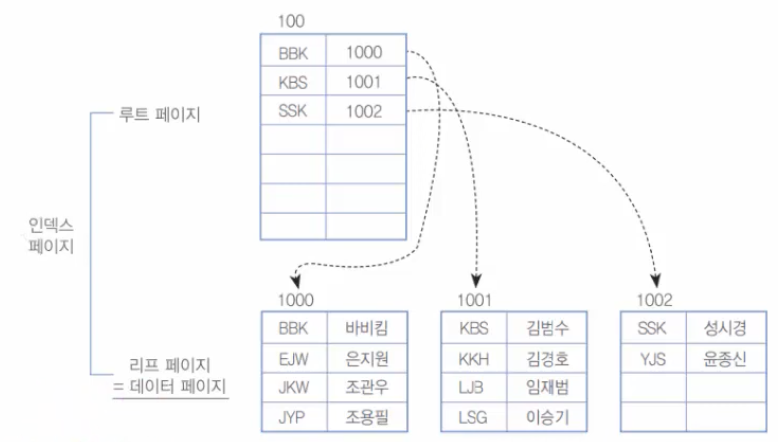
[그림 9-17] 클러스터형 인덱스의 구성 후
우선 클러스터형 인덱스에서 검색해 보자. 만약 JKW(조관우)를 검색한다면 단순히 몇 개 페이지를 읽을 것인가? 루트 페이지(100번)와 리프 페이지(=데이터 페이지, 1000번) 한 개씩만 검색하면 된다. 총 2개 페이지를 읽게 된다.
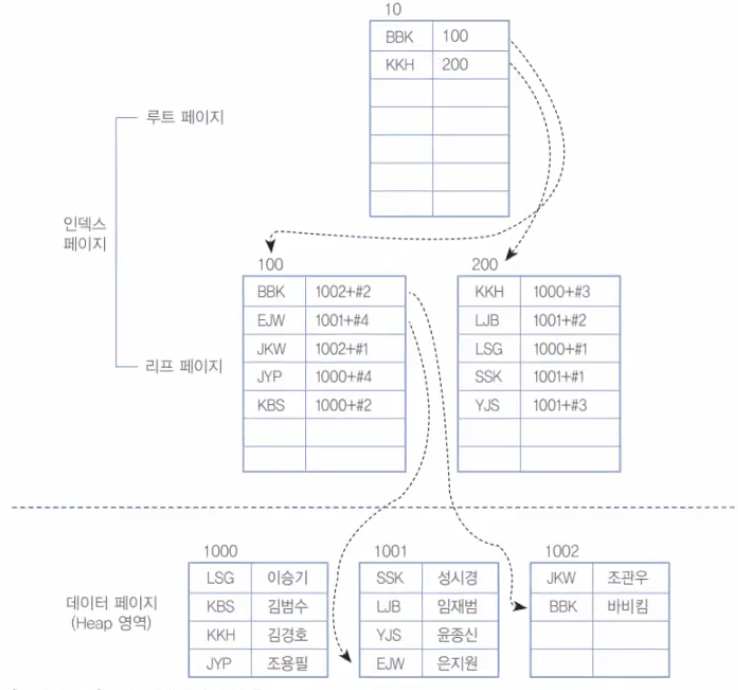
[그림 9-19] 보조 인덱스의 구성 후
이번에는 보조 인덱스에서 검색해 보자. JKW를 검색 시에 인덱스 페이지의 루트 페이지(10번), 리프 페이지(100번) 그리고 데이터 페이지(1002번)를 읽게 되어 총 3개 페이지를 읽게 된다.
지금은 한 페이지 차이밖에 나지 않는 것처럼 보일 수도 있으나 범위로 검색하는 것을 한번 고려하자. userID가 'A'~'J'인 사용자를 모두 검색하는 것을 가정하자.
먼저 [그림 9-17]의 클러스터형 인덱스의 경우에는 루트 페이지(100번)와 1000번 페이지 2개 페이지만 읽으면 원하는 데이터가 모두 들어 있다. 어차피 리프 페이지는 정렬되어 있고 이 리프 페이지가 곧 데이터 페이지이므로, 클러스터형 인덱스는 범위로 검색 시에 아주 우수한 성능을 보인다.
다음으로 [그림 9-19]의 보조 인덱스에서 생각해 보자. 우선 루트 페이지와 리프 페이지 중 100번 페이지를 읽으면 된다. 그런데, 데이터를 검색하려 하니 범위에 해당하는 BBK, EJW, JKW, JYP 중에서 BBK와 EJW와 JYP가 서로 다른 페이지에 존재한다. 그러므로 BBK, JKW를 위해 1002페이지를, EJW를 위해 1001페이지를, JYP를 위해 1000페이지를 읽어야 한다. 결과적으로 'A'~'J'인 사용자를 모두 검색하기 위해서 보조 인덱스는 10번, 100번, 1000번, 1001번, 1002번 페이지를 읽어 총 5개 페이지를 읽었다.
이 예에서와 같이 결론적으로 클러스터형 인덱스가 보조 인덱스보다 검색이 더 빠르다고 보면 된다.
[그림 9-17] 클러스터형 인덱스의 구성 후
이번에는 [그림 9-17]의 클러스터 인덱스에 새로운 데이터의 입력을 생각해 보자.
INSERT INTO clustertbl VALUES('FNT', '푸니타');
INSERT INTO clustertbl VALUES('KAI', '카아이');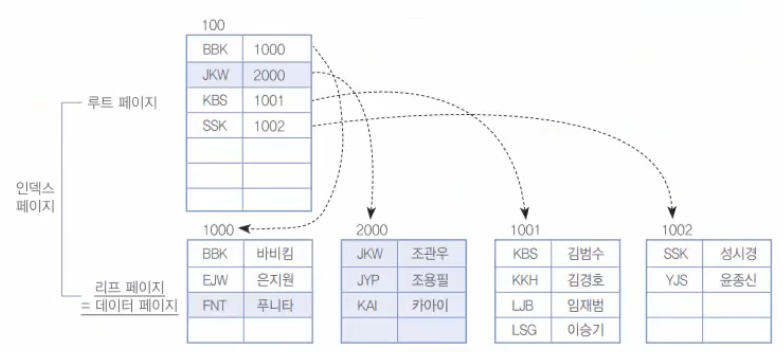
[그림 9-20] 클러스터형 인덱스에 두 행의 추가 후
[그림 9-20]을 보면 예상대로 첫 번째 리프 페이지(=데이터 페이지)가 페이지 분할이 일어났다. 그리고 데이터를 공평하게 분배한 후에, 루트 페이지에 등록되었다. 물론, 루트 페이지의 순서가 약간 변경되기는 했지만, 페이지 분할에 비해서 같은 페이지 내에서의 순서 변경은 시스템에 미치는 영향이 미미하다. (전에 얘기했듯이 페이지 분할은 시스템에 많은 부하를 준다.)
[그림 9-19] 보조 인덱스의 구성 후
이번에는 [그림 9-19]의 보조 인덱스에 동일한 입력을 생각해 보자.
INSERT INTO clustertbl VALUES('FNT', '푸니타');
INSERT INTO clustertbl VALUES('KAI', '카아이');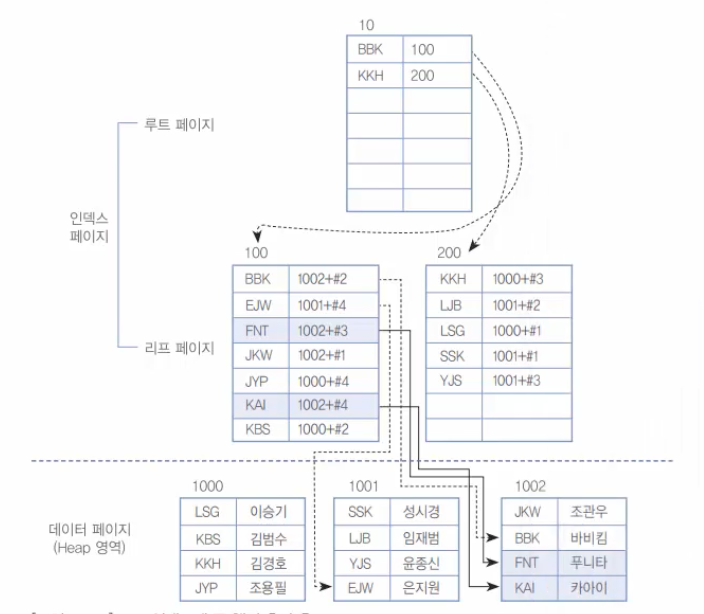
[그림 9-21] 보조 인덱스에 두 행의 추가 후
[그림 9-21]을 보면 보조 인덱스는 데이터 페이지를 정렬하는 것이 아니므로, 그냥 데이터 페이지의 뒤쪽 빈 부분에 삽입된다. 그리고 인덱스의 리프 페이지에도 약간의 위치가 조정된 것일뿐 페이지 분할은 일어나지 않았다. 결국, 클러스터형 인덱스보다 데이터 입력에서는 성능에 주는 부하가 더 적었다.
*지금 필자는 설명을 위해서 데이터의 양을 조금 억지로 맞춘 경향이 있다. 하지만, 실제로 대용량의 테이블일 경우에 INSERT 작업이 대개는 클러스터형 인덱스가 더 시스템 부하가 많이 생긴다.
클러스터형 인덱스의 특징
-
클러스터형 인덱스의 생성 시에는 데이터 페이지 전체가 다시 정렬된다. 그러므로 이미 대용량의 데이터가 입력된 상태라면 업무시간에 클러스터형 인덱스를 생성하는 것은 심각한 시스템 부하를 줄 수 있으므로 신중하게 생각해야 한다.
-
클러스터형 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터이다. 그러므로, 인덱스 자체에 데이터가 포함되어 있다고 볼 수 있다.
-
클러스터형 인덱스는 보조 인덱스보다 검색 속도는 더 빠르다. 하지만, 데이터의 입력/수정/삭제는 더 느리다.
-
클러스터 인덱스는 성능이 좋지만 테이블에 한 개만 생성할 수 있다. 그러므로 어느 열에 클러스터형 인덱스를 생성하는지에 따라서 시스템의 성능이 달라질 수 있다.
보조 인덱스의 특징
-
보조 인덱스의 생성 시에는 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
-
보조 인덱스는 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 주소값(RID)이다. 클러스터형보다 검색 속도는 더 느리지만, 데이터의 입력/수정/삭제는 덜 느리다.
-
보조 인덱스는 여러 개 생성할 수 있다. 하지만, 함부로 남용할 경우에는 오히려 시스템 성능을 떨어뜨리는 결과를 초래할 수 있으므로, 꼭 필요한 열에만 생성하는 것이 좋다.
잠시 후에 위 결론 중에서 어떤 열에 클러스터형 인덱스를 생성하고 어떤 열에 보조 인덱스를 생성하는 것이 좋은지를 파악해 보겠다.
- OLTP와 OLAP에 인덱스 생성
OLTP(On-Line Transaction Processing)는 INSERT/UPDATE/DELETE가 실시간으로 자주 발생되므로, 꼭 필요한 인덱스만 최소로 생성하는 것이 바람직하다. 하지만 OLAP(On-Line Analytical Processing)는 INSERT/UPDATE/DELETE가 별로 사용될 일이 없으므로 되도록 인덱스를 많이 만들어도 별 문제가 되지 않는다. 만약, 하나의 DB가 OLAP/OLTP 겸용으로 사용된다면 두 개를 분리하는 방법을 고려하는 것이 전반적인 시스템의 성능에 도움이 될 것이다. 여기서는 대부분 OLTP DB라는 가정하에 내용이 설명되었다.
클러스터형 인덱스와 보조 인덱스가 혼합되어 있을 경우
지금까지는 테이블에 클러스터형 인덱스만 있거나 보조 인덱스만 있는 경우를 살펴보았다. 하지만, 현실적으로 하나의 테이블에 클러스터형 인덱스와 보조 인덱스가 혼합되어 있는 경우가 더 많다.
인덱스가 하나씩만 있는 것보다는 두 형태의 인덱스가 혼합되어서 조금 어렵게 느껴질 것 같다. 그래도 차근차근 보면 그리 어려운 얘기는 아니다. 이번에는 실습을 통해서 이해해 보겠다.
<실습>
하나의 테이블에 클러스터형 인덱스와 보조 인덱스가 모두 존재할 경우를 살펴보자.
이번에는 열이 3개인 테이블을 사용해 보겠다. usertbl열에는 클러스터형 인덱스를, name열에는 보조 인덱스를 생성해 보겠다. 그리고 addr열은 그냥 참조용으로 사용하자.
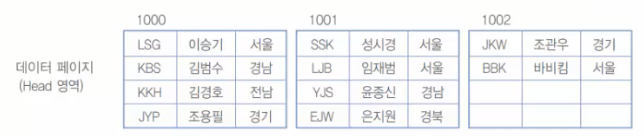
[그림 9-22] 인덱스가 없는 데이터 페이지
ALTER TABLE mixedtbl
ADD CONSTRAINT PK_mixedtbl_userID
PRIMARY KEY (userID);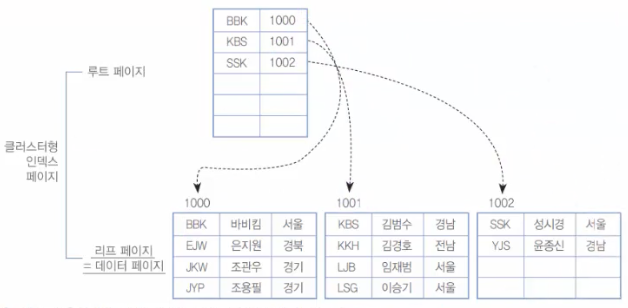
[그림 9-23] 혼합형 인덱스 중에서 클러스터형 인덱스의 구성 후
ALTER TABLE mixedtbl
ADD CONSTRAINT UK_mixedtbl_name
UNIQUE (name);SHOW INDEX FROM mixedtbl;
PRIMARY KEY 클러스터형 인덱스가 userID에 만들어졌고, UK_mixedtbl_name 보조 인덱스가 name에 만들어진 것을 확인할 수 있다.
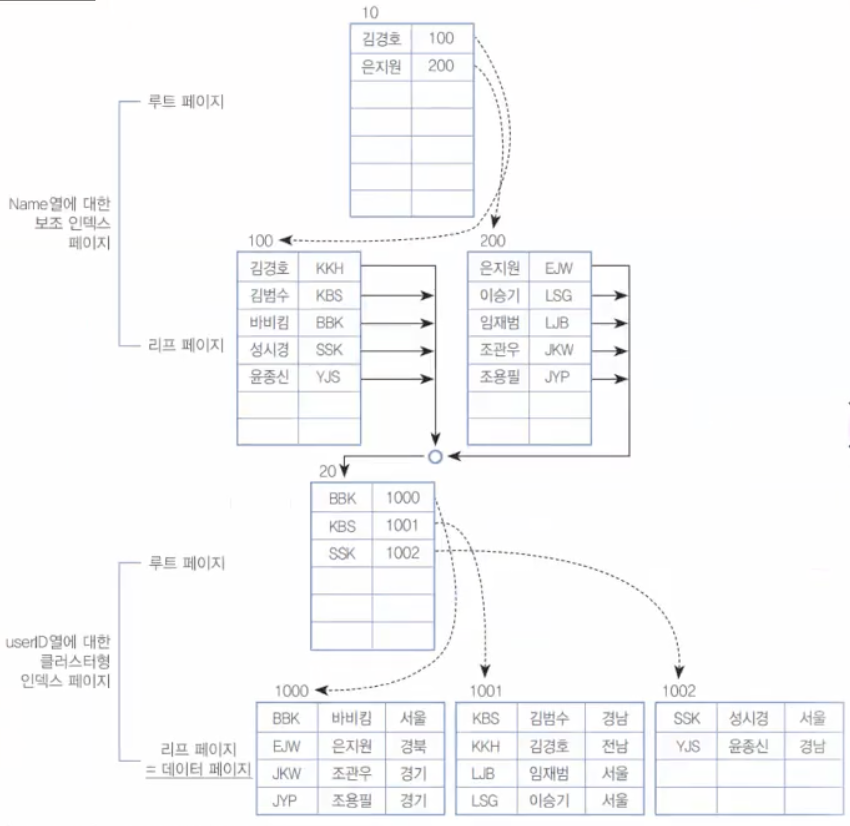
[그림 9-25] 혼합된 인덱스의 내부 구성
SELECT addr FROM mixedtbl WHERE name = '임재범';
검색과정: Name열에 대한 보조 인덱스 페이지의 루트 페이지에 은지원 -> 임재범 -> userID열에 대한 클러스터형 인덱스 페이지의 루트 페이지로 가서 KBS 1001번 -> LJB 서울
총 4페이지를 읽어서 찾게 된다.
만약 LJB에 1001번의 3번째라고 써져있으면 총 3페이지를 읽게 돼서 더 빠른데 이렇게 구성하면 굉장히 위험함.
데이터 검색이 아니라 MMI(멍멍이) 데이터 삽입을 한다면 1001번 리프페이지가 분할이 되고 하나가 올라가짐. 그리고 보조 인덱스의 리프 페이지의 바비킴 전칸에 멍멍이가 추가될 것임. 사실상 페이지분할이 1번만 일어남. 그리고 별로 수정한 것도 없음.
만약 번지로 되어있다면 1001번 리프페이지가 분할이되는데 번지가 쭉 밀림. 데이터를 한 건 입력했는데도 불구하고 번지들을 다 재구성해야함. 그래서 데이터를 입력/수정/삭제 해도 보조 인덱스는 큰 부담이 없게끔 하기 위해서 지금처럼 구성하면 데이터 검색에 있어서는 조금 손해를 보는 것 같지만 입력/수정/삭제 할때도 보조 인덱스는 크게 영향을 받지 않게 된다.
- 혼합 인덱스에서 인덱스 지정 시 고려사항
시스템 성능의 향상을 위해서 조금 더 고려해야 할 사항이 있다.
[그림 9-25]를 보면 클러스터형 인덱스의 키(KKH, KBS 등)를 보조 인덱스가 저장하는 것을 확인할 수 있다. 그러므로 클러스터형 인덱스를 지정할 열(여기서는 userID)의 자릿수가 크다면 보조 인덱스에 저장되어야 할 양도 더불어서 많아진다. 그러면, 차지하는 공간이 자연히 커질 수밖에 없다. 결국 보조 인덱스와 혼합되어 사용되는 경우에는 되도록이면 클러스터형 인덱스로 설정할 열은 적은 자릿수의 열을 선택하는 것이 바람직하다.
인덱스를 검색하기 위한 일차 조건은 WHERE절에 해당 인덱스를 생성한 열의 이름이 나와야 한다. 물론, WHERE절에 해당 인덱스를 생성한 열 이름이 나와도 인덱스를 사용하지 않는 경우도 많다.
