코랩 단축키
-
실행 단축키
- ctrl + Enter : 실행 후 커서가 그대로 위치
- shift + Enter : 실행 후 커서를 아래 셀로 이동
- alt + Enter : 실행 후 아래 셀 생성 + 아래로 이동
-
마크다운 변환(코드 -> 텍스트)
- ctrl + m + m
-
코드모드로 변환(텍스트 -> 코드)
- ctrl + m + y
-
셀 아래에 추가하기
- ctrl + m + b
-
셀 위에 추가하기
- ctrl + m + a
딥러닝 맛보기
딥러닝이란?
인간의 신경망을 모방하여 학습하고 예측하는 기술. 대량의 데이터에서 복잡한 패턴이나 규칙을 찾아내는 능력이 뛰어나며 머신러닝에 비해 조금 더 유연한 사고를 한다. 인간의 뉴런은 딥러닝에서 선형모델과 같은 의미이다. 주로 영상, 음성, 이미지처리에 사용된다.
tensorflow
구글이 만든 딥러닝을 위한 라이브러리이다.
keras
tensorflow위에서 동작하는 라이브러리로 사용자 친화적 라이브러리이다.
tensorflow 버전 확인
import tensorflow as tf
print(tf.__version__)
#2.13.0
#설치 버전 확인 이유 : 프로젝트 진행시 오픈소스를 가져다 쓸 때 충돌 방지리눅스 명령어를 사용하여 현재 작업 디렉토리 확인
!pwd
#/content
#코랩은 리눅스기반이기 때문에 리눅스 명령어를 그대로 사용이 가능하다.현재 작업 디렉토리의 파일 목록 조회
!ls
#sample_data
#현재 작업 디렉토리에 sample_data가 들어있다.작업 디렉토리 변경
%cd "/content/drive/MyDrive/Colab Notebooks/DeepLearning"
#/content/drive/MyDrive/Colab Notebooks/DeepLearning현재 작업 디렉토리 파일 확인
!pwd
#/content/drive/MyDrive/Colab Notebooks/DeepLearning
#변경완료!머신러닝모델과 딥러닝모델의 차이점
- 머신러닝
- 완제품 장난감 : 팔정도만 움직일 수 있음(하이퍼 파라미터만 조절)
- 모델생성(완성된 객체 사용) -> 모델 학습 -> 모델 예측 -> 모델 평가
- 딥러닝
- 레고블럭 : 다양한 구성이 가능
- 모델생성(모델을 직접 구성) -> 모델 학습 -> 모델 예측 -> 모델 평가
환경설정
공부시간에 따른 수학성적을 예측하는 회귀 모델을 만들어보자
keras 활용해서 신경망 구성하는 방법 연습
라이브러리 호출
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt데이터 불러오기
data = pd.read_csv('./data/student-mat.csv', delimiter=';')
data데이터 정보확인
data.info()
#컬럼수 33개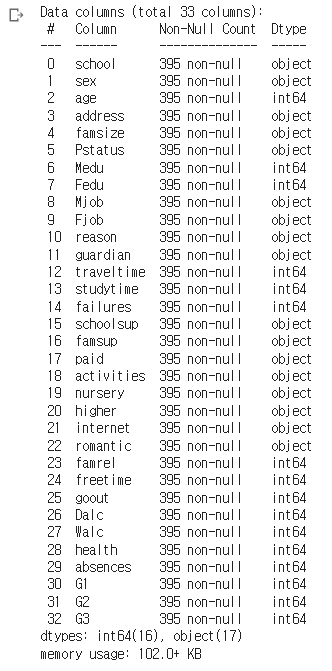
머신 러닝 모델링
문제와 답으로 분리
문제 데이터X(독립변수,입력특성) = studytime(13번 째 속성)
정답 데이터Y(종속변수,출력) = G3(33번 째 속성)
X = data['studytime']
y = data['G3'] 훈련용, 테스트용 분리
#라이브러리 호출
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=915,test_size=0.2
#random_state -> 무작위성을 915
#test_size=0.2 -> 20퍼센트만 테스트용으로 쓰고 80퍼센트는 훈련크기 확인
X_train.shape, y_train.shape, X_test.shape,y_test.shape
#((316,), (316,), (79,), (79,))선형회귀모델
from sklearn.linear_model import LinearRegression
#선형회귀
from sklearn.metrics import mean_squared_error
#회귀모델의 평가지표 도구1. 모델 생성
linear_model = LinearRegression()
#모델 생성(완제품 혹은 완성된 장난감) 이미 다 만들어져 있다.2. 모델 학습(학습용 문제, 학습용 정답)
linear_model.fit(X_train,y_train)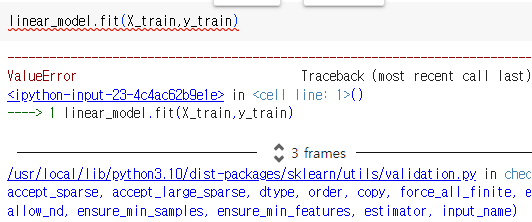
오류발생
linear_model.fit(X_train.values.reshape(-1,1),y_train)
#머신러닝 모델은 입력특성을 2차원으로 받는다!
#1차원 -> 2차원으로 변경3. 모델 예측(테스트용 문제)
linear_pre = linear_model.predict(X_test.values.reshape(-1,1))4. 모델 평가(실제값, 예측값)
mean_squared_error(y_test, linear_pre)
#실제정답,예측정답
#24.058078771701606 (MSE)
#4.8(RMSE)ㅔㅐ[[[[[
hello!