를 보면 사용자별로 여러 번의 물건 구매가 이루어져서 각각의 행이 별도로 출력된다. BBK 사용자의 경우에는 5+10+2+2=19개의 구매를 했다. 합계를 낼 때 이렇게 손이나 전자계산기를 두드려서 계산한다면 MySQL을 사용할 이유가 없을 것이다.
이럴 때는 집계 함수를 사용하면 된다. 집계 함수(Aggregate Function)는 주로 GROUP BY절과 함께 쓰이며 데이터를 그룹화(Grouping)해주는 기능을 한다.
위의 결과에서 우리가 원하는 바는 BBK:19개, EJW:4개, JYP:1개, KBS:6개, SSK:5개 와 같이 각 사용자(userID)별로 구매 개수(amount)를 합쳐서 출력하는 것이다. 이럴 경우에는 집계 함수인 SUM()과 GROUP BY절을 사용하면 된다. 즉, 사용자(userID)별로 GROUP BY로 묶어준 후에 SUM()함수로 구매 개수(amount)를 합치면 된다.
SELECT userID, SUM(amount) FROM buytbl GROUP BY userID;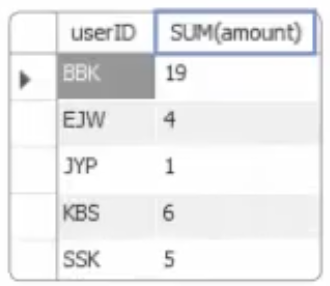
그런데, SUM(amount)의 결과 열에는 제목이 함수 이름 그대로 나왔다. 전에 배운 별칭alias을 사용해서 결과를 보기 편하게 만들자.\
SELECT userID AS '사용자 아이디', SUM(amount) AS '총 구매 개수' FROM buytbl GROUP BY userID;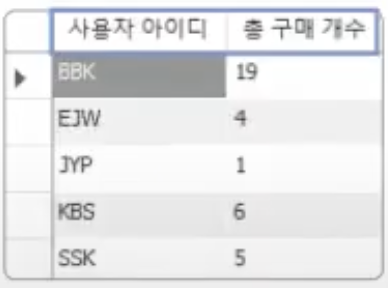
이번에는 구매액의 총합을 출력하자. 구매액은 가격(price) * 수량(amount)이므로, 총합은 SUM()을 사용하면 된다.
SELECT userID AS '사용자 아이디', SUM(price*amount) AS '총 구매액' FROM buytbl GROUP BY userID;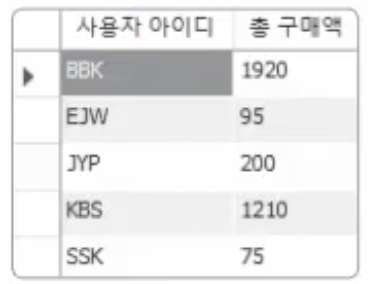
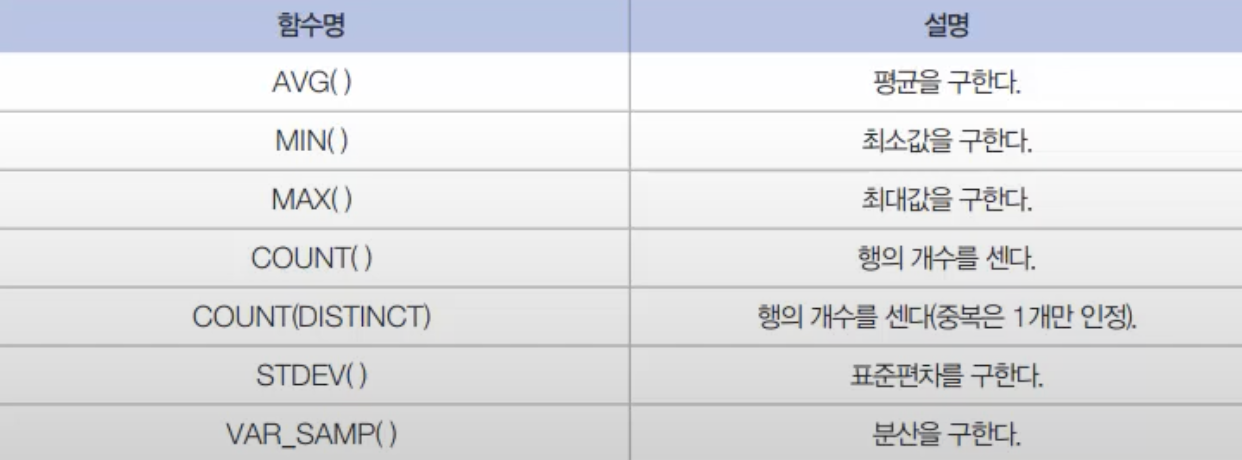
집계 함수
전체 구매자가 구매한 물품의 개수(amount)의 평균을 구해보자.
USE sqldb;
SELECT AVG(amount) AS '평균 구매 개수' FROM buytbl;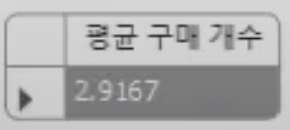
이번에는 각 사용자 별로 한 번 구매 시 물건을 평균 몇 개 구매했는지 평균을 내보자. GROUP BY를 사용하면 된다.
SELECT userID, AVG(amount) AS '평균 구매 개수' FROM buytbl GROUP BY userID;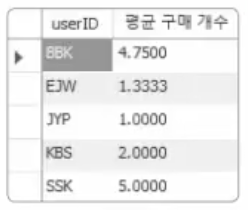
다른 예를 살펴보자. 가장 큰 키와 가장 작은 키의 회원 이름과 키를 출력하는 쿼리를 만들어서 직접 실행해 보자.
SELECT name, Max(height), MIN(height) FROM usertbl;
결과가 예상한 대로는 아니다. 가장 큰 키와 가장 작은 키는 나왔으나, 이름은 하나뿐이라서 어떤 것에 해당하는지 알 수가 없다. GROUP BY를 활용해서 다음과 같이 고쳐보았다.
SELECT name, MAX(height), MIN(height) FROM usertbl GROUP BY Name;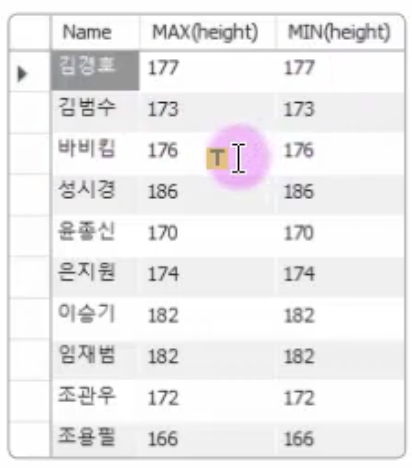
역시 원하는 결과가 아니다. 그냥 모두 다 나왔다. 이런 경우에는 앞에서 배운 서브쿼리와 조합을 하는 것이 제일 수월하다.
SELECT name, height
FROM usertbl
WHERE height = (SELECT MAX(height) FROM usertbl)
OR height = (SELECT MIN(height) FROM usertbl) ;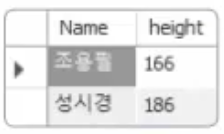
이번에는 휴대폰이 있는 사용자의 수를 카운트하자.
SELECT COUNT(*) FROM usertbl;위 쿼리의 결과는 전체 회원인 10명이 나올 것이다. 휴대폰이 있는 회원만 카운트하려면 휴대폰 열이름(mobile1)을 지정해야 한다. 그럴 경우에, NULL 값인 것은 제외하고 카운트를 한다.
SELECT COUNT(mobile1) AS '휴대폰이 있는 사용자' FROM usertbl;
Having절
앞에서 했던 SUM()을 다시 사용해서 사용자별 총 구매액을 구해보자.
USE sqldb;
SELECT userID AS '사용자', SUM(price*amount) AS '총구매액'
FROM buytbl
GROUP BY userID;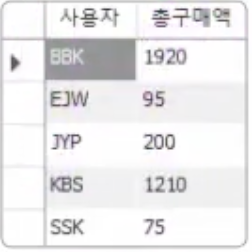
그런데, 이 중에서 총 구매액이 1,000이상인 사용자에게만 사은품을 증정하고 싶다면 앞에서 배운 조건을 포함하는 WHERE구문을 생각했을 것이다.
SELECT userID AS '사용자', SUM(price*amount) AS '총구매액'
FROM buytbl
WHERE SUM(price*amount) > 1000
GROUP BY userID;
오류 메시지를 보면 집계 함수는 WHERE절에 나타날 수 없다는 얘기다. 이럴 때 사용되는 것이 HAVING절이다. HAVING은 WHERE와 비슷한 개념으로 조건을 제한하는 것이지만, 집계 함수에 대해서 조건을 제한하는 것이라고 생각하면 된다. 그리고 HAVING절은 꼭 GROUP BY절 다음에 나와야 한다. 순서가 바뀌면 안된다.
SELECT userID AS '사용자', SUM(price*amount) AS '총구매액'
FROM buytbl
GROUP BY userID
HAVING SUM(price*amount) > 1000 ;
추가로 총 구매액이 적은 사용자부터 나타내려면 ORDER BY를 사용하면 된다.
SELECT userID AS '사용자', SUM(price*amount) AS '총구매액'
FROM buytbl
GROUP BY userID
HAVING SUM(price*amount) > 1000 ;
ORDER BY SUM(price*amount) ;ROLLUP
총합 또는 중간 합계가 필요하다면 GROUP BY절과 함께 WITH ROLLUP문을 사용하면 된다.
만약 분류(groupName)별로 합계 및 그 총합을 구하고 싶다면 다음의 구문을 사용하자.
SELECT num, groupName, SUM(price*amount) AS '비용'
FROM buytbl
GROUP BY groupName, num
WITH ROLLUP;
중간에 num열이 NULL로 되어 있는 추가된 행이 각 그룹의 소합계를 의미한다. 또 마지막 행은 각소합계의 합계, 즉 총합계의 결과가 나왔다.
위 구문에서 num은 Primary Key이며, 각 항목이 보이는 효과를 위해서 넣어 준 것이다. 만약 소합계 및 총합계만 필요하다면 다음과 같이 num을 빼면 된다.
SELECT groupName, SUM(price*amount) AS '비용'
FROM buytbl
GROUP BY groupName
WITH ROLLUP;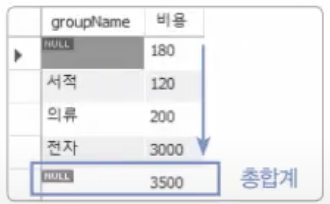
이로써 기본적인 SELECT문의 틀을 살펴보았다.
형식 :
SELECT select_expr
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name ¦ expr ¦ position}]
[HAVING where_condition]
[ORDER BY {col_name ¦ expr ¦ position}]SQL의 분류
DML
Data Manipulation Language: 데이터 조작 언어
데이터를 조작(선택,삽입,수정,삭제)하는 데 사용되는 언어다. DML 구문이 사용되는 대상은 테이블의 행이다. 그러므로 DML을 사용하기 위해서는 꼭 그 이전에 테이블이 정의되어 있어야 한다.
SQL문 중에 SELECT, INSERT, UPDATE, DELETE가 이 구문에 해당한다. 또, 트랜잭션이 발생하는 SQL도 이 DML이다.
트랜잭션이란 쉽게 표현하면, 테이블의 데이터를 변경(입력/수정/삭제)할 때 실제 테이블에 완전히 적용하지 않고, 임시로 적용시키는 것을 말한다. 그래서 만약 실수가 있었을 경우에 임시로 적용시킨 것을 취소시킬 수 있게 해준다.
*SELECT도 트랜잭션을 발생시키기는 하지만, INSERT/UPDATE/DELETE와는 조금 성격을 달리하므로 별도로 생각하는 것이 좋다.
DDL
Data Definition Language: 데이터 정의 언어
데이터베이스, 테이블, 뷰, 인덱스 등의 데이터베이스 개체를 생성/삭제/변경하는 역할을 한다. 자주 사용하는 DDL은 CREATE, DROP, ALTER 등이다. 한 가지 기억할 것은 DDL은 트랜잭션을 발생시키지 않는다는 것이다. 따라서 되돌림(ROLLBACK)이나 완전 적용(COMMIT)을 시킬 수가 없다. 즉, DDL문은 실행 즉시 MySQL에 적용된다.
DCL
Data Control Language: 데이터 제어 언어
사용자에게 어떤 권한을 부여하거나 빼앗을 때 주로 사용하는 구문으로, GRANT/REVOKE/DENY등이 이에 해당된다.
