인덱스의 내부 작동
인덱스의 내부적인 작동을 이해하기 위해서는 우선 몇 가지 개념의 정립이 필요하다.
B-Tree(Balanced Tree, 균형 트리)
B-Tree는 '자료 구조'에 나오는 범용적으로 사용되는 데이터의 구조다. 이 구조는 주로 인덱스를 표현할 때와 그 외에서도 많이 사용된다. 이름에서도 알 수 있듯이 B-Tree는 균형이 잡힌 트리다.
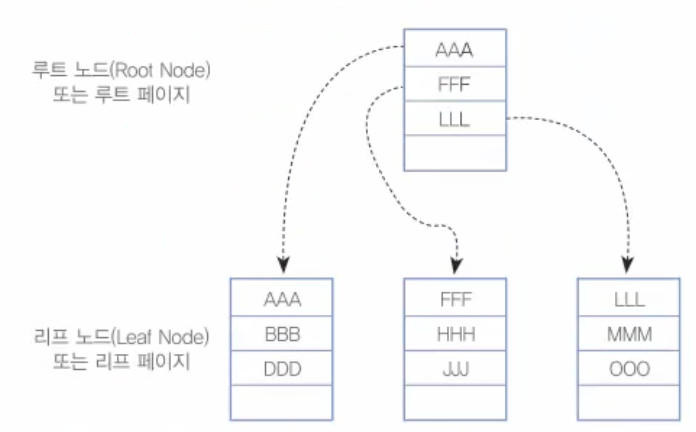
B-Tree의 기본 구조이다.
노드(Node)란 트리 구조에서 데이터가 존재하는 공간을 말한다. 즉, 갈라지는 부분의 '마디'를 뜻한다. 그림에서는 노드가 4개가 있다. 루트 노드(Root Node)란 노드의 가장 상위 노드를 말한다. 모든 출발은 이 루트 노드에서 시작된다. 리프 노드(Leaf Node, 잎 노드, 말단 노드)는 제일 마지막에 존재하는 노드를 말한다. 그리고 그림에서는 두 단계의 레벨이 표현되었지만, 데이터가 많다면 세 단계나 그 이상으로 레벨이 깊어진다. 루트 노드와 리프 노드의 중간에 끼인 노드들은 그냥 '중간 수준 노드'라 부르겠다.
노드(Node)는 개념적인 설명에서 주로 나오는 용어이며, MySQL이 B-Tree를 사용할 때는 이 노드에 해당되는 것이 페이지(Page)다. 페이지란 16Kbyte(=16384 Byte) 크기의 최소한의 저장 단위다. 아무리 작은 데이터를 한 개만 저장하더라도 한 개 페이지(16 Kbyte)를 차지하게 된다는 의미다. 즉, 개념적으로 부를 때는 노드라 부르지만, MySQL에서는 노드가 페이지가 되며 인덱스를 구현할 때 기본적으로 B-Tree 구조를 사용한다.
*그림의 예에서는 페이지당 데이터가 4개만 들어간다고 가정하고 그림을 표현했다. 참고로 MySQL은 기본적으로 한 개 페이지가 16Kbyte이지만, 다른 DBMS에서는 8Kbyte나 다른 크기도 많이 사용한다.
지금은 레벨이 2단계뿐이어서 그 효용성이 별로 크게 못 느껴질 수 있지만, 훨씬 많은 양의 데이터(깊은 레벨)의 경우에는 그 차이가 기하급수적으로 난다.
페이지 분할
앞에서 데이터를 검색하는 데는 B-Tree가 효율적임을 확인했다. 이 말은 인덱스를 구성하면 SELECT의 속도가 급격히 향상될 수 있다는 것을 뜻한다.
*필자가 '향상된다'가 아닌 '향상될 수 있다'라고 표현한 이유는 인덱스가 항상 좋은 것은 아니기 때문이다.
그런데, 인덱스를 구성하면 데이터의 변경 작업(INSERT, UPDATE, DELETE) 시에 성능이 나빠지는 단점이 있다고 했다. 특히, INSERT 작업이 일어날 때 성능이 급격히 느려질 수 있다. 그 이유는 '페이지 분할'이라는 작업이 발생되기 때문이다. 이 작업이 일어나면 MySQL이 느려지고 자주 일어나면 성능에 큰 영향을 주게 된다.
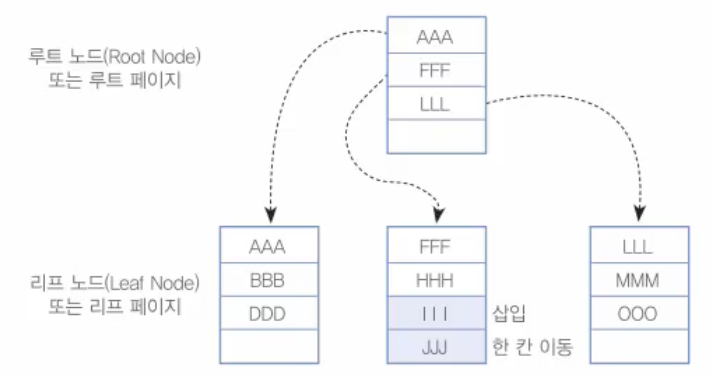
III 삽입 후
두 번째 리프 페이지에는 다행히(?) 한 칸의 빈 공간이 있어서 JJJ가 아래로 한 칸 이동되고 III가 그 자리에 삽입되었다. 정렬이 되어야 하기 때문에 JJJ가 한 칸 이동했을 뿐 별로 큰 작업은 일어나지 않았다.
이번에는 GGG를 입력해 보자. 그런데 더 이상 두 번째 리프 페이지에는 빈 공간이 없다. 이럴 때 드디어 '페이지 분할'작업이 일어난다. MySQL은 우선 비어있는 페이지를 한 개 확보한 후에, 두 번째 리프 페이지의 데이터를 공평하게 나누게 된다.
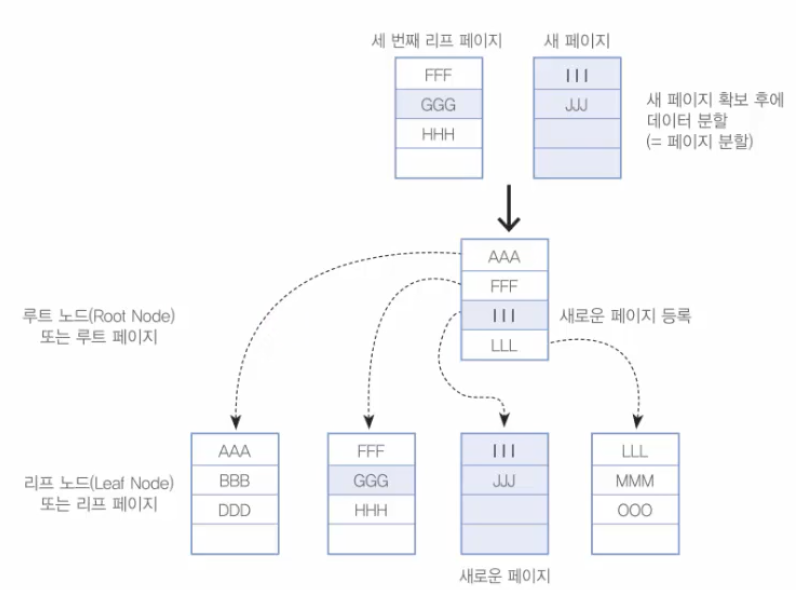
GGG 삽입 후
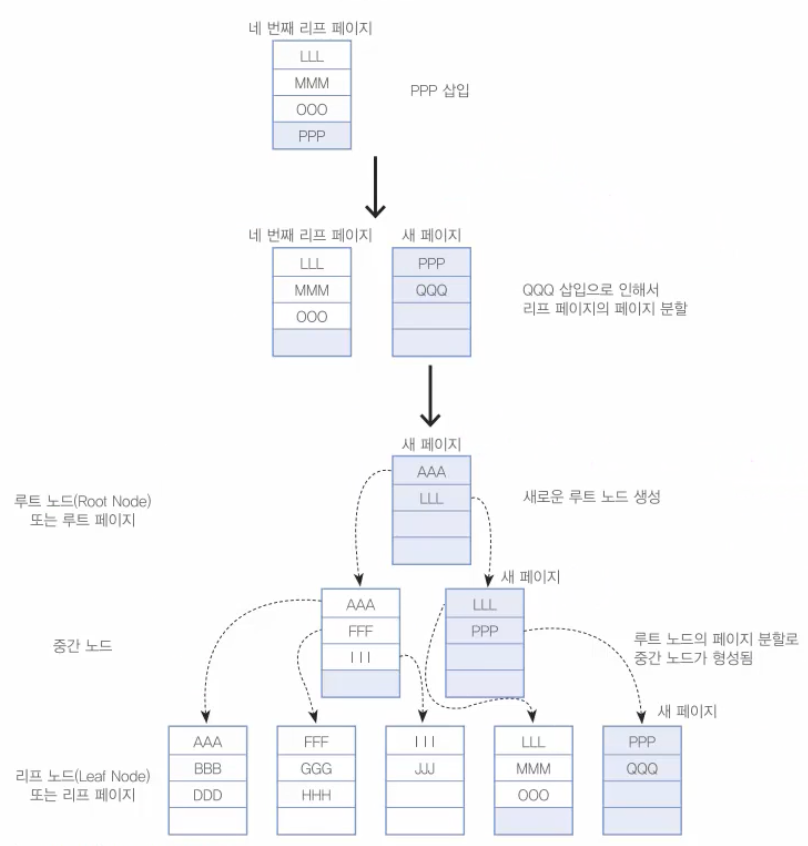
PPP, QQQ 삽입 후
결국, QQQ 하나를 입력하기 위해서 3개의 새로운 페이지가 할당되고 2회의 페이지 분할이 발생되었다.
이 예로써 인덱스를 구성하면 왜 데이터 변경(INSERT, UPDATE, DELETE) 작업이 느려지는지 (특히, INSERT) 확인할 수 있었다.
클러스터형 인덱스와 보조 인덱스의 구조
이번에는 클러스터형 인덱스와 보조 인덱스의 구조는 어떻게 다른지 파악해 보자.
우선 인덱스가 없이 테이블을 생성하고, 다음과 같이 데이터를 입력한 경우를 생각해 보자.

만약, 페이지당 4개의 행이 입력된다고 가정하면 이 데이터는 다음과 같이 구성되어 있을 것이다.
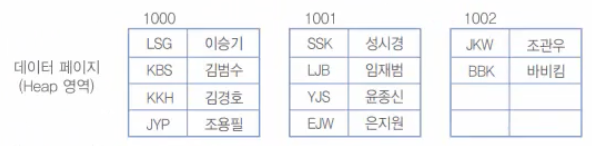
인덱스 없는 테이블의 내부 구성
- 위 그림은 필자가 이해를 돕기 위해 가정한 것이다. MySQL의 기본 페이지의 크기는 16KB(16384Byte)이므로 훨씬 많은 행 데이터가 들어간다. 참고로 MySQL의 페이지 크기는 SHOW VARIABLES LIKE 'innodb_page_size'; 문으로 확인할 수 있다. 필요하다면 4KB(=4096Byte), 8KB(=8192Byte),16KB(=16384Byte),32KB(=32768Byte),64KB(=65536Byte)로 변경할 수 있다.
정렬된 순서만 확인해 보자. 입력된 것과 동일한 순서로 보일 것이다.
SELECT * FROM clustertbl;
이 테이블의 userID에 클러스터형 인덱스를 구성해 보자. 인덱스를 생성하는 구문에 대해서는 잠시 후에 살펴보고 userID를 Primary Key로 지정하면 클러스터형 인덱스로 구성된다고 앞에서 설명했었다.
ALTER TABLE clustertbl
ADD CONSTRAINT PK_clustertbl_userID
PRIMARY KEY (userID);데이터를 다시 확인하자.
SELECT * FROM clustertbl;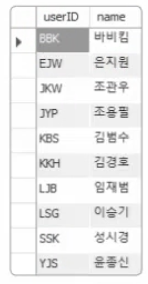
userID로 오름차순 정렬이 되었다. Primary Key로 지정했으니 클러스터형 인덱스가 생성되어서 그렇다. 실제 데이터는 다음 그림과 같이 데이터 페이지가 정렬되고 B-Tree 형태의 인덱스가 형성된다.
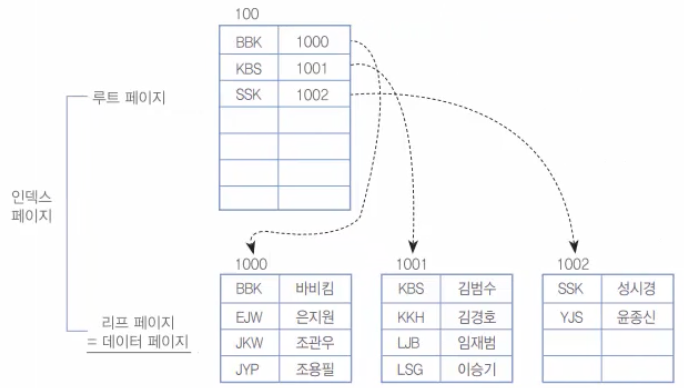
클러스터형 인덱스의 구성 후
클러스터형 인덱스를 구성하기 위해서 행 데이터를 해당 열로 정렬한 후에 루트 페이지를 만들게 된다. 그런데, 필자가 클러스터형 인덱스는 영어사전과 같다고 얘기했었다. 영어사전은 책 자체가 알파벳 순서의 찾아보기(인덱스)로 구성되어 있기 때문에 찾아보기의 끝(리프 레벨)이 바로 영어 단어 데이터 그 자체라는 것을 확인할 수 있다.
클러스터형 인덱스는 데이터의 검색 속도가 보조 인덱스보다 더 빠르다. 일부 예외 상황도 있지만, 그냥 클러스터형이 더 빠르다고 생각해도 무리가 없다. 검색의 비교는 잠시 후에 해보겠다.
이번에는 동일하게 보조 인덱스를 만들어 보도록 하자.
이렇게하면 아까랑 인덱스 없는 테이블의 동일한 구조가 우선 형성된다.
앞에서 Unique 제약 조건은 보조 인덱스를 생성하는 것을 확인했었다. userID열에 Unique제약 조건을 지정한다.
ALTER TABLE secondarytbl
ADD CONSTRAINT UK_secondarytbl_userID
UNIQUE (userID);데이터의 순서만 우선 확인해 보자.
입력한 것과 순서의 변화가 없다. 내부적으로는 다음과 같이 구성되어 있을 것이다.
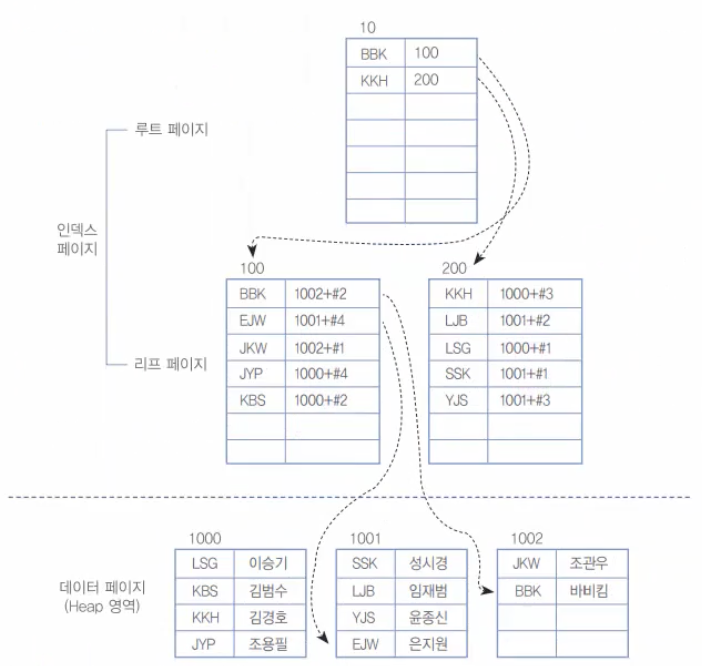
보조 인덱스의 구성 후(데이터 영역을 정렬하지 않고 그대로 둔 상태에서 각각의 데이터만 올려서 새로운 인덱스를 별도로 만든다.)
