텍스트 마이닝
텍스트 데이터로부터 유용한 인사이트를 발굴하는 Data Mining의 한 종류로 자연어 처리방식(Natural Language Processing)과 문서처리 방법을 적용하여 유용한 정보를 추출/가공하는 것을 목표로 한다.
자연어란?
- 인간이 일상생활에서 사용하는 언어
- 인간이 정보를 전달하는 수단
- 특정 집단에서 사용되는 모국어의 집합(한국어, 영어, 일본어 등)
- 인공 언어와 대비되는 개념
인공언어란?
특정한 법칙들에 따라 적절하게 구성된 문자열들의 집합으로 특정 목적을 위해 인위적으로 만든 언어(프로그래밍 언어, 형식언어)
자연어 처리 응용 분야
인간의 언어가 사용되는 실세계의 모든 영역
- 정보검색, 질의 응답 시스템(Google, Naver, siri, bixby)
- 기계번역, 자동통역(Google 번역기, 네이버 Papago)
- 문서 작성, 문서 요약, 문서 분류, 철자 오류 검색 및 수정
텍스트 마이닝 영역
- 텍스트 분류(Text Classification)
- 감성 분석(Sentiment Analysis)
- 텍스트 요약(Summarization)
- 텍스트 군집화 및 유사도 분석(Clustering)
텍스트 데이터의 구조

- 말뭉치(corpus) : 분석을 위해 수집된 문서들의 집합
- 말뭉치는 여러 개의 문서로 구성
- 문서는 여러 개의 문단으로 구성
- 문단은 여러 개의 문장으로 구성
- 문장은 여러 개의 단어로 구성
- 단어는 여러 개의 형태소로 구성
형태소 : 일정한 의미가 있는 가장 작은 말의 단위
ex) 첫 사랑 : 첫, 사랑
ex) 애늙은이 : 애, 늙은이
머신러닝 프로세스
1. 문제 정의
2. 데이터 수집
3. 데이터 전처리
4. EDA(탐색적 데이터 분석) 기술통계, 상관분석
5. 모델 선택 및 하이퍼 파라미터 선택
6. 모델 학습(fit)
7. 모델 예측(predict) 및 평가(score)
텍스트 마이닝 분석 프로세스

텍스트 전처리
- 전처리는 용도에 맞게 텍스트를 사전에 처리하는 작업
- 오탈자 제거, 띄어쓰기 교정
- 불용어 제거 : 데이터에서 큰 의미가 없는 단어 제거(ex음, 뭐, 아 등)
- 정제(cleaning) : 가지고 있는 corpus(말뭉치)로부터 노이즈 데이터를 제거
- 정규화(normalization) : 표현 방법이 다른 단어들을 통합하여 같은 단어로 만듦(좋다, 지린다)
- 어간 추출(Stemming) 단어의 핵십 부분(어간)만 추출(ex 먹다, 먹고, 먹지, 먹어서 등)
- 표제어 추출(Lemmatization) : 유사한 단어들에서 대표 단어를 추출(am, are, is는 be동사)
토큰화(tokenization)
학습을 위해서 주어진 corpus(말뭉치)에서 토큰이라 불리는 단위로 나누는 작업(공백 기준, 형태소 기준, 명사 기준, 단어 기준 등)
감성 분석을 한다면, 한글에서 감성을 나타내는 품사가 동사, 형용사 쪽에 가깝기 때문에 한글 형태소 분석기를 사용해서 동사, 형용사 위주로 추출
종류
단어(word) 단위 :텍스트를 단어로 나누고 각 단어를 하나의 벡터로 변환
문자(character) 단위 : 텍스트를 문자로 나누고 각 문자를 하나의 벡터로 변환
n-gram 단위 : 텍스트에서 단어나 문자의 n-gram을 추출하여 n-gram을 하나의 벡터로 변환
n-gram
- n개의 연속된 단어를 하나로 취급하는 방법
예를 들어, "러시아 월드컵"이라는 표현을 "러시아"와 "월드컵" 두 개의 독립된 단어로만 취급하지 않고 두 단어로 구성된 하나의 토큰으로 취급 - n = 2경우를 bi-gram이라고도 부름
- 단어의 개수가 늘어난 효과
텍스트 : "어제 러시아에 갔다가 러시아 월드컵을 관람했다."
단어 토큰 : {"어제" , "러시아", "갔다.", "월드컵", "관람"}
2-gram 토큰 : {"어제 러시아", "러시아 갔다", "갔다 월드컵", "월드컵 관람"}특징 값 추출
- 중요한 단어를 선별하는 과정
- 중요한 단어로서 특징은 적은 수의 문서에 분포되어 있어야 하고, 문서 내에서도 빈번하게 출현해야함(TF-IDF)
- 특정 텍스트를 통해 문서를 구분 짓는 것이기 때문에 어떤 단어가 모든 문서에 분포되어 있다면 개수가 많더라도 차별성 없는 일반적인 단어
데이터 분석 수단
Machine learning(Linear Regression, Logistic Regression, Random Forest, XGBoosting)
Deep learning(CNN, RNN, LSTM, GRU)
데이터 분석을 위해 토큰화 결과를 수치로 만드는 방법
머신러닝은 숫자만 가능하기때문에 문자를 숫자로 바꿔주는 작업이 필요하다
- 원 핫 인코딩
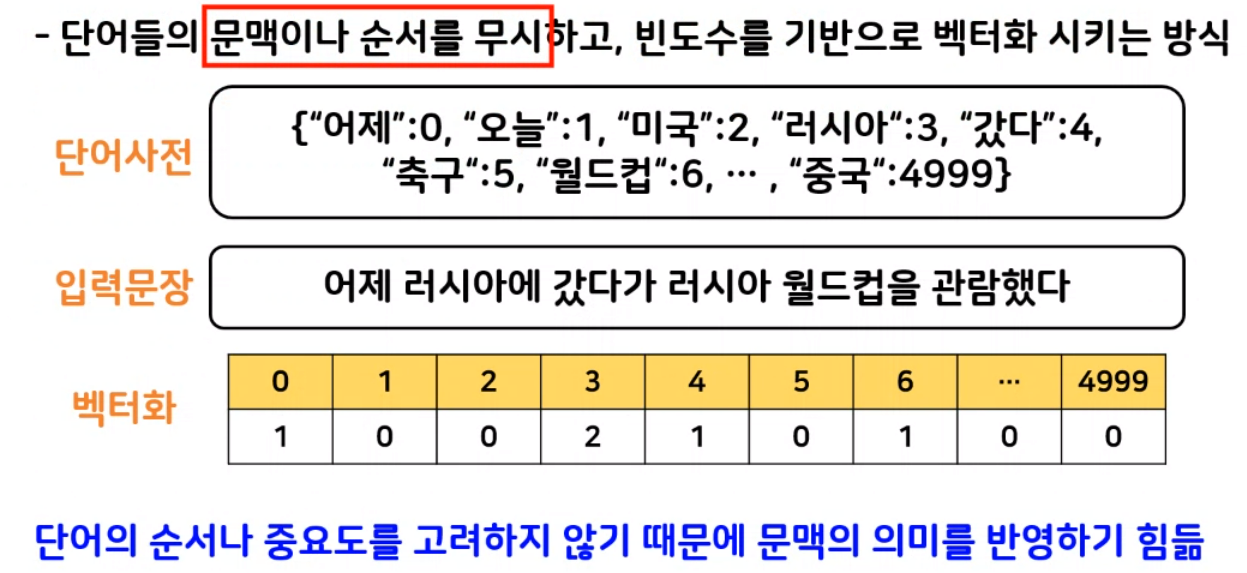
- __BOW(Bag of Words)
- CounterVectorize(단순 카운팅)
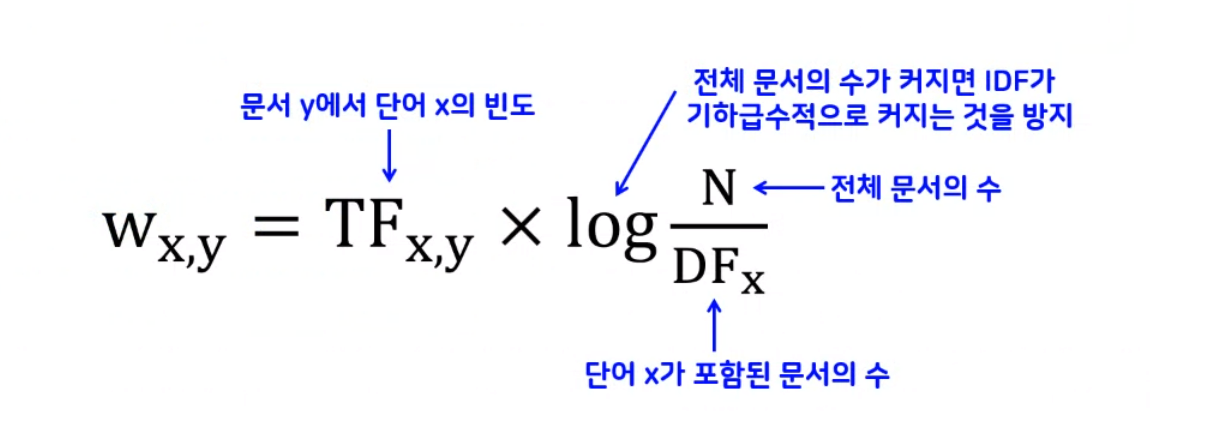
- TF-IDF(문서 내 빈도 수 확인하여 가중치를 준다.)
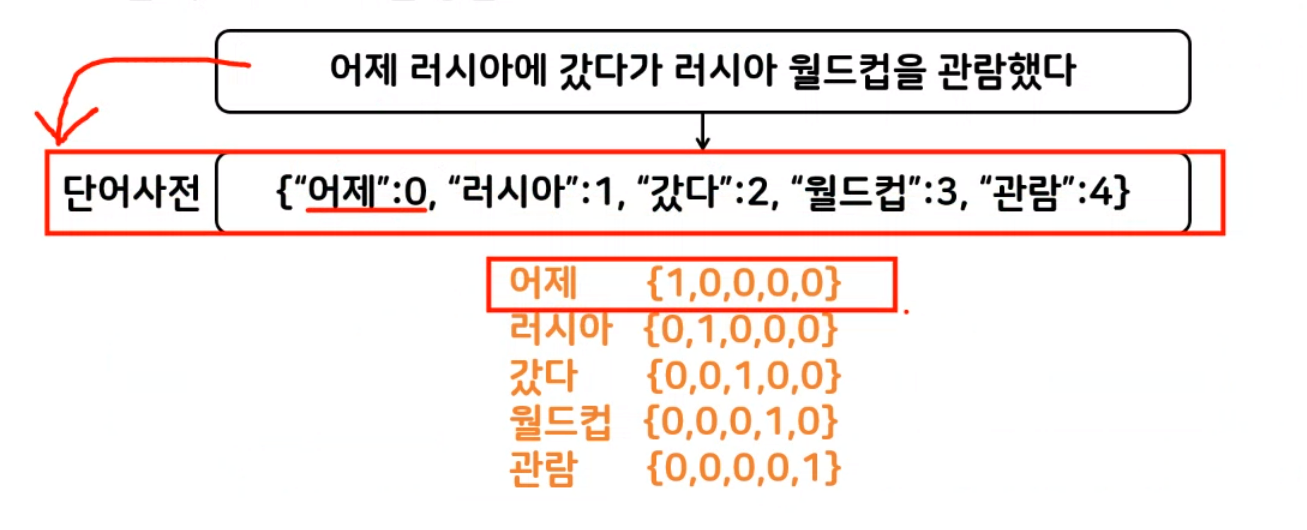
원 핫 인코딩
토큰에 고유번호를 배정하고 모든 고유번호 위치의 한 컬럼만 1, 나머지 컬럼은 벡터로 표시하는 방법
BOW
모든 문서의 모든 단어를 추출하여 피처로 만든다.

- 단순 카운트 기반의 백터화(CounterVectorize)
카운트 벡터화는 카운트 값이 높을 수록 중요한 단어로 인식(분별성X)
- TF-IDF(Term Frequency-Inverse Document Frequency)
카운트 벡터화 보완(패널티 부여)

영화 리뷰데이터 감성분석
문제정의
영화 리뷰 데이터를 활용해서 긍정, 부정, 감성분석 진행하자!
(특정 주제에 대한 글의 감성 태도를 파악하는 것)
텍스트데이터를 다루는 방법에 대해서 이해해보자!
라이브러리 호출
from sklearn.datasets import load_files
import numpy as np
import pandas as pd파일 불러오기
data_url = 'data/aclImdb/train/'
rv_train = load_files(data_url,shuffle=True)
rv_train
bunch 객체 : 머신러닝 자료구조 중 하나로 딕셔너리 처럼 사용 가능
key : value 형태의 데이터를 추출하기 위해 key 값을 활용하기!
리뷰 데이터 키값 확인하기
rv_train.keys()
문제 데이터 가져오기
txt_train = rv_train['data']정답데이터 담아주기
y_train = rv_train['target']정답데이터의 이름 확인하기
rv_train['target_names']
#['neg', 'pos']
# 0 == neg("부정")
# 1 == pos("긍정")테스트용 데이터 불러오기
data_url2 = 'data/aclImdb/test/'
rv_test = load_files(data_url2, shuffle=True)테스터용 데이터 분리하기
txt_test = rv_test['data']
y_test = rv_test['target']
#txt_test : 문제데이터
#y_test : 정답데이터텍스트 데이터 전처리
- 결측치, 불용어(의미없는 단어) 제거
- 오탈자 띄어쓰기 교정
- 정제, 정규화 어간추출, 표제어추출
불용어 처리(train 데이터)
train데이터(리스트) 내부에서 반복문을 통해
태그 제거하자. train데이터는 25000개로 그 수가 정해져 있기 때문에 for문을 사용하자.
list comprehension + 해당 리뷰들은 byte객체로 'b'를 붙여야 한다.
txt_train = [i.replace(b'<br />',b'')for i in txt_train]불용어 처리(테스트 데이터)
txt_test = [i.replace(b'<br />',b'')for i in txt_test]토큰화 연습
토큰화 연습하기
테스트 리스트
test_words =['Hello my name is youngwha', 'I love you', 'you are a student', 'I love myself','Hello how are you']
- 라이브러리 호출
from sklearn.feature_extraction.text import CountVectorizer
#CountVectorizer : 빈도수 기반 벡터화 도구
#오직 띄어쓰기만을 기준으로 하여 단어를 자른 후에 BOW를 만든다.- CountVectorizer 객체 생성
vect = CountVectorizer()- 단어사전 구축하기(학습시키기)
vect.fit(test_words)- 단어사전 확인하기
print(vect.vocabulary_)
#{'hello': 1, 'my': 5, 'name': 7, 'is': 3, 'youngwha': 10, 'love': 4, 'you': 9, 'are': 0, 'student': 8, 'myself': 6, 'how': 2}띄어쓰기 단위로 글자를 나눠주고 가방에 담아준 것이다.
- 위의 단어를 수치데이터로 변경
vect.transform(test_words)
#<5x11 sparse matrix of type '<class 'numpy.int64'>'
with 16 stored elements in Compressed Sparse Row format>- 수치데이터로 변경이 되었는지 확인
vect.transform(test_words).toarray()
#array([[0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1], Hello my name...
# [0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0], I love you
# [1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0], you are a studen..
# [0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0], i love mysel...
# [1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0]], dtype=int64)
# hello how are you토큰화
CountVectorizer 객체 생성
rv_vect = CountVectorizer()train데이터, test데이터 단어사전 구축(학습시키기)
rv_vect.fit(txt_train)
rv_vect.fit(txt_test)수치데이터로 변경
X_train = rv_vect.transform(txt_train)
X_test = rv_vect.transform(txt_test)모델링
로지스틱 회귀모델을 사용하여 긍, 부정 분류
- 라이브러리 호출(로지스틱 회귀)
from sklearn.linear_model import LogisticRegression- 모델 객체 생성
logi = LogisticRegression()- 모델 학습
logi.fit(X_train,y_train)- 모델 평가(정확도)
logi.score(X_train,y_test)로지스틱 선형 회귀모델에 확인해보기
첫 번째 리뷰
data = ["This was a horrible movie. It's a waste of time and money. It was like watching Desperately Seeking Susan meets Boo from Monsters Inc."]
#(굉장히 부정적인 리뷰)- 인코딩(문자열 리뷰데이터 ->수치화)
tf_data = rv_vect.transform(data)- 예측
logi.predict(tf_data)
#array([0]) 부정을 잘 맞췄다.두 번째 리뷰
data2 = ['It seems fun, but it\'s not fun']
tf_data2 = rv_vect.transform(data2)
logi.predict(tf_data2)
#array([1])재밌는 듯, 재미없다. 라는 리뷰는 부정적인 의미로 해석되지만 fun의 빈도수가 높기에 긍정을 의미하는 1이 출력되었다.
TF-IDF
TF-IDF(Term Frequency - Inverse Document Frequency)
단어의 중요도를 확인할 때 단순 카운트 기반이 아닌 모든 문서를 확인한 후에 특정 문서에만 자주 등장하는 단어들은 가중치를 부여하는 방식
TF : 하나의 문서에 등장하는 횟수
DF : 전체의 문서에 등장하는 횟수
결과값이 클 수록 중요도가 높은 단어이고, 결과값이 낮을 수록 중요도가 낮은 단어를 의미한다.
corpus = ['I love you',
'I hate you',
'you know I want your love',
'I miss you']
- 라이브러리 호출
from sklearn.feature_extraction.text import TfidfVectorizer- TfidfVectorizer 객체 생성
tfidf_vect = TfidfVectorizer()- 단어 사전 생성
tfidf_vect.fit(corpus)- 단어 사전 출력
print(tfidf_vect.vocabulary_)
- 내부 수치값 출력
tfidf_vect.transform(corpus).toarray()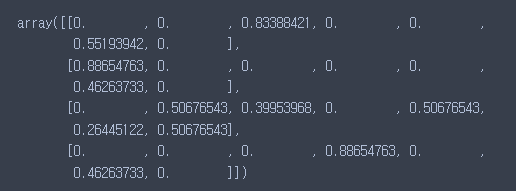
순서는 hate, know, love, miss,....
love는 you보다 낮은 빈도수로 나왔지만 you는 모든 문장에 나왔기 때문에 가중치가 떨어져있다.
