목표
타이타닉 데이터를 활용하여 생존자/사망자 예측하기
kaggle 경진 대회에 참가하여 우리 점수를 확인해보자
머신러닝의 전체 과정을 체험해보자
- 문제 정의 : 목표 설정, 어떤 모델을 선택할 것인지
- 데이터 수집 : 분류를 할 거라면 class로 담긴 레이블이 있는 데이터 수집
- 데이터 전처리 : 이상치 결측치 처리, 특성 처리(특성 공학)
- 데이터 탐색(탐색적 데이터 분석) : 기술 통계, 특성간의 관계 확인
- 모델 선택 및 하이퍼 파라미터 설정
- 모델 예측 및 평가
Kaggle
google에 'kaggle'검색
titanic 검색
data 다운로드
gender_submission.csv : predict를 잘했는지 kaggle에 제출하기 위한 파일
test.csv : 테스트용 파일(X_test)
train.csv : 훈련용 파일(X_train)
모두 다운로드
파일 경로 : C:\Users\gjaischool\Machine Learning\data

라이브러리 호출
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #시각화 라이브러리
import seaborn as sns #시각화 라이브러리
from sklearn.model_selection import train_test_split #train,test 분리 도구
from sklearn.metrics import accuracy_score #평가도구
from sklearn.tree import DecisionTreeClassifier #tree model - 사망/생존 이진분류train, test 변수에 데이터 불러와서 담기
인덱스를 승객의 번호로 설정해서 담아보자
train = pd.read_csv('./titanic/train.csv',index_col = "PassengerId")
train.head(3)
test = pd.read_csv('./titanic/test.csv',index_col = "PassengerId")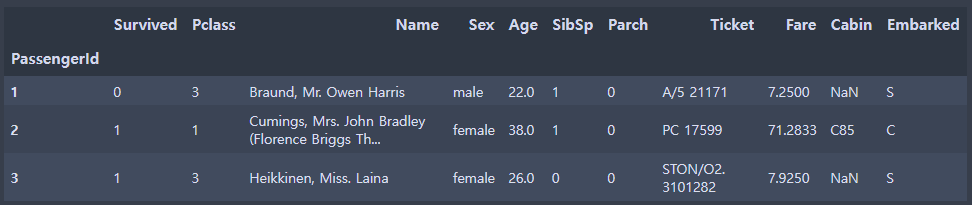
컬럼 정보 확인
train.info()
test.info()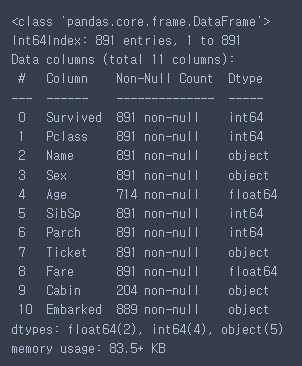
크기 확인
print(train.shape)
#(891, 11)
print(test.shape)
#(418, 10)컬럼명만 뽑아서 확인하기
print(train.columns)
#Index(['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Embarked'],
dtype='object')
print(test.columns)
#Index(['Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare',
'Cabin', 'Embarked'],
dtype='object')데이터 전처리 및 데이터 탐색
1. 훈련용 결측치 확인(info함수)
print(train.info())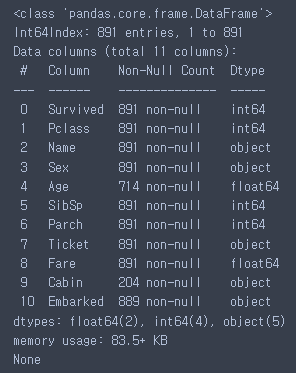
Age, Cabin, Embarked가 전체 개수와 맞지 않는 걸로 보아 결측치에 해당한다.
- 테스트용 결측치 확인(pandas 함수)
test.isnull()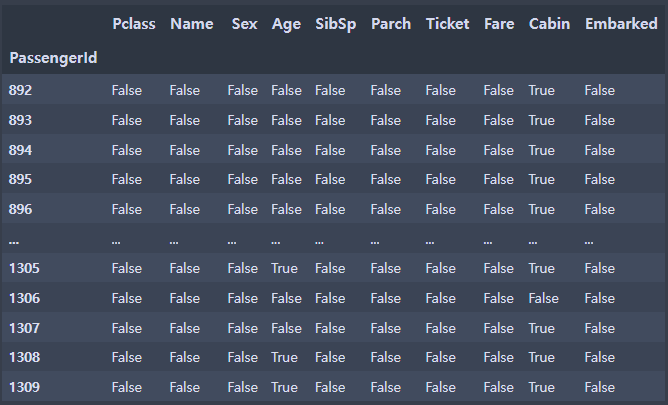
한 눈에 알아보기가 쉽지 않다.
test.isnull().sum()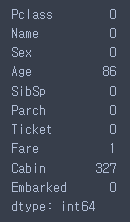
결측치 존재 컬럼 : Fare, Age, Cabin
결측치들을 제거하는 방법도 있으나 결측치를 채우면서 처리해보자(train-Embarked).
train-Embarked(승객이 탑승한 항구 이름) 결측치 처리
train['Embarked'].unique()
#array(['S', 'C', 'Q', nan], dtype=object)빈도수가 가장 높은 승선항 알파벳으로 결측치를 처리해보자.
train['Embarked'].value_counts()
#S 644
#C 168
#Q 77
#Name: Embarked, dtype: int64여기서 질문. test데이터 결측치는 안보나요?
탐색용 데이터는 train으로 모델이 학습을 잘 하도록 데이터를 셋팅하기 때문이다.
test 데이터는 모델을 일반화시키는데 도움이 되지 않는다.
train 데이터가 학습할 때 사용되고 모델의 일반화에 도움을 준다.
Embarked 결측치를 최빈값S로 결측치를 채워보자!fillna(값)
train['Embarked'] = train['Embarked'].fillna('S')
train['Embarked'].unique()
#array(['S', 'C', 'Q'], dtype=object) 결측치 제거 완료!결측치를 채우면서 처리해보자(test-Fare).
요금 평균, 중앙값 등으로 결측치를 처리할 수 있다. 데이터분석을 진행하면서 관련이 있을 법한 컬럼을 연관지어서 대체값을 확인해보자.
train-Fare 참고하여 데이터 탐색
train-Fare 컬럼 정보를 확인한다.
train['Fare'].describe()
#count 891.000000
#mean 32.204208
#std 49.693429
#min 0.000000
#25% 7.910400
#50% 14.454200
#75% 31.000000
#max 512.329200 흠..이거는 일반적인 값은 아닌 것 같애!
#Name: Fare, dtype: float64요금의 대표값으로 평균보다 중앙값이 더 나을 수 있겠다.
변수(특성)간의 상관관계 확인
상관계수(숫자) : -1 ~ 1 사이의 값으로 각 컬럼간의 상관 정도를 수치로 표현한 값. -1, 1에 가까울 수록 변수간의 관계성이 있다. 0에 가까울 수록 변수간의 관계성이 적다. 절대값을 붙여서 0 ~ 1사이의 값으로만 출력해보자.
train.corr()['Survived'].abs()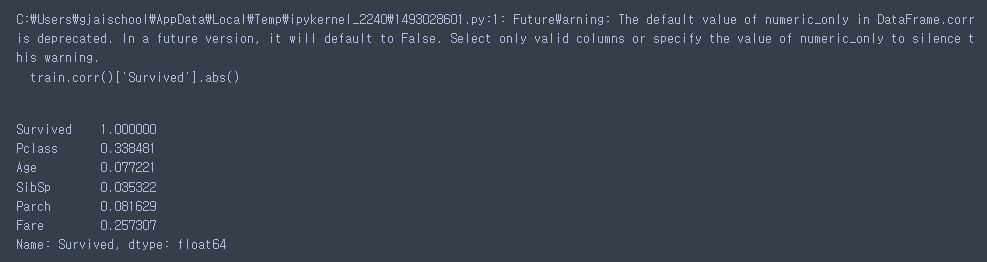
생존과 가장 상관관계가 높은 것은 등급(Pclass)이다. 등급에 따라 Fare를 참고해보자.
1. Pclass, Fare 두개 컬럼만 인덱싱
train[['Pclass','Fare']]2. Pclass 1, 2, 3등급끼리 묶기(그룹화하기)
train[['Pclass','Fare']].groupby('Pclass')3. median() 집계함수 연결
train[['Pclass','Fare']].groupby('Pclass').median()