데이터의 변경을 위한 SQL문
데이터의 삽입: INSERT
INSERT문 기본
테이블에 데이터를 삽입하는 명령어.
기본적인 형식 :
INSERT [INTO] 테이블[(열1, 열2, ...)] VALUES (값1, 값2 ...)우선 테이블 이름 다음에 나오는 열은 생략이 가능하다. 하지만, 생략할 경우에 VALUES 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 열 순서 및 개수와 동일해야 한다.
USE sqldb;
CREATE TABLE testTbl1 (id int, userName char(3), age int);
INSERT INTO testTbl1 VALUES (1, '홍길동', 25);만약, 위의 예에서 id와 이름만을 입력하고 나이를 입력하고 싶지 않다면 다음과 같이 테이블 이름 뒤에 입력할 열의 목록을 나열해줘야 한다.
INSERT INTO testTbl1(id, userName) VALUES (2, '설현');이 경우 생략한 age에는 NULL 값이 들어간다.
열의 순서를 바꿔서 입력하고 싶을 때는 꼭 열 이름을 입력할 순서에 맞춰 나열해 줘야 한다.
INSERT INTO testTbl1(userName, age, id) VALUES ('하니', 26, 3);자동으로 증가하는 AUTO_INCREMENT
테이블의 속성이 AUTO_INCREMENT로 지정되어 있다면, INSERT에서는 해당 열이 없다고 생각하고 입력하면 된다. AUTO_INCREMENT는 자동으로 1부터 증가하는 값을 입력해 준다.
AUTO_INCREMENT로 지정할 때는 꼭 PRIMARY KEY 또는 UNIQUE로 지정해 줘야 하며 데이터 형은 숫자 형식만 사용할 수 있다. AUTO_INCREMENT로 지정된 열은 INSERT문에서 NULL값을 지정하면 자동으로 값이 입력된다.
USE sqldb;
CREATE TABLE testTbl2
(id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
INSERT INTO testTbl2 VALUES (NULL, '지민', 25);
INSERT INTO testTbl2 VALUES (NULL, '유나', 22);
INSERT INTO testTbl2 VALUES (NULL, '유경', 21);
SELECT * FROM testTbl2;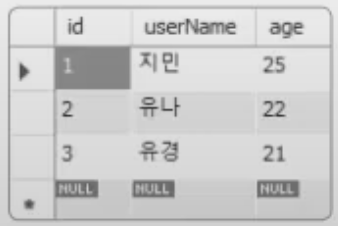
계속 입력을 하다 보면 현재 어느 숫자까지 증가되었는지 확인할 필요도 있다. SELECT LAST_INSERT_ID(); 쿼리를 사용하면 마지막에 입력된 값을 보여준다. 이 경우에는 3을 보여줄 것이다. 그런데 이후에는 AUTO_INCREMENT 입력값을 100부터 입력되도록 변경하고 싶다면 다음과 같이 수행하면 된다.
ALTER TABLE testTbl2 AUTO_INCREMENT=100;
INSERT INTO testTbl2 VALUES (NULL, '찬미', 23);
SELECT * FROM testTbl2;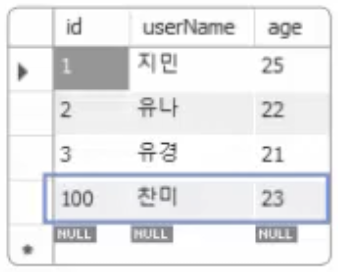
증가값을 지정하려면 서버 변수인 @@auto_increment_increment 변수를 변경시켜야 한다.
다음 예제는 초깃값을 1000으로 하고 증가값은 3으로 변경하는 예제다.
USE sqldb;
CREATE TABLE testTbl3
(id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
ALTER TABLE testTbl3 AUTO_INCREMENT=1000;
SET @@auto_increment_increment=3;
INSERT INTO testTbl3 VALUES (NULL, '나연', 20);
INSERT INTO testTbl3 VALUES (NULL, '정연', 18);
INSERT INTO testTbl3 VALUES (NULL, '모모', 19);
SELECT * FROM testTbl3;
*한꺼번에 Insert
여러 개의 행을 한꺼번에 입력할 수도 있다. 3건의 데이터를 한 문장에서 다음과 같이 입력할 수도 있다.
INSERT INTO 테이블이름 VALUES (값1,값2...) , (값3,값4...), (값5,값6...);대량의 샘플 데이터 생성
이번에는 샘플 데이터를 입력하는 경우를 생각해보자. 지금까지 했던 방식으로 직접 키보드에 입력하려면 많은 시간이 걸릴 것이다. 이럴 때 INSERT INTO ... SELECT 구문을 사용할 수 있다. 이는 다른 테이블의 데이터를 가져와서 대량으로 입력하는 효과를 낸다.
형식:
INSERT INTO 테이블이름 (열 이름1, 열 이름2, ...)
SELECT문 ;물론, SELECT문의 결과 열의 개수는 INSERT를 할 테이블의 열 개수와 일치해야 한다.
employees의 데이터를 가져와서 입력해 보자.
USE sqldb;
CREATE TABLE testTbl4 (id int, Fname varchar(50), Lname varchar(50));
INSERT INTO testTbl4
SELECT emp_no, first_name, last_name
FROM employees.employees;결과 메시지:
300024 row(s) affected Records: ~~~이렇듯 기존의 대량의 데이터를 샘플 데이터로 사용할 때 INSERT INTO...SELECT문은 아주 유용하다. 아예, 테이블 정의까지 생략하고 싶다면 앞에서 배웠던 CREATE TABLE...SELECT구문을 다음과 같이 사용할 수도 있다.
USE sqldb;
CREATE TABLE testTbl5
(SELECT emp_no, first_name, last_name FROM employees.employees);데이터의 수정: UPDATE
기존에 입력되어 있는 값을 변경하기 위해서 쓰인다.
UPDATE 테이블이름
SET 열1=값1, 열2=값2 ...
WHERE 조건;UPDATE도 사용법은 간단하지만 주의할 사항이 있다. WHERE절은 생략이 가능하지만 WHERE절을 생략하면 테이블의 전체의 행이 변경되다.
다음 예는 'Kyoichi'의 Lname을 '없음'으로 변경하는 예다. 251건이 변경될 것이다.
UPDATE testTbl4
SET Lname = '없음'
WHERE Fname = 'Kyoichi';만약, 실수로 WHERE절을 빼먹고 UPDATE testTbl4 SET Lname='없음'을 실행했다면 전체 행의 Lname이 모두 '없음'으로 변경된다. 실무에서도 이러한 실수가 종종 일어날 수 있으므로 주의가 필요하다. 원상태로 복구하기 위해서는 많은 복잡한 절차가 필요할 뿐만 아니라 다시 되돌릴 수 없는 경우도 있다.
가끔은 전체 테이블의 내용을 변경하고 싶을 때 WHERE를 생략할 수 있는데, 예로 구매 테이블에서 현재의 단가가 모두 1.5배 인상되었다면 다음과 같이 사용할 수 있다.
USE sqldb;
UPDATE buytbl SET price = price * 1.5;데이터의 삭제: DELETE FROM
DELETE도 UPDATE와 거의 비슷한 개념이다. DELETE는 행 단위로 삭제하는데, 형식은 다음과 같다.
DELETE FROM 테이블이름 WHERE 조건;만약, WHERE문이 생략되면 전체 데이터를 삭제한다.
testTbl4에서 'Aamer'사용자가 필요 없다면 다음과 같은 구문을 사용하면 된다. ('Aamer'라는 이름의 사용자는 200명이 넘게 있다.)
USE sqldb;
DELETE FROM testTbl4 WHERE Fname = 'Aamer';이 예에서는 228건의 행이 삭제될 것이다.
만약 228건의 'Aamer'을 모두 지우는 것이 아니라 'Aamer'중에서 상위 몇 건만 삭제하려면 LIMIT 구문과 함께 사용하면 된다. 다음은 'Aamer'중에서 상위 5건만 삭제된다.
DELETE FROM testTbl4 WHERE Fname = 'Aamer' LIMIT 5;이번에는 대용량 테이블의 삭제에 대해서 생각해 보자. 만약 대용량의 테이블이 더 이상 필요 없다면 어떻게 삭제하는 것이 좋을까? 실습을 통해서 효율적인 삭제가 어떤 것인지 확인하자. 또, 트랜잭션의 개념도 함께 살펴보자.
<실습>
대용량의 테이블을 삭제하자.
USE sqldb;
CREATE TABLE bigTbl1 (SELECT * FROM employees.employees);
CREATE TABLE bigTbl2 (SELECT * FROM employees.employees);
CREATE TABLE bigTbl3 (SELECT * FROM employees.employees);
DELETE FROM bigTbl1;
DROP TABLE bigTbl2;
TRUNCATE TABLE bigTbl3; -- DELETE랑 똑같음
삭제 수행속도 비교

DML문인 DELETE는 트랜잭션 로그를 기록하는 작업 때문에 삭제가 오래 걸린다. 수백 만 건 또는 수천 만 건의 데이터를 삭제할 경우에 한참동안 삭제를 할 수도 있다. DDL문인 DROP문은 테이블 자체를 삭제한다. 그리고 DDL은 트랜잭션을 발생시키지 않는다고 했다. 역시 DDL문인 TRUNCATE문의 효과는 DELETE와 동일하지만 트랜잭션 로그를 기록하지 않아서 속도가 무척 빠르다. 그러므로 대용량의 테이블 전체 내용을 삭제할 때는 테이블 자체가 필요 없을 경우에는 DROP으로 삭제하고, 테이블의 구조는 남겨놓고 싶다면 TRUNCATE로 삭제하는 것이 효율적이다.
조건부 데이터 입력, 변경
앞에서 INSERT문이 행 데이터를 입력해 주는 것에 대해 배웠다. 그러면 기본 키가 중복된 데이터를 입력하면 어떻게 될까? 당연히 입력되지 않는다. 하지만 100건을 입력하고자 하는데 첫 번째 한건의 오류 때문에 나머지 99건도 입력되지 않는 것도 문제가 될 수 있다. MySQL은 오류가 발생해도 계속 진행하는 방법을 제공한다. 실습을 통해서 확인해 보자.
<실습>
간단한 테이블 먼저 만들기
USE sqldb;
CREATE TABLE memberTBL (SELECT userID, name, addr FROM usertbl LIMIT 3) -- 3건만 가져옴
ALTER TABLE memberTBL
ADD CONSTRAINT pk_memberTBL PRIMARY KEY (userID); -- PK를 지정함
SELECT * FROM memberTBL;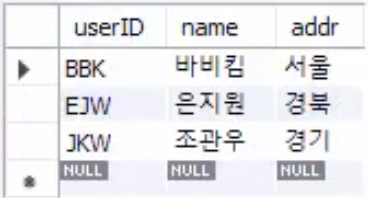
INSERT INTO memberTBL VALUES ('BBK', '비비코', '미국');
INSERT INTO memberTBL VALUES ('SJH', '서장훈', '서울');
ISNERT INTO memberTBL VALUES ('HJY', '현주엽', '경기');
SELECT * FROM memberTBL;
에러가 나는 것을 확인할 수 있다. 첫번째에서 오류가 나면 두번째, 세번째도 실행이 안된다.
INSERT IGNORE INTO memberTBL VALUES ('BBK', '비비코', '미국');
INSERT IGNORE INTO memberTBL VALUES ('SJH', '서장훈', '서울');
ISNERT IGNORE INTO memberTBL VALUES ('HJY', '현주엽', '경기');
SELECT * FROM memberTBL;IGNORE을 쓰면 오류가나도 무시하고 넘어가라는 뜻.

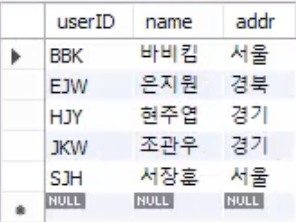
INSERT INTO memberTBL VALUES('BBK', '비비코', '미국')
ON DUPLICATE KEY UPDATE name='비비코', addr='미국';
INSERT INTO memberTBL VALUES('DJM', '동짜몽', '일본)
ON DUPLICATE KEY UPDATE name='동짜몽', addr='일본';
SELECT * FROM memberTBL;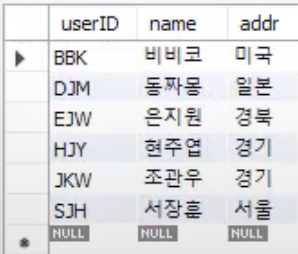
BBK의 addr이 미국으로 변경된 것을 볼 수 있다. 즉 DUPLICATE KEY구문을 쓰면 INSERT 할때 키가 중복된다면 UPDATE되게끔 변경할 수 있다.
WITH절과 CTE
WITH절과 CTE 개요
WITH절은 CTE(Common Table Expression)를 표현하기 위한 구문으로 MySQL 8.0이후부터 사용할 수 있다. CTE는 기존의 뷰, 파생 테이블, 임시 테이블 등으로 사용되던 것을 대신할 수 있으며, 더 간결한 식으로 보여지는 장점이 있다. CTE는 ANSI-SQL99 표준에서 나온 것이다. 기존의 SQL은 ANSI-SQL92를 기존으로 한다. 하지만, 최근의 DBMS는 대게 ANSI-SQL99와 호환되므로 다른 DBMS에서도 같거나 비슷한 방식으로 응용된다.
CTE는 비재귀적(Non_Recusive)CTE와 재귀적(Recursive)CTE 두 가지가 있다. 여기선 주로 사용되는 비재귀적 CTE에 대해서 학습해보자.
비재귀적 CTE
비재귀적 CTE는 말 그대로 재귀적이지 않은 CTE다. 단순한 형태이며, 복잡한 쿼리문장을 단순화 시키는 데에 적합하게 사용될 수 있다.
형식:
WITH CTE_테이블이름(열 이름)
AS
(
<쿼리문>
)
SELECT 열 이름 FROM CTE_테이블이름 ;*비재귀적 CTE에는 SELECT 필드들 FROM CTE_테이블이름 구문 외에 UPDATE 등도 가능하지만, 주로 사용되는 것은 SELECT문이다.
위의 형식이 좀 생소해 보일 수도 있지만, 위쪽을 떼버리고 그냥 SELECT 열 이름 FROM CTE테이블이름 구문만 생각해도 된다. 그런데 이 테이블은 기존에는 실제 DB에 있는 테이블을 사용했지만, CTE는 바로 위의 WITH절에서 정의한 CTE테이블이름을 사용하는 것만 다르다.
즉, WITH CTE_테이블이름(열 이름) AS... 형식의 테이블이 하나 더 있다고 생각하면 된다.
쉽게 이해하기 위해서 앞에서 했던 buyTBL에서 총 구매액을 구하는 것을 다시 살펴보자.
USE sqlDB;
SELECT userid AS '사용자', SUM(price*amount) AS '총구매액'
FROM buyTBL GROUP BY userid;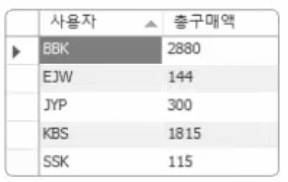
위의 결과를 총 구매액이 많은 사용자 순서로 정렬하고 싶다면 어떻게 해야 할까? 물론, 앞의 쿼리에 이어서 ORDER BY문을 첨가해도 된다. 하지만, 그럴 경우에는 SQL문이 더욱 복잡해 보일 수 있으므로 이렇게 생각해 보자. 위의 쿼리의 결과가 바로 abc라는 이름의 테이블이라고 생각하면 어떨까? 그렇다면, 정렬하는 쿼리는 다음과 같이 간단해진다.
SELECT * FROM abc ORDER BY 총구매액 DESC이것이 CTE의 장점 중 하나다. 구문을 단순화시켜 준다. 지금까지 얘기한 실질적인 쿼리문은 다음과 같이 작성하면 된다.
WITH abc(userid, total)
AS
(SELECT userid, SUM(price*amount)
FROM buytbl GROUP BY userid)
SELECT * FROM abc ORDER BY total DESC;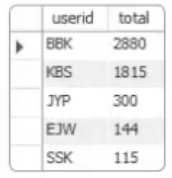
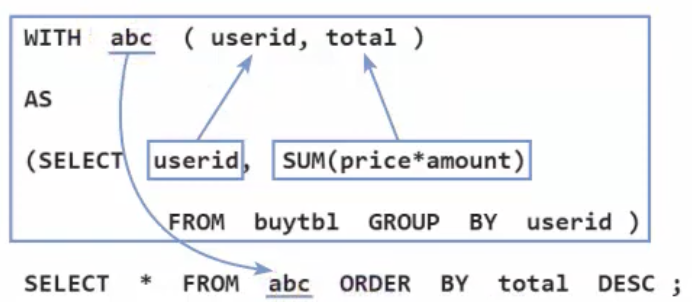
제일 아래의 'FROM abc' 구문에서 abc는 실존하는 테이블이 아니라, 바로 위에 네모로 표시된 WITH구문으로 만든 SELECT의 결과다. 단 여기서 'AS (SELECT ...'에서 조회하는 열과 'WITH abc (...'과는 개수가 일치해야 한다.
다른 예로 하나 더 연습을 해보자. 회원 테이블(userTBL)에서 각 지역별로 가장 큰 키를 1명씩 뽑은 후에, 그 사람들 키의 평균을 내보자. 만약, 전체의 평균이라면 AVG(height)만 사용하면 되지만, 각 지역별로 가장 큰 키의 1명을 우선 뽑아야 하므로 얘기가 좀 복잡해진다. 이럴 때 CTE를 유용하게 사용할 수 있다. 한꺼번에 생각하지 말고, 하나씩 분할해서 생각해 보자.
WITH cte_usertbl(addr, maxHeight)
AS
(SELECT addr, MAX(height) FROM usertbl GROUP BY addr)
SELECT AVG(maxHeight*1.0) AS '각 지역별 최고키의 평균' FROM cte_usertbl;
이제는 복잡한 쿼리를 작성해야 할 경우에 이러한 단계로 분할해서 생각하여 SQL문을 작성할 수 있을 것이다.
CTE는 뷰와 그 용도는 비슷하지만 개선된 점이 많다. 또한, 뷰는 계속 존재하여 사용할 수 있지만 CTE와 파생 테이블은 구문이 끝나면 같이 소멸된다.
