인덱스의 개념
인덱스는 SELECT 검색을 할 때 굉장히 빠르게 찾아줄 수 있다. 그래서 대용량 데이터에서 쓰면 좋다. 소용량 데이터에서 쓰면 오히려 안좋을 수 있다. 또 SELECT는 빠를 수 있지만 INSERT, UPDATE, DELETE 작업은 더 느려질 수 있다.
인덱스는 튜닝에 즉각적인 효과를 내는 가장 빠른 방법 중에 한 가지다. 즉, 인덱스를 생성하고 인덱스를 사용하는 SQL을 만들어 사용한다면, 기존보다 아주 빠른 응답 속도를 얻을 수 있다. 또한 서버 입장에서는 적은 처리량으로 요청한 결과를 얻게 되므로, 다른 요청에 대해서도 많은 일을 할 수 있게 된다. 결과적으로 전체 시스템의 성능이 향상되는 효과도 얻게 된다.
장점
- 검색은 속도가 무척 빨라질 수 있다. (단, 항상 그런 것은 아니다.)
- 그 결과 해당 쿼리의 부하가 줄어들어서, 결국 시스템 전체의 성능이 향상된다.
단점
- 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간이 필요해지는데, 대략 데이터베이스 크기의 10%정도의 추가 공간이 필요하다.
- 처음 인덱스를 생성하는데 시간이 많이 소요될 수 있다.
- 데이터의 변경 작업(INSERT, UPDATE, DELETE)이 자주 일어날 경우에는 오히려 성능이 많이 나빠질 수 있다.
인덱스의 종류와 자동 생성
인덱스의 종류
MySQL에서 사용되는 인덱스의 종류는 크게 두 가지로 나뉘는데, 클러스터형(Clustered) 인덱스와 보조(Secondary) 인덱스다. 이 두개를 비유하면 클러스터형 인덱스는 '영어 사전'과 같은 책이고, 보조 인덱스는 책 뒤에 <찾아보기>가 있는 일반 책과 같다.
- MySQL은 클러스터형 인덱스와 보조 인덱스로 종류를 나누지만, 다른 DBMS에서는 클러스터형 인덱스와 비클러스터형 인덱스로 종류를 나누기도 한다. 즉, 보조 인덱스와 비클러스터형 인덱스는 거의 비슷한 개념이다.
보조 인덱스는 <찾아보기>가 별도로 있고, <찾아보기>를 찾은 후에 그 옆에 표시된 페이지로 가야 실제 찾는 내용이 있는 것을 말한다. 클러스터형 인덱스는 영어 사전처럼 책의 내용 자체가 순서대로 정렬되어 있어서 인덱스 자체가 책의 내용과 같은 것을 말한다.
클러스터형 인덱스는 테이블당 한 개만 생성할 수 있고, 보조 인덱스는 테이블당 여러 개를 생성할 수 있다. 또, 클러스터형 인덱스는 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬한다.
*데이터베이스 튜닝
튜닝이란 SQL 서버가 기존보다 더욱 좋은 성능을 내도록 하는 전반적인 방법론을 말한다. 튜닝은 크게 두 가지 관점으로 볼 수 있다. 하나는 응답시간(Response Time)을 빨리하는 것이다. 즉, A라는 사용자가 쿼리문을 실행하면 '얼마나 빨리 결과를 얻는가'의 문제가 관점이 된다. 이것은 사용자의 입장에서는 아주 효과적인 것처럼 보일 수 있지만, 잘 생각해 봐야 한다. A 사용자는 기존에 1분 걸리던 것을 10초 만에 얻게 된다면, 아주 효과적으로 보일 수도 있고 마치 튜닝이 잘 된 것처럼 보여질 수는 있다. 하지만 서버의 입장에서는 기존에는 1만큼의 작업만 하던 것을100의 작업을 해야 하는 경우도 발생할 수 있다. 이런 경우에는 한 명의 사용자에게는 결과가 빨리 나오겠지만, 전체적인 시스템의 성능은 오히려 나빠질 수도 있다.
자동으로 생성되는 인덱스
이제는 본격적으로 테이블에 적용되는 인덱스를 생각해 보자. 인덱스는 우선 테이블의 열(컬럼) 단위에 생성된다.
하나의 열에 인덱스를 생성할 수도 있고 여러 열에 하나의 인덱스를 생성할 수도 있다. 우선 그냥 하나의 열당 기본적으로 하나의 인덱스를 생성할 수 있다고 생각하자.
sqlDB의 usertbl을 가지고, 인덱스를 생각해 보자.
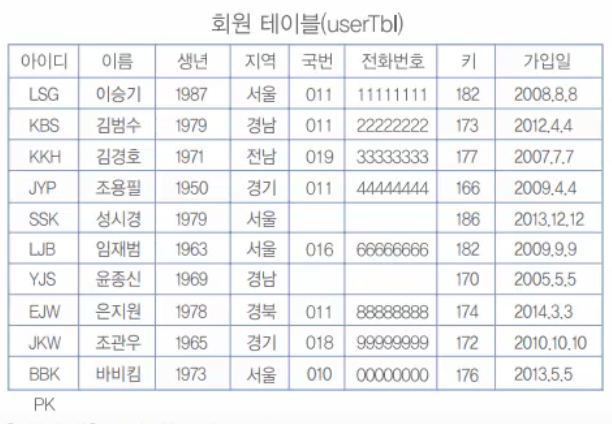
열 하나당 인덱스 하나를 생성하면 이 테이블에는 우선 8개의 서로 다른 인덱스를 생성할 수 있다. 이 테이블을 정의할 때는 다음과 같이 SQL문을 사용했다.
CREATE TABLE usertbl
( userID char(8) NOT NULL PRIMARY KEY,
name varchar(10) NOT NULL,
birthYear int NOT NULL,
......usertbl의 정의 시에 userID를 Primary Key로 정의했다. 이렇게 Primary Key로 지정하면 자동으로 userID열에 클러스터형 인덱스가 생성된다.
'클러스터형 인덱스는 테이블당 한 개만 생성'이라는 내용이 있었다. 그런데, Primary Key는 테이블당 몇 개가 생성이 가능할까? 당연히 기본 키는 테이블당 하나만 생성할 수 있다. 그러므로 기본 키가 지정된 열에 클러스터형 인덱스가 생성되는 것은 자연스러운 일이다.
여기서 테이블 생성 시에 자동으로 생성되는 인덱스의 특징을 한 가지 더 짚고 넘어가자.
테이블 생성 시에 제약 조건 Primary Key 또는 Unique를 사용하면 자동으로 인덱스가 생성된다.
Primary Key: 클러스터형 인덱스
Unique: 보조 인덱스 (unique는 테이블당 여러개 만들 수 있으니까 보조 인덱스는 테이블당 여러개 만들 수 있음)
<실습>
제약 조건으로 자동 생성되는 인덱스를 확인해 보자.
USE sqldb;
CREATE TABLE tbl1
( a INT PRIMARY KEY,
b INT,
c INT
);
SHOW INDEX FROM tbl1;
Key_name이 PRIMARY로 나옴. --> 클러스터형 인덱스다.
Column_name을 확인하면 a열에 인덱스가 만들어졌다는 것을 확인할 수 있다.
Non_unique는 0이므로 중복이 허용되지 않는다는 것이다.
CREATE TABLE tbl2
( a INT PRIMARY KEY,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM tbl2;
인덱스가 3개임.
CREATE TABLE tbl3
( a INT UNIQUE,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM tbl3;
3개열이 모두 보조인덱스임.
CREATE TABLE tbl4
( a INT UNIQUE NOT NULL,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM tbl4;
NULL에 허용이 안되어 있기 때문에 Key_name의 a열은 클러스터형 인덱스라고 보면 된다.
CREATE TABLE tbl5
( a INT UNIQUE NOT NULL,
b INT UNIQUE,
c INT UNIQUE,
d INT PRIMARY KEY
);
SHOW INDEX FROM tbl5;
Column_name의 d열이 클러스터형 인덱스임. Key_name의 a열은 NOT NULL로 되어있긴 하지만 보조인덱스 역할을 하게 된다. 왜냐하면 Primary키가 먼저 클러스터형 인덱스를 가져가기 때문이다.
클러스터형 인덱스로 생성된 열로 자동으로 정렬된다. 확인해보자.
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
DROP TABLE IF EXISTS usertbl;
CREATE TABLE usertbl
( userID char(8) NOT NULL PRIMARY KEY,
name varchar(10) NOT NULL,
birthYear int NOT NULL,
addr nchar(2) NOT NULL
);
INSERT INTO usertbl VALUES('LSG', '이승기', 1987, '서울');
INSERT INTO usertbl VALUES('KBS', '김범수', 1979, '경남');
INSERT INTO usertbl VALUES('KKH', '김경호', 1971, '전남');
INSERT INTO usertbl VALUES('JYP', '조용필', 1950, '경기');
INSERT INTO usertbl VALUES('SSK', '성시경', 1979, '서울');
SELECT * FROM usertbl;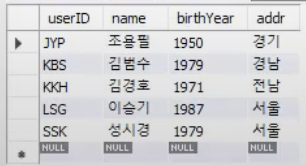
실제 결과를보면 J부터 알파벳 순서대로 정렬되어 나온 것을 확인할 수 있다. userID가 Primary Key로 클러스터형 인덱스이기 때문이다.
ALTER TABLE usertbl DROP PRIMARY KEY;
ALTER TABLE usertbl
ADD CONSTRAINT PK_NAME PRIMARY KEY(name);
SELECT * FROM usertbl;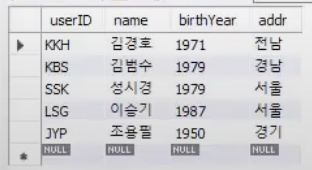
ㄱ,ㄴ,ㄷ 이름순으로 정렬되어 결과가 나온 것을 확인할 수 있다.
즉, 클러스터형 인덱스를 지정하면 클러스터형 인덱스로 된 열로 자동으로 정렬된다.
이번 실습을 통해서 몇 가지 결론을 내릴 수 있다.
- PRIMARY KEY로 지정한 열은 클러스터형 인덱스가 생성된다.
- UNIQUE NOT NULL로 지정한 열은 클러스터형 인덱스가 생성된다.
- UNIQUE(또는 UNIQUE NULL)로 지정한 열은 보조 인덱스가 생성된다.
- PRIMARY KEY와 UNIQUE NOT NULL이 있으면 PRIMARY KEY로 지정한 열에 우선 클러스터형 인덱스가 생성된다.
- PRIMARY KEY로 지정한 열로 데이터가 오름차순 정렬된다.
*제약 조건을 설정할 때 주의할 점
제약 조건의 설정은 대개 테이블의 생성 구문에서 하거나 Alter문으로 생성한다. 그러므로 아직 데이터가 입력되기 전에 Primary Key 및 Unique 키의 열에는 인덱스가 생성되어 있기 때문에, 인덱스 자체를 구성하는 시간이 걸리지는 않는다. 하지만, 많은 데이터가 입력된 후에 Alter문으로 Unique나 Primary를 지정하면 인덱스를 구성하는 데 많은 시간이 걸릴 수도 있다. 즉, 업무시간에 함부로 기존에 운영되는 대량의 테이블의 인덱스를 생성하면 시스템이 엄청나게 느려져 심각한 상황이 발생될 수도 있으니 주의해야 한다. (최신의 MySQL 버전에서는 이전 버전에 비해 인덱스 생성 속도가 향상되기는 했지만, 그래도 데이터의 양에 따라서 몇 시간이나 그 이상의 시간이 걸릴 수도 있다.)
