인덱스 생성/변경/삭제
이제는 제약 조건에서 자동으로 생성되는 인덱스 외에 직접 인덱스를 생성하는 구문을 살펴보자.
- CREATE INDEX문으로는 Primary Key로 생성되는 클러스터형 인덱스를 만들 수는 없다. 만약, 클러스터형 인덱스를 생성하려면 앞에서 했던 것처럼 ALTER TABLE문을 사용해야 한다. 참고로 CREATE INDEX를 사용하지 않고 ALTER TABLE문으로도 인덱스를 생성/수정/삭제할 수 있다.
인덱스 생성
MySQL 도움말에 나오는 인덱스를 생성하는 문법은 다음과 같다.
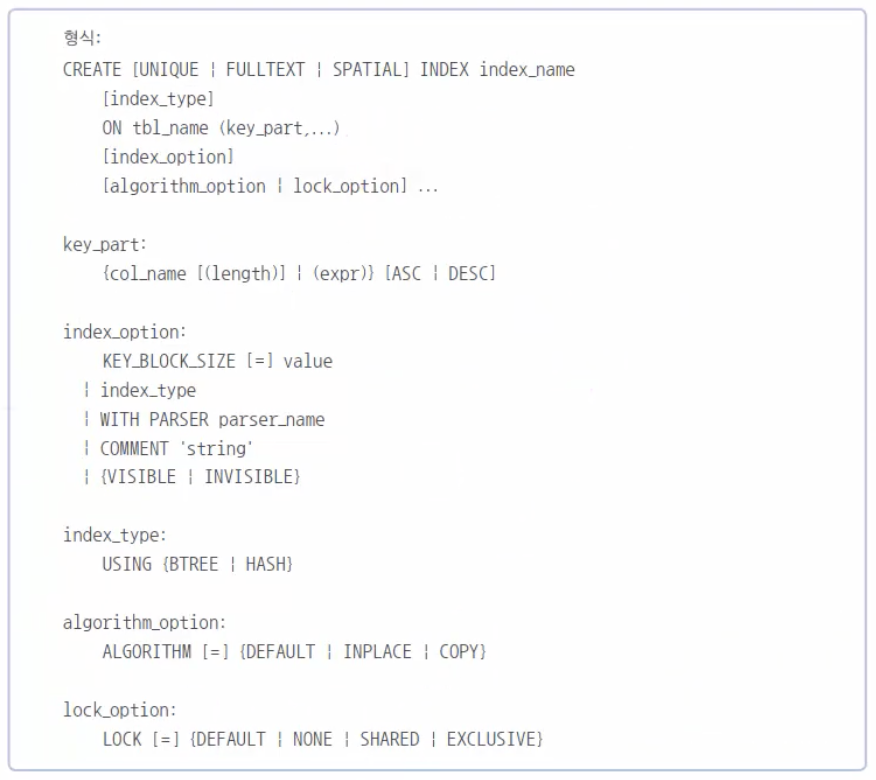
- CREATE FULLTEXT INDEX문은 전체 텍스트 인덱스를 만드는데, chapter 11에서 다루겠다. CREATE SPATIAL INDEX문은 점, 선, 면 등의 공간 데이터와 관련된 인덱스를 생성한다. 공간 데이터에 관해서는 chapter 14에서 다룬다.
UNIQUE 옵션은 고유한 인덱스를 만들 것인지를 결정한다. 즉, UNIQUE로 지정된 인덱스는 동일한 데이터 값이 입력될 수 없다. 디폴트는 UNIQUE가 생략된(=중복이 허용되는) 인덱스다.
또한, CREATE INDEX로 생성되는 인덱스는 보조 인덱스가 생성된다. 그 외에 ASC 및 DESC는 정렬되는 방식이다. ASC가 기본 값이며 오름차순으로 정렬되어서 인덱스가 생성된다. index_type을 생략하면 기본 값은 B-TREE 형식을 사용한다. 그 외의 옵션은 자주 사용되지 않으므로 필요한 경우에 설명하겠다.
인덱스 제거
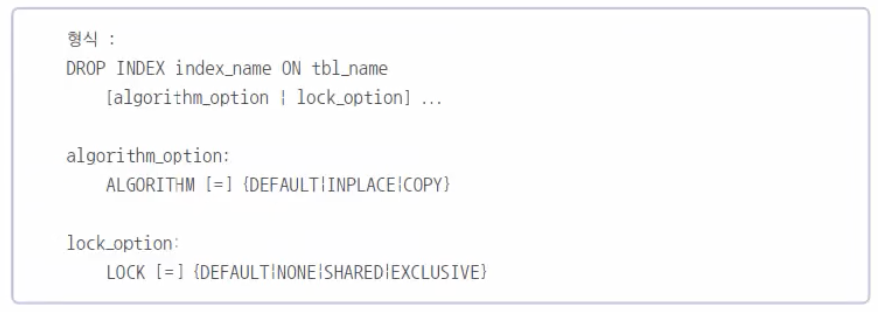
간단하게 인덱스를 삭제하는 구문은 다음과 같이 사용한다.
DROP INDEX 인덱스이름 ON 테이블이름;-
기본 키로 설정된 클러스터형 인덱스의 이름은 항상 'PRIMARY'로 되어 있으므로 인덱스이름 부분에 PRIMARY로 써주면 된다. 또한, ALTER TABLE문으로 기본 키를 제거해도 클러스터형 인덱스가 제거된다.
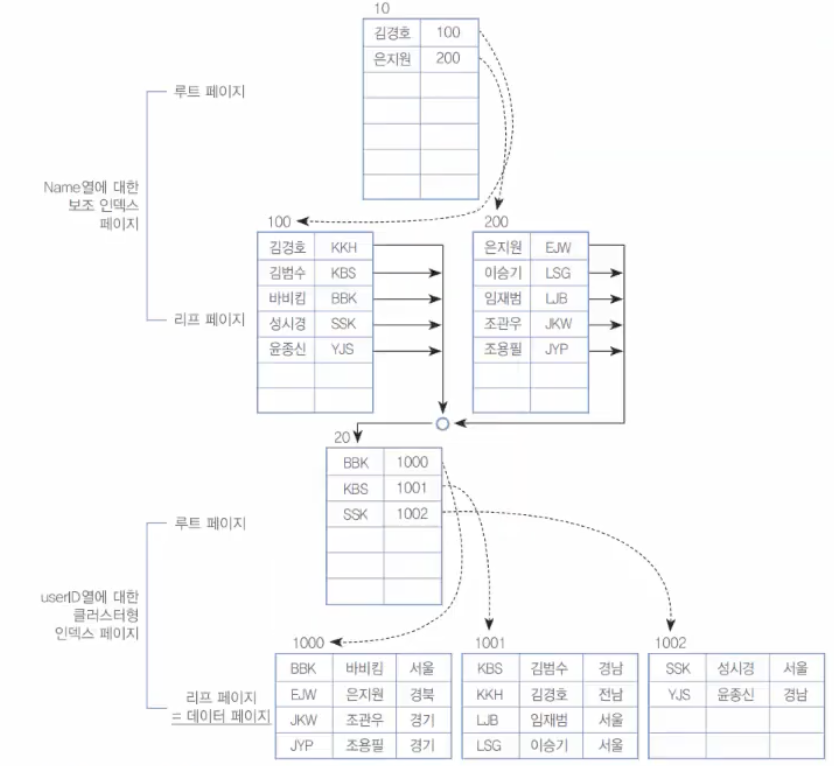
[그림 9-25] 혼합된 인덱스의 내부 구성 -
인덱스를 모두 제거할 때는 되도록 보조 인덱스부터 삭제하도록 한다. [그림 9-25]의 혼합된 인덱스를 보면 만약 아래쪽의 클러스터형 인덱스를 먼저 삭제하면 클러스터형 인덱스의 루트 페이지가 없어진다. 보조 인덱스의 리프 페이지는 모두 루트 페이지를 지정하고 있으므로, 어쩔 수 없이 원래의 보조 인덱스의 리프 페이지에는 '페이지 번호 + #오프셋'으로 재구성되어야 한다. 그런데, 이 재구성 후에 보조 인덱스도 삭제한다면 고생해서 재구성한 것을 또 삭제하는 결과가 된다.
만약 [그림 9-25]의 위쪽 보조 인덱스를 먼저 삭제하면 클러스터형 인덱스는 전혀 변화가 없다. 그러므로, 모든 인덱스 삭제 시에는 보조 인덱스를 먼저 제거하도록 한다. -
인덱스를 많이 생성해 놓은 테이블은 인덱스의 용도를 잘 확인한 후에, 인덱스의 활용도가 떨어진다면 과감히 삭제해 줄 필요가 있다. 그렇지 않으면 전반적인 MySQL의 성능이 저하되는 문제를 야기할 수 있다. 한 달에 한 번 또는 일년에 한 번 사용될 인덱스를 계속 유지할 필요는 없다.
<실습>
인덱스를 생성하고 사용하는 실습을 해보자.
Workbench를 종료하고 새로 실행한 후, 저장해 놓은 sqlDB.sql을 이용해서 sqlDB 데이터베이스를 초기화 시키자.
usertbl을 주로 사용해 보도록 하자.
USE sqldb;
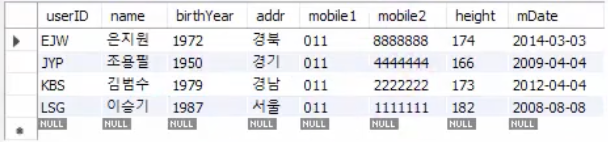
SELECT * FROM usertbl;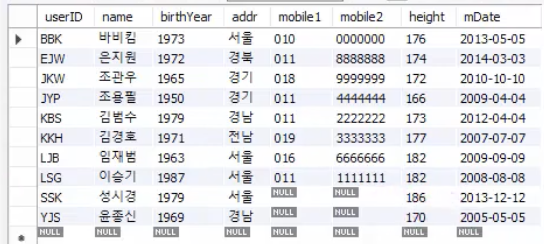
USE sqldb;
SHOW INDEX FROM usertbl;
SHOW TABLE STATUS LIKE 'usertbl'; -- 인덱스의 크기
CREATE INDEX idx_usertbl_addr
ON usertbl (addr); -- 보조인덱스이고 unique를 안써서 중복이 허용되는 인덱스SHOW INDEX FROM usertbl;
Non_unique가 1이라고 적혀있다. 중복을 허용한다는 의미이다.
SHOW TABLE STATUS LIKE 'usertbl';
아직도 Index_length가 0으로 나옴. 아직 적용이 안됐기 때문이다.
ANALYZE TABLE usertbl; -- 적용을 시켜야함.
SHOW TABLE STATUS LIKE 'usertbl';
Index_length가 늘어난 것을 확인할 수 있다.
CREATE UNIQUE INDEX idx_usertbl_birthYear
ON usertbl (birthYear);안만들어짐. birthYear가 같은 사람이 들어있기 때문이다.
CREATE UNIQUE INDEX idx_usertbl_name
ON usertbl (name);SHOW INDEX FROM usertbl;
Non_unique가 0 이므로 중복이 안되는 name 인덱스가 만들어졌다.
INSERT INTO usertbl VALUES('GPS', '김범수', 1983, '미국', NULL, NULL, 162, NULL);오류가 발생. 이미 unique인덱스가 만들어졌기 때문에 같은 이름이 입력이 안되는 것이다. 이것이 바로 주의할 점이다. 현재 이름이 중복이 안됐기 때문에 unique index가 만들어지긴 하지만, 현재가 중복이 안된다고 해서 앞으로도 중복된 데이터가 없으리라는 보장은 못함. 즉 unique index를 만들때는 현재뿐만 아니라 앞으로도 절대로 중복이 안될건지를 파악한 다음 unique index를 만들어야 한다.
CREATE INDEX idx_usertbl_name_birthYear
ON usertbl (name,birthYear);
DROP INDEX idx_usertbl_name ON usertbl;SHOW INDEX FROM usertbl;
SELECT * FROM usertbl WHERE name = '윤종신' and birthYear = '1969';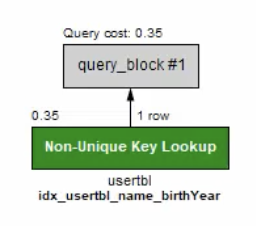
결과가 중요한 것이 아니라 인덱스를 잘 썼는지 확인해보겠음.
오른쪽 밑에 Execution Plan 클릭하면 인덱스 썼는지 안썼는지 나온다.
Key Lookup은 인덱스를 사용했다는 의미임.
CREATE INDEX idx_usertbl_mobile1
ON usertbl (mobile1);SELECT * FROM usertbl WHERE mobile1 = '011';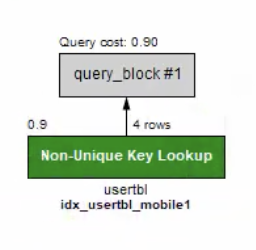

Exeuction Plan을 보면 인덱스를 잘 사용하고 있음을 볼 수 있다.
SHOW INDEX FROM usertbl;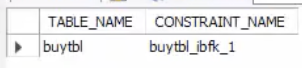
보조 인덱스부터 삭제하는 것이 좋음.
DROP INDEX idx_usertbl_addr ON usertbl;
DROP INDEX idx_usertbl_name_birthYear ON usertbl;
DROP INDEX idx_usertbl_mobile1 ON usertbl;
또는
ALTER TABLE usertbl DROP INDEX idx_usertbl_addr;
ALTER TABLE usertbl DROP INDEX idx_usertbl_name_birthYear;
ALTER TABLE usertbl DROP INDEX idx_usertbl_mobile1;ALTER TABLE usertbl DROP PRIMARY KEY;오류가 발생. PK, FK로 연결되어 있기 때문. 클러스터형 인덱스를 삭제하고 싶다면 먼저 FK연결을 끊은다음에 삭제를 하면 된다.
SELECT table_name, constraint_name
FROM information_schema.referential_constraints
WHERE constraint_schema = 'sqldb';sqldb가 지금 어떻게 되어있는지 확인하는 쿼리문임.
buytbl_ibfk_1이 바로 FK임.
ALTER TABLE buyTbl1 DROP FOREIGN KEY buytbl_ibfk_1;
ALTER TABLE usertbl DROP PRIMARY KEY;인덱스의 성능 비교
인덱스를 생성하고 삭제하는 방법에 대해서 익혔으니 이번에는 클러스터형 인덱스와 보조 인덱스와 인덱스가 없을 때의 성능 차이를 직접 확인하는 실습을 해보자.
이번 실습을 통해서 어떤 인덱스가 성능이 좋은지 또, 인덱스가 있어도 인덱스를 사용하지 않는 것은 어떤 경우인지를 파악해 보자.
<실습>
인덱스가 없을 때, 클러스터형 인덱스만 있을 때, 보조 인덱스만 있을 때의 성능을 비교하자. 또한 각 인덱스의 특성과 장단점도 함께 이해해 보자.
실습할 데이터베이스를 만든다.
CREATE DATABASE IF NOT EXISTS indexdb;----나중에 하겠음----
결론: 인덱스를 생성해야 하는 경우와 그렇지 않은 경우
이제는 인덱스에 대한 결론을 확인하자. 인덱스는 잘 사용할 경우에는 쿼리의 성능이 급격히 향상되지만 그렇지 않을 경우에는 오히려 쿼리의 성능이 떨어지며 전반적인 MySQL의 성능이 나빠질 수도 있다.
그럴 수밖에 없는 것이 인덱스를 만드는 절대 기준이 있는 것이 아니라 '테이블의 데이터 구성이 어떻게 되었는지, 어떠한 조회를 많이 사용하는지' 등에 따라서 인덱스를 생성해야 하기 때문이다. 다음의 사항들은 이미 여러 번 나왔지만 잘 기억해 두는 것이 좋다.
-
인덱스는 열 단위에 생성된다.
(하나의 열에만 생성되는 것이 아니라 두 개 이상의 열을 조합해서 인덱스를 생성할 수 있었다.) -
WHERE절에서 사용되는 열에 인덱스를 만들어야 한다.
(테이블 조회 시에 인덱스를 사용하는 경우는 WHERE절의 조건에 해당 열이 나오는 경우에만 주로 사용된다.)
sqlDB의 usertbl을 생각해 보자.
SELECT name, birthYear, addr FROM usertbl WHERE userID = 'KKH';위에서 name,birthYear,addr열에는 인덱스를 생성해 보았자 전혀 사용할 일이 없다. WHERE절에 있는 userID열에만 인덱스를 생성할 필요가 있다.
- WHERE절에 사용되더라도 자주 사용해야 가치가 있다.
만약, 위의 쿼리에서 userID열에 인덱스를 생성해서 효율이 아주 좋아진다고 하더라도, 위 SELECT문은 아주 가끔만 사용되고, usertbl 테이블에는 주로 INSERT 작업만이 일어난다면? 특히, 이 경우에 userID열에 생성된 인덱스가 클러스터형 인덱스라면?
오히려 인덱스로 인해서 데이터를 입력하는 성능이 무척 나빠질 것이다.
[그림 9-20]의 클러스터형 인덱스에서 데이터가 입력되는 과정이 매번 일어나서 페이지 분할 작업이 계속 일어나게 된다. [그림 9-21]의 보조 인덱스도 데이터 페이지의 분할은 클러스터형 인덱스에 비해서 덜 일어나지만 인덱스 페이지의 페이지 분할은 종종 발생하게 될 것이다.
- 이미 usertbl에 대용량 데이터가 운영되고 있는 상태라고 가정하자. 그렇다면 이미 userID열은 Primary Key로 지정해 놓았으므로 자동으로 클러스터형 인덱스가 생성되어 있을 것이다. 이미 설정되어 있는 Primary Key를 제거하는 것도 다른 여러 쿼리문 등과의 연관성 등을 신중하게 고려해야 한다.
-
데이터의 중복도가 높은 열은 인덱스를 만들어도 별 효과가 없다.
(성별같은 경우 인덱스가 없는 편이 낫다.) -
외래 키를 지정한 열에는 자동으로 외래 키 인덱스가 생성된다.
-
JOIN에 자주 사용되는 열에는 인덱스를 생성해 주는 것이 좋다.
-
INSERT/UPDATE/DELETE가 얼마나 자주 일어나는지를 고려해야 한다.
-
클러스터형 인덱스는 테이블당 하나만 생성할 수 있다.
(클러스터형 인덱스를 생성할 열은 범위(BETWEEN,>,< 등의 조건)로 사용하거나 집계 함수를 사용하는 경우에는 아주 적절하다. 클러스터형 인덱스는 데이터 페이지를 읽는 수가 최소화 되어서 성능이 아주 우수하므로 조건에서 가장 많이 사용되는 열에 생성하는 것이 바람직하다. 또한, ORDER BY절에 자주 나오는 열도 클러스터형 인덱스가 유리하다. 클러스터형 인덱스의 데이터 페이지(=리프 페이지)는 이미 정렬이 되어 있기 때문이다. -
클러스터형 인덱스가 테이블에 아예 없는 것이 좋은 경우도 있다.

이 상태에서 대용량의 데이터가 계속 입력되는 시스템이라고 가정할 때, 무작위로 'PBB', 'BJJ', 'KMM'등의 순서와 userID의 순서와 관계없이 입력될 것이다. 클러스터형 인덱스로 구성되었으므로 데이터가 입력되는 즉시 정렬이 계속 수행되고 페이지 분할이 끊임없이 일어나게 될 수도 있어서, 시스템의 성능에 문제가 생긴다. -
사용하지 않는 인덱스는 제거하자.
이로써 인덱스의 내용을 살펴보았다. 다시 한번 얘기하지만 인덱스는 MySQL의 성능에 아주 큰 영향을 미치게 되므로 잘 작성하고 활용해야 한다. 특히, 데이터베이스 모델링 시점에서 인덱스에 대한 결정을 잘 내려야만 실제로 운영되는 경우에 MySQL이 원활히 운영될 수 있을 것이다.
또한, 인덱스는 한번 생성했다고 내버려 두는 것이 아니라 잘 활용되는지를 살펴서 활용이 되지 않는 인덱스라면 과감히 제거하고 주기적인 OPTIMIZE TABLE 구문이나 ANALYZE TABLE 구문으로 인덱스 재구성을 통해서 조각화를 최소화해야만 시스템의 성능을 최상으로 유지시킬 수 있을 것이다.
