논문 링크
contrastive learning을 제시한 초기 논문입니다.
0. 요약
이 논문은 다 읽고 한번 더 요약을 진행하였다.
단순하게 양성 sample과 가깝게, 음성 sample과는 멀게 학습한다는 부분에서 이전에서 사용하였던 contrastive learning과 비슷하긴 한데 조금 다른 점이 이 논문은 다양한 task에 적용을 할 수 있게 일반화를 진행하였다.
순서는 다음과 같다
- 고차원의 input을 encoder를 이용하여 embedding vector로 변환
- 이 input을 RNN과 같은 autoregressive 모델을 이용하여 미래를 예측
- 그 예측 값과 실제 값을 대조하여 미래를 잘 예측하도록 학습
양성과 음성을 나타내는 방법은 데이터 으로 N개의 sample이 존재할 때 로 미래시점 를 예측할 때 는 positive sample이고 나머지는 전부 negative sample이다.
이때 학습의 유사도를 표현하는 목표 값은 상호 정보 (mutual information)이다.
이 과정에서 encoder는 representation을 잘 표현하는 latent space를 가지게 된다.
Abstract
이 논문은 고차원의 데이터에서 유용한 representation을 학습하는 보편적인 unsupervised 학습 방법을 제시하며 이를 Contrastive Predictive Coding이라고 정의하였다.
중요한 요점은 autoregressive model의 latent space에서 미래의 sample을 예측 함으로써 유용한 representation을 학습하는 것이다.
이를 위해 확률적 대조 loss(probabilistic contrastive loss)를 제시하는데 이는 미래의 sample을 잘 예측할 수 있는 정보를 가지기 쉽도록 latent space를 유도하는 것이다.
이 방법의 장점은 speech, image, text, 3D 환경의 reinforcement learning 등 다양한 분야에서 사용될 수 있다.
1. Introduction
representation을 학습할 때에는 다양한 domain에서 적용이 되게 만들어야 한다.
예를들어 image classification task를 통해 representation이 학습이 된다면
색이나 색의 숫자에 대한 정보 등 image captionaing task에 적용이 될만한 information을 잃을 수 있다.
이러한 측면에서 unsupervised learning은 representation learning에서 훌륭한 방향이 될 수 있다.
대부분 공통적인 unsupervised learning의 전략은 미래나 missing 값이나 맥락적인 정보를 예측하는 것이다. (이전의 patch 위치 찾기 등)
이러한 predictive coding의 아이디어는 신호처리와 데이터 압축의 오래된 기술이다.
뇌 과학에서는 뇌는 다양한 추상화 수준의 관찰을 예측한다고 한다. (즉 다양한 정보를 통해서 예측)
이러한 아이디어는 다양한 분야에서 사용이 되는데
- nlp에서는 neighbor 단어를 토대로 단어를 예측하는 task (주변 단어를 토대로 예측)
- image 분야는 회색 이미지에서 색채우기, 이미지 patch의 위치 예측 등등
"이 접근 방식들이 효과적인 이유는, 우리가 예측하려는 관련 값들의 맥락(context)이 종종 동일한 고수준의 잠재 정보(latent information)에 조건부로 의존하기 때문이라고 가정합니다.
이를 예측 문제로 설정함으로써, 표현 학습에 중요한 특성들을 자동으로 추론할 수 있다는 것입니다."
말이 어려운데 위에서 제시한 기존의 방법은 데이터의 여러 부분이 공통된 고수준 정보를 공유한다는 점을 이용한다. 그리고 이를 예측 문제로 formulate함으로써, 모델이 자동으로 이러한 중요한 특성들을 학습하도록 유도한다는 것이다. 이는 효과적인 표현 학습(representation learning)을 가능하게 한다.
이 논문의 저자는 3가지를 제시한다.
- 고차원의 데이터를 latent embedding space로 압축해서 모델이 이를 조건 예측에 잘 활용할 수 있게 만든다.
- 이 latent space에서 autoregressive model을 활용해서 미래의 많은 step을 예측할 수 있게 만든다.
- Noise-Contrastive Estimation을 loss로 활용해서 모든 model이 end-to-end로 학습할 수 있게 만든다.
2. Contrastive Predicting Coding
2.1 Motivation and Intuitions
이 모델의 가장 주요 직관은 고차원의 서로다른 information 사이에서 공유되는 정보를 잘 표현하는 representation을 학습하는 동시에 low-level information과 noise를 버리는 것이다.
time series와 high dim modeling 같은 구조에서는 공유되는 정보가 매우 적기 때문에 모델이 미래를 예측하기 위해서는 global structure에 대한 정보가 필요하다.
(책의 story line, 말할때의 어조, 억양, 이미지의 물체 등)
high-dim의 데이터를 예측할 때의 문제점은 MSE나 cross-entropy는 useful하지 않기에 데이터의 모든 디테일을 재구축하는 과정이 필요한 강력한 조건부 생성형 모델이 필요하다.
그러나 이러한 모델은 너무 비싸고 데이터 에서 중요한 맥락 를 무시하는 등 낭비가 심하다.
예를들어 1개의 이미지는 수천개의 bit의 정보가 들어있지만 class에는 매우 적은 정보가 들어있다.(10bit -> 1024 class)
이때 를 학습하는 것은 와에 공유되는 정보를 뽑아내기에는 효과적이지 못한다.
대신에 미래의 정보를 예측할 때 목표 (future)와 맥락 (present)를 상호 정보(mutual information)를 최대한 보존한 분산 벡터 표현으로 encoding한다.
이때 상호 정보는 다음과 같다.
상호 정보량에 대해서 잘 몰라서 찾아보니 두 확률변수 x와 c의 의존성을 나타내는 수식이라고 한다.
예를 들어서 x와 c가 독립적이면 가 되고 log의 내부는 1이 되어 정보가 0이된다.
만약 가 된다면 log의 값은 1보다 크게 되어 양수가 되고 c는 x에 정보를 양의 영향만큼 준다는 것이 된다.
반면에 가 된다면 log의 값은 1보다 작게 되어 c는 x에 음의 영향만큼 주게 된다.
p(x,c)는 전체 정보량의 가중치의 역할을 하는 계수이다.
이러한 x와 c사이의 mutual information을 최대한담고있는 representation을 학습하는 것이 목표이다.
2.2 Contrastive Predictive Coding
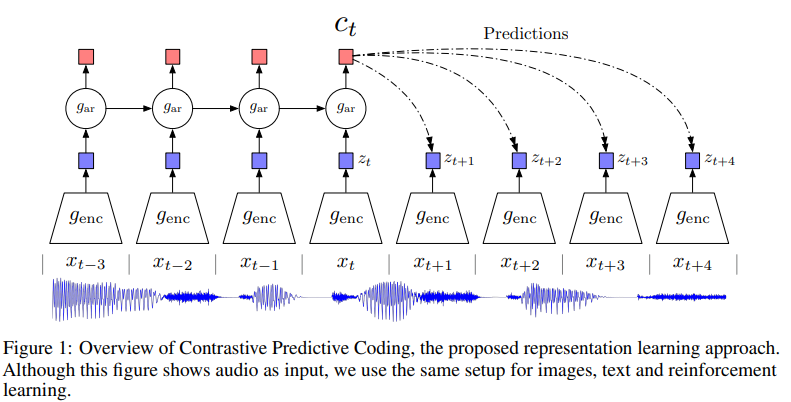 위 사진을 토대로 순차적으로 설명하겠다.
위 사진을 토대로 순차적으로 설명하겠다.
-
우선 non-linear encoder 가 sequence of observation 를 latent representation 으로 mapping한다.
,이때 잠시 resolution이 낮아질 가능성이 존재. -
그리고 다음 autoregressive model 이 인 모든 를 요약해서 context latent representation 를 만든다.
이전에 말했듯이 모델 를 이용해서 를 바로 예측하는 것이 아니라 mutual information을 보존하는 density ratio를 모델링한다.
이때 f는 다양한 식으로 표현이 가능한데 저자는 simple log-bilinear model을 사용하였다.
로 표현이 가능하다.
linear transformation 는 prediction 값이다. 그리고 각각 step k에 다른 가 사용이 된다.
대신에 recurrent model이 사용될 수도 있다.
비록 나 를 직접적으로 평가하지는 못하지만 그 분포에서 sample을 사용할 수 있다. 그리고 Noise-Contrastive Estimation과 Importance sampling 등으로 target value와 randomly sampled negative value에 기반을 둔 기법의 사용이 가능하다.
아마 이전에 contrastive learning 논문 리뷰로 제시된 방법을 생각하면 이해하기 쉬울 것 같다.
이후 나 는 downstream task에 representation으로 사용이 가능할 것이다.
autoregressive model이 만든 는 음성인식 등 과거의 input에 대한 정보가 필요하면 유용할 것이다.
만약 다른 context가 필요하지 않다면 가 유용할 것이다.
또는 image 분류 등 전체 sequence에 대한 1개의 representation이 필요하다면 나 의 모든 위치에 대해서 표현을 풀링할 수 있을 것이다.
2.3 InfoNCE Loss and Mutual Information Estimation
encoder와 autoregressive model은 infoNCE를 토대로 학습이 된다.
다음과 같이 표현이 되는데 set 의 N개의 sample에서 1개의 positive sample이 으로 포함이 되고 나머지는 로 부터 나온게 된다.
위 식으로 loss를 정의한다.
위 loss를 학습함으로써 가 density ratio를 추정하게 만들 수 있다.
여기에서 을 만족시키는지 확인하기 위해서 loss를 다르게 표현해보자
만약 가 positive일 때 loss의 최적화된 확률을 라고 할 때 는 c에 의존적이게 되어야 함으로 conditional distribution 의 확률이 나머지 의 확률보다 더 높아야 할 것이다.
이를 다음 식으로 표현이 가능한데
붅자는 양성 sample의 확률이기에 높아져야하고 분모는 음성 sample이기 때문에 낮아져야 한다.
이 식을 통해서 는 에 비례하게 되기에 negative sample의 숫자 에 관계없이 는 density ratio를 추정한다.
- 추가로 학습에 사용되지 않지만 와 사이의 mutual information을 다음 수식을 통해서 평가할 수 있다.
이 식을 보면 N이 클수록 하한이 커지게 된다. 또한 InfoNCE Loss를 더 작게 하는 것도 하한을 더 크게 만들어준다.수식의 유도 식은 다음과 같다. 가 density ratio에 proportional하기에 치환하여 사용하였다.

3. Experiments
다양한 도메인에 대한 bench mark test를 진행
speech, image, nlp, 강화학습
각 테스트에 CPC model을 학습하고 representation을 평가하기 위해 linear classification task나 qualitative evaluation을 진행 강화학습 같은 경우에는 agent의 learning 속도가 빨라지는지 확인
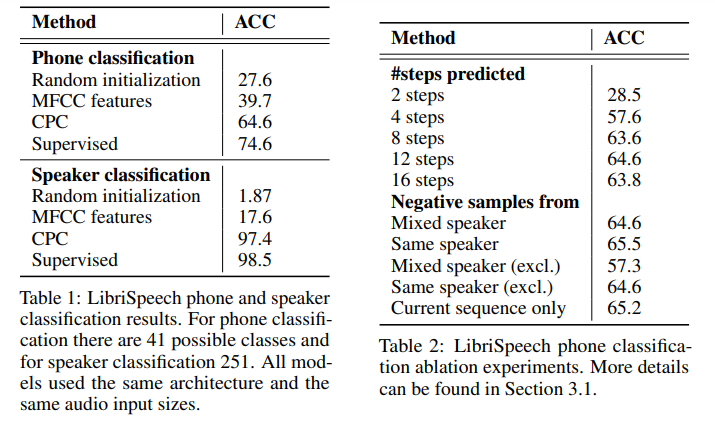
3.1 Audio
사실 시계열은 아직 본격적으로 배워보지 않았기에 잘 모르는 분야이다. 그렇기에 결과만 조금 보겠다.
10명의 speaker에 대한 t-SNE visualization(high-dim의 데이터를 서로의 유사도를 기준으로 2D 압축)결과

표현이 잘 된다.
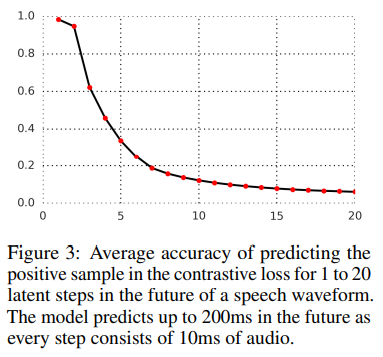
미래예측 정확도.
3.2 Vision
- ILSVRC ImageNet데이터
- image encoder: ResNet v2 101 without BN
학습은 256x256의 이미지를 7x7의 격자로 ptach화 하는데 이때 32pixel이 겹치는 64x64의 크기로 만든다.
이때 간단한 data augmentation은 256x256 image나 64x64이미지 어디든지 적용이 되면 도움이 된다고 한다.
처음 300x300의 image를 256x256으로 random crop하고 50%로 horizontally filp을 진행하고 grayscale한다.
64x64의 이미지는 60x60의 subcrop하고 다시 64x64로 resize를 진행한다.
각 crop은 ResNet v2 101 encoder로 encode되고 각 patch는 1024-d vector이 된다.
총 7x7x1024의 tensor이 구성이 되는데 이후 pixel-CNN style의 autoregressive model을 통해 각 column에 대해서 top-to-bottom으로 다음 pixel을 예측한다.'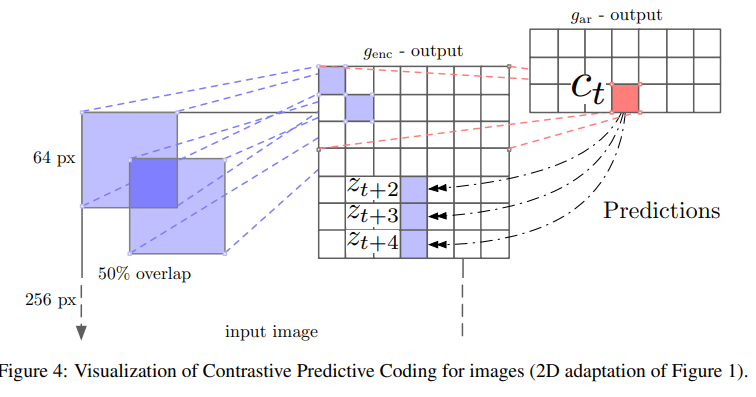 위 과정을 요약하면 그림과 같다.
위 과정을 요약하면 그림과 같다.
이를 통해 매우 좋은 결과를 내었다.
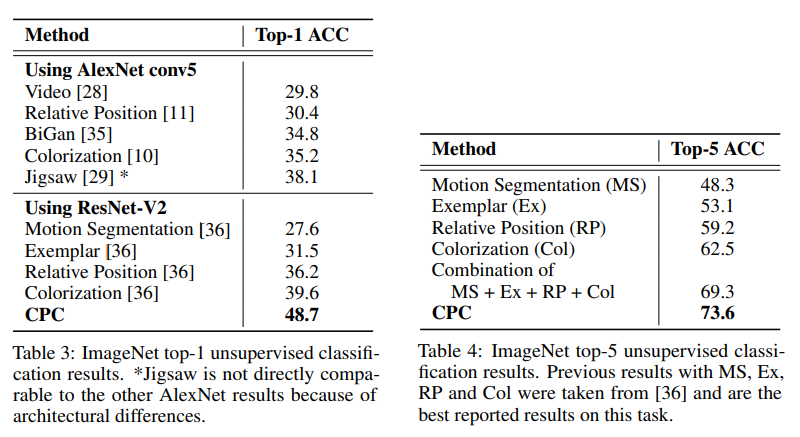
3.3 NLP
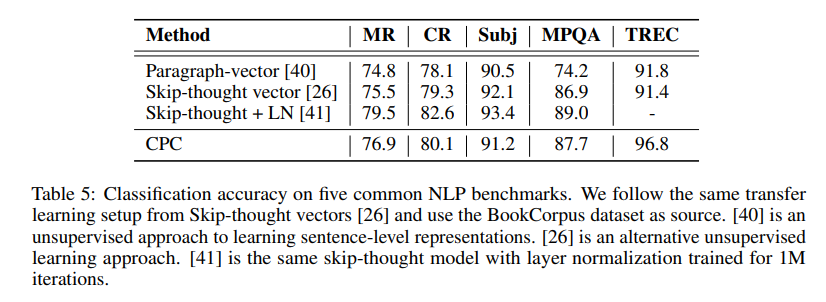
NLP분야에서 classification test를 위해 movie review sentiment(MR), customer product review(CR) 등 평가의 긍정 부정 등 classification이 가능한 dataset을 준비하였다.
encoder는 1-D convolution+ReLU+mean-pooling으로 구성이 되고
이는 전체 문장을 2400-d vector 로 임베딩할 수 있다.
이후 GRU가 최대 3개의 미래 문장 embedding을 예측한다.
결과는 다음과 같다.
3.4 reinforcement learning
학습 과정에서 reward가 대체적으로 빠르게 증가한다.