Abstract
이 논문에서는 unsupervised visual representation learning의 방법론으로 contrastive learning에 Momentum Contrast(MoCo)라는 방법을 적용하는 것을 제시합니다.
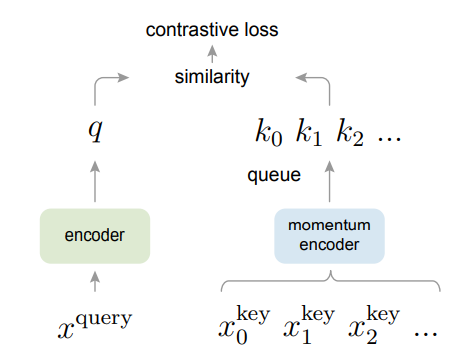
MoCo는 요약하자면 contrastive learning에서 queue를 활용한 dynamic directory와 moving averaged encoder를 활용해 학습을 진행한다.
바로 이전에 리뷰한 SimCLR 구조의 단점을 보완한 논문이다.
1. Introduction
nlp 분야에서의 unsupervised learning은 discrete한 signal space(word, sub-word, token 등)를 가지기 때문에 tokenized directory를 만들기 상대적으로 쉽기에 성공적으로 진행이 되었다.
그러나 이미지 분야는 이미지는 각 픽셀이 연관이 되어있고 고차원의 영역을 가지기 때문에 word 등과 같이 사람에 의해서 구조화가 되지 않는다. 그렇기에 tokenized directory를 만들기 매우 어렵다.
최근 연구들은 contrastive learning에서 동적사전(dynamic dictionaries)를 구축하는 것이 핵심으로 보인다.
이 사전의 key는 데이터(이미지, patch 등)에서 sampling을 한 후 encoder를 통해 표현이 된다.
이때 비지도 학습을 통해 encoding이 된 "query"가 matching 되는 key와 가깝고 다른 key와는 다르게 학습이 된다.
이때 MoCo의 연구진들은 위 과정에서 directory가
- large
- consistent
하는 것이 핵심이라고 보았다.
직관적으로 dictionary가 클수록 비교할 수 있는 negative sample이 많아지고 encoder이 consistent하지 않으면 표현이 바뀌어서 결과가 그때그때 달라지기 때문이다.
MoCo
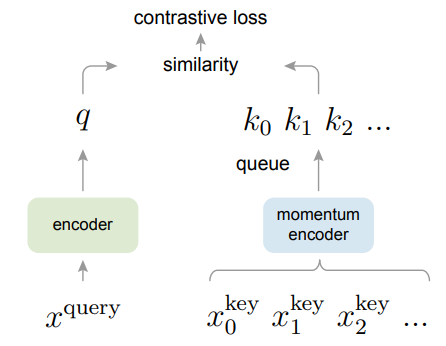 이러한 부분에 중점을 두고 large and consistent dictionary를 만들기 위한 방법론인 MoCo를 제시한다.
이러한 부분에 중점을 두고 large and consistent dictionary를 만들기 위한 방법론인 MoCo를 제시한다.
MoCo는 기존 contrastive learning에서 batch size 내부에서 positive, negative sample을 나눠서 학습하기 때문에 제한되는 학습 크기를
dictionary를 이용해서 분리시켰다.
즉 dictionary size는 batch size와 독립이다. 그렇기 때문에 매우 큰 크기를 만들 수 있다.
이러한 상황에서 오래된 encoded key는 dequeue되고 mini batch의 새롭게 만들어지는 key는 enqueue 된다.
그리고 여기에서 momentum encoder이라고 적힌 이유는 key를 만들어내는 encoder가 빠르게 학습이 되면 representation이 빠르게 바뀌기 때문에 이전에 dictionary의 key들이 다 소용이 없어지게 된다.
그렇게 된다면 query encoder는 학습이 매우 불안정해진다. 기준이 없기 때문에
그렇기 때문에 momentum을 이용해 조금씩 변화를 주어서 한번에 큰 변경이 없게 만들어 이를 바탕으로 query encoder의 학습을 안정적으로 진행을한다.
이러한 바탕으로 MoCo는 매우 좋은 성능을 내었다.
3. Method
3.1. Contrastive Learning as Dictionary Look-up
contrastive learning은 encoder가 dictionary look-up task를 학습하는 과정으로도 볼 수 있다고 하는데
InfoNCE loss를 보면 쉽게 이해할 수 있다.
query(q)에 대해서 는 positive sample이고 분모의 는 negative sample이다.
처음 batch의 sample에서 query와 positive sample을 만들고 dot product를 이용한 similarity를 계산한다.
이때 -log의 내부가 커져야 loss가 줄어들기 때문에 분자의 positive sample과는 유사도가 커져야하고
분모의 negative sample들과는 유사도가 작아져야 한다.
이는 (K+1)개의 softmax를 통과한 cross entropy classifier loss와 비슷하다.
- 결국 분모에서 queue에 들어있는 모든 sample들과 유사도를 계산하기 때문에 dictionary lookup이라고 부른다. 이를 통해 query, key encoder를 학습한다.
3.2. Momentum Contrast
위에서 large한 dynamic dictionary를 만드는 것은 달성하였다. 여기에서 large하기 때문에 많은 negative sample을 통해 잘 학습할 수 있다.
그러나 동시에 key encoder도 학습이 진행이 될 것이다.
그렇게 된다면 representation이 바뀌게 되어 consistent하지 못하게 되어 학습이 불안정하게 된다.
이를 위해 momentum을 통해 key encoder를 점진적으로 학습한다.
이때 SimCLR과 MoCo의 큰 차이점이 나오는데 SimCLR은 여기에서 Query key를 만드는 encoder와 projection이 동일하다.
그러나 과거의 값을 dictionary에 넣어 사용하는데 이렇게 된다면 representation을 학습해야할 기준이 계속 바뀌어서 학습이 제대로 이루어지지 않을 것이다.
그렇기 때문에 MoCo는 key encoder을 따로두고 점진적으로 학습을 시켜 query encoder를 위한 기준을 만들어주었다.
Momentum update
key encoder는 back propagation이 진행되지 않는다. 왜냐하면 key encoder를 거친 queue의 모든 negative sample을 전부 back propagation을 진행할 수 없기 때문이다.
그렇기 때문에 MoCo는 momentum hyper param m을 두고
의 수식으로
key encoder의 wieght를 유지하면서 q weight의 일정부분을 가져와서 점차 변경한다.
이는 매우 느리게 진행이 되는데 representation 유지를 위해 와 같이 매우 큰 값으로 설정이 된다. 이 값이 작으면 오히려 결과가 안좋아진다고 한다.
학습은 만 진행이 된다.
Relations to previous mechanisms.
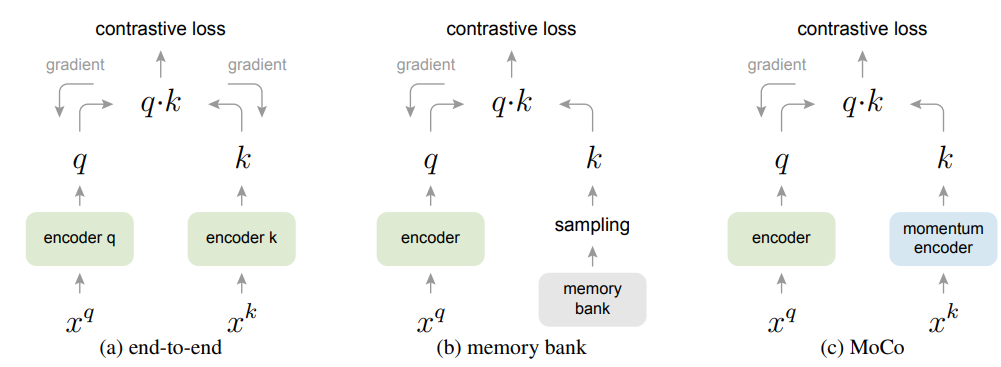 이전의 다른 방법들과 비교를 하자면
이전의 다른 방법들과 비교를 하자면
- (a)는 SimCLR과 동일한 구조이다. batch에서 뽑아낸 데이터로만 end-to-end 학습이 진행이 된다.
동일한 batch에서 encode하기 때문에 학습이 consistent하다. 그러나 directory size인 batch size가 커야 negative sample이 많아져서 학습이 잘 되는데 vram의 한계로 성능이 제한이 된다. - (b)는 memory bank를 이용해서 모든 sample의 representation을 저장하고 학습시에는 memory bank의 key 중에서 몇개를 sampling하여서 학습을 진행한다.
이때 back propagation은 없다. dictionary size는 매우 크게 키울 수 있지만 결국 memory bank의 representation은 업데이트가 되지 않아 과거에 봤던 동일한 품질이 떨어지는 sample representation을 몇번 학습한 이후에도 보게되어 consistent가 떨어진다.
3.3 Pretext Task
MoCo는 pretext task를 만드는 것이 목표가 아니라 기존의 방법을 사용하였다.
단지 같은 sample에서 augment를 거쳐서 나오면 positive이고 다른 sample에서 augment가 적용이 되면 negative sample이다.
Code
MoCo에 대한 이해는 코드를 보면 이해가 쉬울 것이다.

Technical details.
- Encoder: resnet(last FN(after global avg fooling) 128-Dim)
- data augment: 224x224 random crop from random resized img,
random color jitter, random grayscale conversion, random horizontal flip
Shuffling BN
ResNet model의 내부에 BN이 있지만 이전의 연구결과에 따르면 BN을 사용하는 것이 좋은 representation을 학습하는 것을 막는다고 한다.
이는 SimCLR 논문에서도 Global BN을 이야기하며 언급이 되었다.
distributed learning을 진행하게 되면 device들에게 batch를 나눠주고 학습이 진행이 되는데 positive sample과 동일한 분포로 normalize가 되면 통계치가 같아져 shortcut이 만들어질 수 있고 정보가 유출이 된다.
극단적으로 1개의 device에 positive와 original data만 존재할 때를 그림으로 간단하게 표현해보았다. BN은 편리를 위해 대강 평균으로 나타냈다. 결론은 batch들끼리 비슷한 통계를 가지게 모이기 때문에 query sample을 골랐을 때 어느게 positive sample인지 알아보기 쉽게 되었다.
이 문제를 shuffle batch를 통해서 해결하였다.
shuffle batch는 간단하게 Query에 들어가는 batch와 Key에 들어가는 batch가 다른 것이다.
예를 들면 query에 들어가는 mini batch가 gpu0에는 batch A, gpu1에는 batch B가 들어갈 때
key에 들어가는 mini batch는 batch A와 batch B를 다시 섞고 재분배한 shuffled batch를 나눠준다.
결국 gpu0에는 shuffled batch A, gpu1에는 shuffled batch B를 넣어주는 것이다. -> encoder를 통과한 이후 다시 복구한다.
이러면 query와 key가 각자 다른 분포를 가지게 되어 정보의 유출을 막을 수 있다.
4. Experiments
- ImageNet-1M (1000 class)
- Instagram-1B
데이터로 테스트를 진행하였다.
인스타그램 데이터는 처음보는데 이미지넷과 비슷한 해시태그가 최대 1500개 존재한다고 한다.
그리고 real world data라서 분포가 복잡하다고 한다.
학습
- SGD
- weight decay 0.0001
- momentum 0.9
- mini batch 256(imagenet 1M)-8 GPU, 1024(instagram)-64GPU
- 8 gpu
- 200 epoch
- lr 0.03 start 120, 160 epoch마다 0.1씩 곱셈
- encoder resnet50
4.1. Linear Classification Protocol
feature학습한 weight는 얼리고 마지막에 classifier 기능을 하는 linear layer만 추가해서 학습한 결과 분석이다.
contrastive loss mechanisms.
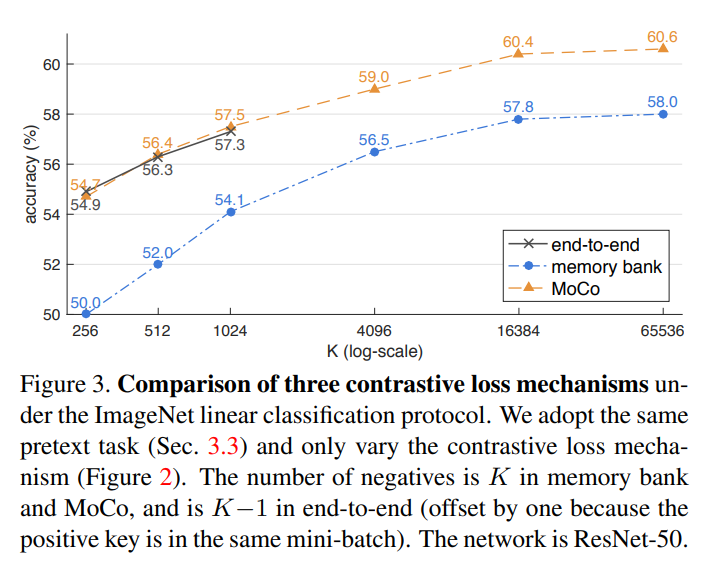 end-to-end도 성능이 좋았지만 K 즉 batch가 커지면 진행이 안되어서 큰 batch를보면 결국
end-to-end도 성능이 좋았지만 K 즉 batch가 커지면 진행이 안되어서 큰 batch를보면 결국
MoCo가 가장 성능이 좋았다.
momentum.
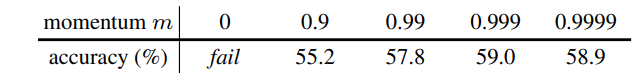 적절한 값이 중요하지만 0이면 아예 수렴이 되지 않는다. 논문 테스트 기준 0.999가 제일 좋았다.
적절한 값이 중요하지만 0이면 아예 수렴이 되지 않는다. 논문 테스트 기준 0.999가 제일 좋았다.
4.2. Transferring Features
unsupervised learning의 목적 중 하나는 tansfer에서 성능을 잘 내는 representation을 학습하는 것이다.
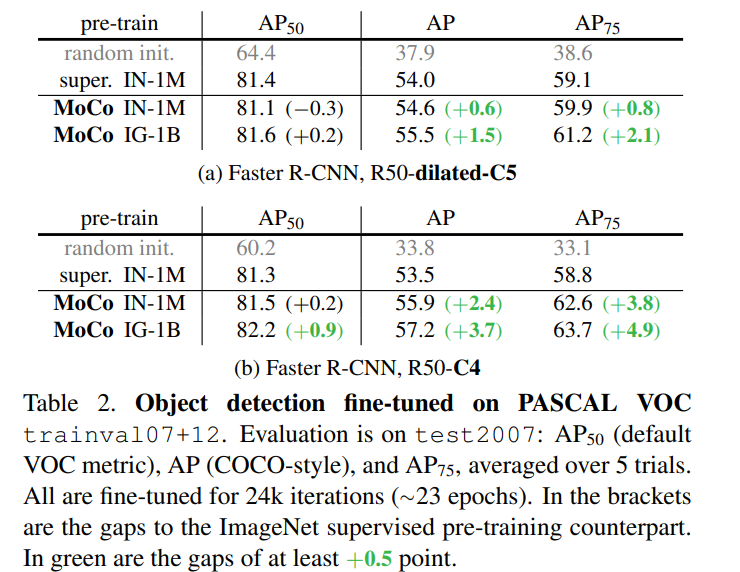 신기했던 부분은 supervised pre-train보다 MoCo로 pretrain을 진행하고 fine-tune을 진행한 것이 더 좋은 성능을 보일 때가 있다는 것이다.
신기했던 부분은 supervised pre-train보다 MoCo로 pretrain을 진행하고 fine-tune을 진행한 것이 더 좋은 성능을 보일 때가 있다는 것이다.
이는 MoCo로 학습하는 것이 label을 사용해서 학습하는 것보다 더 좋은 representation을 가질 수 있다는 것을 의미한다.
이때 학습은 supervised pretrain과 동일한 조건에서 진행이 되었다.
그렇기 때문에 아마 hyper param tuning을 통해서 더 성능을 끌어올릴 수 있을 것 같다.
supervised pretrain보다 object detection 부분에서 성능이 더 잘나오는 이유는
pretext task와 연관이 있다.
supervised는 label이 존재하기 때문에 1개의 object에 대해서만 집중해서 판별한다.
그러나 pretrain은 label이 존재하지 않기 때문에 object를 detect하는 부분에 더 집중을 하기 때문에 더 object detection 부분에 강점을 보이는 것이다.
즉 pretext task와 fine-tune의 task가 비슷하기 때문이다.실제로 imagenet classification 부분은 supervised pretrain이 더 정확도가 높다.
5. Conclusion
MoCo 방법론은 dynamic dictionary를 통해 negative sample의 size를 획기적으로 늘리는 동시에 momentum으로 일관성을 유지하는 매우 훌륭한 방법론을 제시하였다.
다양한 곳에 사용이 가능할 것 같다.
구현
링크를 참조하자
