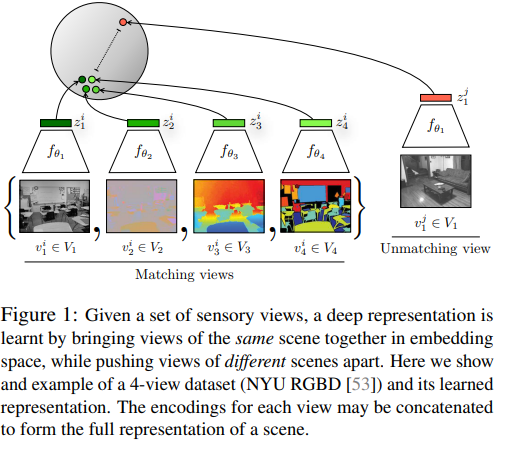
논문 링크
contrastive learning에서 기존의 양성 sample의 1대1 비교 대신 다양한 view를 통해 대조학습을 진행하는 방법
Abstract
인간은 세상을 다양한 감각 채널로 본다.(청각, 시각, 시각중에서도 오른쪽, 왼쪽 눈에서 오는 양안시차, 후각 등등)
각 view는 noisy하고 불완전하다. 그러나 중요한 요소인 물리, 기하학, 구조 등은 모든 뷰를 공유한다.(강아지를 보고 듣고 만지고 냄새를 맡을 수 있다.)
여기에서 논문의 저자는 강력한 representation은 view-invariant factor이라고 말한다.
이를 기반으로 muti-view contrastive learning을 제시한다.
이는 다양한 view 사이의 mutual information을 최대화 하는 것을 목표로 representation을 학습을 진행한다.
1. Introduction
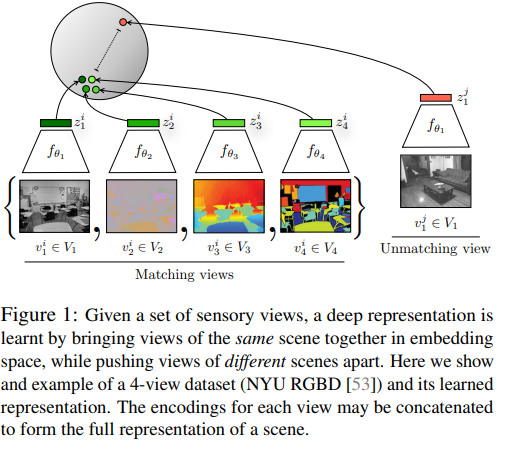
최근 데이터의 representation을 학습하는 방법은 autoencoder, generative model을 활용하여 losslessly를 중점으로 만드는 것이 중점이다.
그러나 lossless representation은 우리가 진정으로 원하는 것이 아니다. 그리고 도달하기도 쉽다. (raw data 자체가 이미 lossless이다.)
우리가 진정 원하는 것은 좋은 정보(signal)를 보존하고 나머지(noise)는 버린 representation이다.
어떻게 signal과 noise를 구분할 수 있을까?
기존 autoencoder에서 1개의 bit는 그냥 1개의 bit이다. 다른 것보다 더 좋거나 나쁘지 않다.
그러나 이논문에서는 특정 bits들이 다른 것보다 더 좋다고 가정한다.
몇몇 bit들은 물리, 기하 등등 중요한 정보를 포함한다고 생각한다.
반면 다른 bit들은 및의 밝기, 카메라 noise 등 덜 중요한 정보를 포함한다고 생각한다.
다시 처음으로 돌아가서 중요한 bit들의 특징은 다양한 view들 사이에서 공유된다고 생각한다.
이러한 시각에서 사진에서 "강아지의 존재"는 중요한 정보이다. 그러나 "카메라의 자세"는 중요하지 않은 정보이다. 어떻게 보냐 보다는 이미지의 내용이 중요하기 때문이다.
결국 이러한 가정을 토대로 inductive bias를 이끌어낼 수 있는데 내가 보는 방식은 그것의 의미에 영향을 주지 않는 다는 것이다.
이 논문은 이를 토대로 image를 밝기, 채도, 깊이 등등 다양한 채널로 나누고 모든 부분에서 공통적으로 이루어지는 중요한 signal을 추출할 수 있게 학습한다.
이를 위해서 contrastive learning을 사용하였다.
이때 이전 논문리뷰 Representation Learning with Contrastive Predictive Coding에서 제시한 방법을 그대로 활용하지는 않고
recurrent network를 없애고 일반화해서 적용하였다.
이를 Contrastive Multiview Codong(CMC)라고 명명하였다.
이렇게 만든 representation은 좋은 일반화 성능으로 다양한 테스트에서 SOTA의 성능을 보였다.
또한 view의 개수가 늘어날수록 representation의 품질이 좋아졌다.
3. Method
인간의 supervision 없이 representation을 학습하는 것이 목표이다.
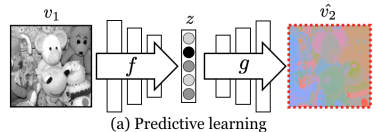
3.1 Predictive learning
이전의 방식을 비교하는 부분이다.
만약 가 각각 밝기와 색차를 의미하는 dataset의 2개의 view를 의미할 때 predictive learning setup은 데이터 을 축소한 를 토대로 를 예측하는 상황이고 , 로 표현이 가능하다. 여기에서 f는 encoder g는 decoder이다.
여기에서 loss(아래 그림의 빨간 점)은 에 적용이 되는데 예측 값 를 에 가깝게 만드는 것이 목표이기 때문에 과 의 각 픽셀이나 구성요소를 독립적이라고 가정한다. 그렇기 때문에 둘 사이의 공통된 정보를 학습하기는 적절하지 않다.
위 식은 각 에 따른 의 구성요소들의 확률을 높이는 것이 목표라는 것을 보여준다.
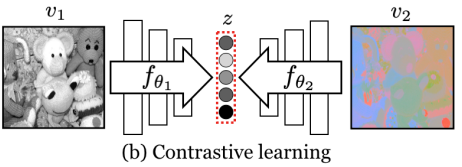
3.2 Contrastive Learning with Two Views
반면에 contrastive learning은 서로다른 분포에서 나온 sample을 구분(대조)하는 embedding을 학습하는 방법이다.
2개의 view를 비교하는데 view들이 맞거나(positive) 알맞지 않은(negative)을 비교해서 두 view를 구분할 수 있는 representation을 학습한다.
예를 들어서 과 가 으로 sample을 구성할 때
joint distribution의 나 를 따르면 positive sample이고
marginals의 곱 거나 이면 negative sample 이다.
간단하게 pair가 다른 분포를 따르느냐(negative), 같은 분포를 따르느냐(positive)의 차이이다.
이를 위해 "critic"을 학습하는데 는 positive pair은 높은 점수를, negative pair은 낮은 점수를 준다.
결국 single positive sample 를 k개의 negative smaple이 포함된 set 중에서 구분할 수 있는지를 학습하기 위함이다.
loss는 다음과 같다.
그리고 이는 다음과도 같이 설정할 수 있다.
형태를 보면 infoNCE와 비슷한 것을 알 수 있다.
Implementing the critic
는 이전에 InfoNCE를 사용하기 위해서 표현했던 것과 동일하다.
exp의 내부는 cosine similarity로 유사도를 표현하고 로 temperature를 나타내었다.
이 h 값을 바로 위에있는 에 넣음으로써 InfoNCE가 완성된다.
으로 표현이 된다.
여기에서 2개를 바꾸어서 더해주는 이유는 positive는 동일하더라도 negative가 바뀌기 때문이다.
3.3. Contrastive Learning with More than Two Views
이 논문의 메인 주제이다.
논문의 저자는 기존 infoNCE에서 여러개의 view를 처리할 수 있는 일반화된 loss를 제시하였다.
이를 "core view"와 "full graph" paradigm이라고 부른다.
각각 efficiency와 effectiveness를 의미한다.
그림으로 보면 아래와 같다.
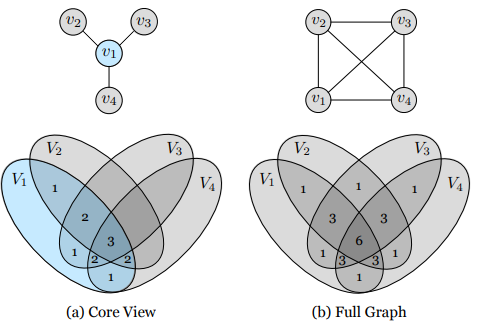
- core view는
로 에 대한 나머지 view를 더하는 것이다. - Full graph는
의 모든 pair를 더한 것으로
으로 구성이 된다.
보면 알듯이 core view는 을 기준으로 학습하기에 efficiency 하고
full graph는 모든 관계를 학습하기에 effectiveness하다.
그리고 두 경우 모두 view의 숫자에 비례해서 계산량이 늘어난다.
그러나 core view는 N으로 linear하게 증가하지만 full graph는 로 계산이 되기 때문에 으로 늘어나게 된다.(=n*(n-1)/2)
4. Experiments
multi view 를 기준으로 실험을 하였다.
4.1. Benchmarking CMC on ImageNet
이전의 다른 논문들과 비슷하게 학습된 representation을 가지고 위에 linear layer를 올리고 1000-class를 가진 imageNet을 학습하여 classification하는 것으로 평가를 진행하였다.
Setup
기존 RGB 이미지를 이미지로 변경한다. (L은 밝기, a는 green 에서 red 성분 b는 blue에서 yellow 성분)
그리고 이미지를 L과 ab 성분으로 나눈다.
동일한 sample의 L과 ab pair는 positive, 다른 sample은 negative pair이다.
각각 encoder를 통과하여 representation으로 만들어지고 InfoNCE를 통해 학습한다.
implementation
따로 언급이 없으면 pytorch default data augmentation을 사용하였고
는 0.07, memory update momentum은 0.5,
memory bank는 16384 negative sample이 있다.
결과는 아래와 같은데 ResNet-50 x?는 width 즉 채널의 넓음을 의미하고
왼쪽은 color space를
{L,ab}로 표현할지 {Y, Db, Dr}로 표현할지 그리고 RandAug를 표현할지 를 나타낸다.
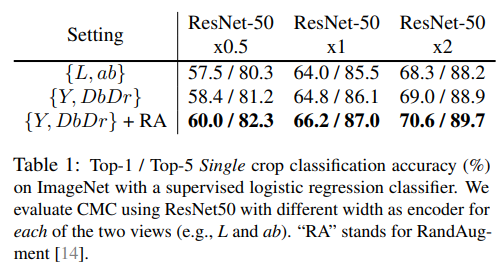
여기까진 view가 2개인 상황이다.
4.2 CMC on videos
video에서는 어떻게 적용을 하냐
사람의 눈은 2가지의 흐름으로 정보를 처리를 한다.
1. ventral stream: 이는 물체를 인식 한다.
2. dorsal stream: 이는 물체의 움직임을 처리한다.
비디오는 image의 연속된 흐름이다. t시간의 이미지는 로 표현이 가능하다.
그리고 dorsal stream은 연속된 시각적 흐름 로 표현을 해야하는데 이때 optical flow는 TV-L1 알고리즘을 사용했다고 한다.
optical flow에 대해서 잘 몰라서 찾아보니 물체의 움직임을 나타내는 알고리즘이라고 한다.
예를 들어서 이미지가 2개가 있는데 1개는 정지해있고 1개는 오른쪽으로 조금 이동해있는 이미지일 때 optical flow는 이 두 이미지 사이의 관계를 추정하여 오른쪽으로 이동한 정도를 나타낸다고 한다.
이때 ventral stream과 dorsal stream 각각의 이미지를 가지고 contrastive learning이 가능한데
- ventral stream의 경우 로 일정 시간 뒤의 동일한 이미지가 positive이고 다른 sample의 image가 negative이다.
- dorsal stream의 경우 로 표현이 가능한다 는 위에서 설명한 optical flow를 담은 정보이다. 역시 동일한 샘플의 같은 시간에 대한 정보가 positive, 다른 sample의 랜덤한 frame의 optical flow가 negative이다.
그리고 물체의 움직임 인식 데이터 UCF-101과 HMDB-51으로 성능을 평가했을 때
다음과 같다.
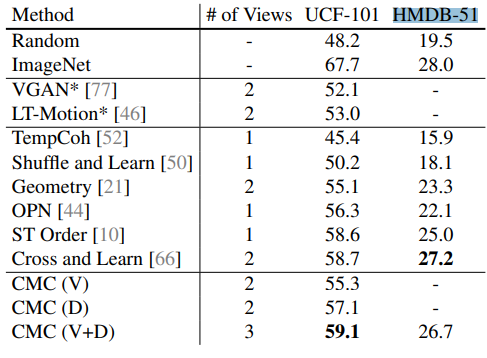 역시 V+D로 두 경우 모두 사용해서 view가 더 많은 경우가 더 성능이 잘나왔다.
역시 V+D로 두 경우 모두 사용해서 view가 더 많은 경우가 더 성능이 잘나왔다.
4.3 Extending CMC to More Views
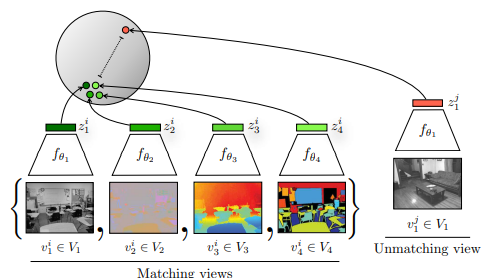 처음 소개 이미지에서 본 것처럼 매우 많은 view를 사용하는 경우를 테스트 하려고 한다.
처음 소개 이미지에서 본 것처럼 매우 많은 view를 사용하는 경우를 테스트 하려고 한다.
이때 고려하는 view는 luminance(밝기, 이전의 L), chrominance(이전의 ab), depth, surface normal, semantic labels이다.
각각의 view를 토대로 feature을 추출하는데 데이터셋의 크기가 작아 1개의 이미지를 작은 patch로 나누어서 사용이 되었다.(원본 480x640 -> randomcrop 128x128여러개)
4.3.1 Does representation quality improve as number of views increases?
L을 core-view로 사용해서 나머지를 ab, depth, surface normal을 점차 추가하며 보았는데 결과는 mean IOU over all class랑 pixel accuracy로 평가를 하였다.
결과는 아래와 같다.
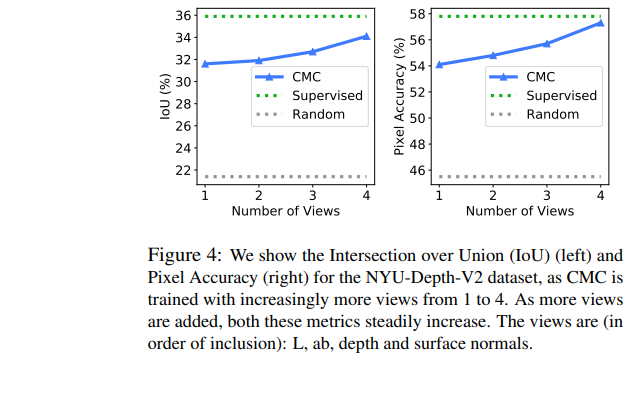 view가 늘어날수록 정확도가 상승한다. 여기에서 view가 1개인 경우는 patch base로 patch들 사이에서 같은 sample이냐 아니냐로 contrastive learning을 진행한 것으로 봉니다.
view가 늘어날수록 정확도가 상승한다. 여기에서 view가 1개인 경우는 patch base로 patch들 사이에서 같은 sample이냐 아니냐로 contrastive learning을 진행한 것으로 봉니다.
4.3.2 Is CMC improving all views?
이전에는 L을 기준으로 테스트를 하였는데 이번에는 모든 view를 동등하게 보고 테스트를 진행한다.
이를 위해서 full graph paradigm을 사용하였다.
방법이 신기한데 각각 view를 full-gaph로 동등하게 학습을 하고 1개씩 view를 학습한 representation을 활용하여 semantic label prediction 평가를 진행하였다.
결과는 아래와 같은데
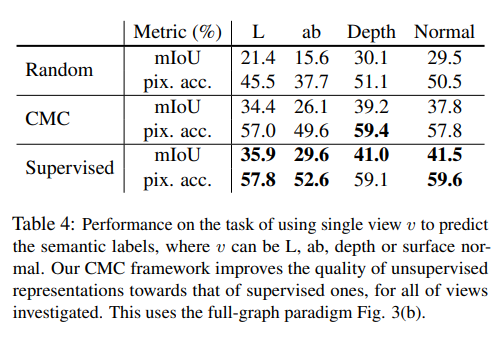 처음 random하게 initialized된 것보다 CMC로 학습을 진행하고 representation을 학습한 것이 더욱 좋은 성능을 보였다. 이를 통해 모든 view에서의 representation 성능의 향상을 볼 수 있음을 알 수 있다.
처음 random하게 initialized된 것보다 CMC로 학습을 진행하고 representation을 학습한 것이 더욱 좋은 성능을 보였다. 이를 통해 모든 view에서의 representation 성능의 향상을 볼 수 있음을 알 수 있다.
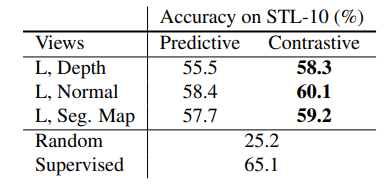
4.3.3 Predictive Learning vs. Contrastive Learning
predictive 보다 contrastive learning이 더 좋은 representation을 학습한다.
4.4. How does mutual information affect representation quality?
고정된 숫자의 view가 주어졌을 때 CMC는 mutual information의 최대화를 목적으로 학습이 진행된다.
그러나 information maximization은 좋은 representation에 있어서 중요할까?
실제로 이 논문이 제시하는 내용은 반대를 주장한다.
왜냐하면 cross-view representation이 좋은 성능을 보이지만 이는 information의 maximization이 아니라 minimization이다. 여러 view들 사이에서 공유되지 않는 information을 버리는 식으로 진행되기 때문이다.
학습 과정에서 가장 좋은 view는 몇몇 정보를 공유하지만 너무 많이 공유하면 안된다. 즉 "Goldilocks principle"이라고 설명하는데 공유하는 정보가 너무 적으면 학습할 정보가 거의 없기에 진행이 잘 되지 않고 공유하는 정보가 너무 많으면 정보를 다 포함하려고 하기 때문에 noise도 많이 포함하게 된다.
아래는 상호 정보량과 정확도의 테스트이다.
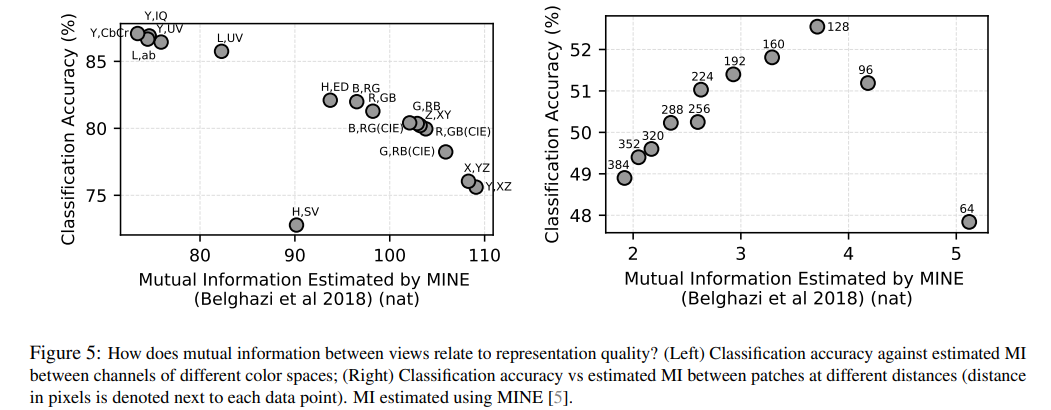
아래 x축은 MINE으로 측정한 상호 정보량이고 y축은 정확도인데
왼쪽 1개의 이미지를 color space view를 다르게해서 학습을 진행한 것이고 오른쪽은 1개의 이미지를 겹치지 않는 patch로 나눠서 같은 smaple인지로 학습을 진행한 것이다. 이때 상호 정보량은 각각 color를 나누는 방법, patch의 거리(이미지에 있음)로 조절했다.
보면 왼쪽의 경우 상호정보량이 가장 적을 때 성능이 제일 좋았고
오른쪽의 경우 적절한 distance가 성능이 가장 좋았다.
즉 적절한 view를 사용한 정보의 공유가 제일 좋다는 말이다.
