요약
요약하자면 Dreamer V1에서 개선을 거친 모델이다.
개선은 다음과 같다.
- Categorical Latent
- KL Balancing
- discount factor model 추가
- critic에 target network 사용 및 -target 재귀화
- Actor에 Reinforce Gradient와 entropy regularizatoin 추가
이 외는 사실 Dreamer V1과 동일한 부분이 대부분이다.
Abstract
world model은 environment의 past experience를 generalize하고 이를 활용해서 imagined outcome으로부터 학습이 가능하게 하였다.
그러나 world model이 Atari game을 정확하게 모델링 하는 것은 어려운 task로 남아있었다.
이 논문은 Dreamer v2를 제시하는데 이는 compact latent space에서 world model이 만드는 prediction으로 학습을 하는 agent를 활용해서 Atari game을 인간보다 잘하는 agent를 만들었다.
1 INTRODUCTION
world model은 agent가 가지고 있는 환경에 대한 지식을 모델링한다.
시행착오로 학습하는 다른 mbrl과는 다르게 world model은 경험을 일반화하고 잠재적인 행동에 대해서 미래를 예측한다. 이에 따라서 planning이 가능하다.
world model은 사람이 과거의 과거의 경험에 따라서 지식이 만들어지고 이를 이용해서 자연스럽게 미래를 예측하는 것이라고 보면 된다.(원본 논문에서는 야구선수가 공을 치는 것에 비유)
그러나 world model은 대부분의 benchmark에서 model-free를 이기기에는 부족한 부분이 있다.
Atari의 경우 기존에 나왔던 DQN, A3C 등의 알고리즘을 이길 수가 없었다.
이 논문은 Dreamer V2를 제시한다.
world model을 활용해서 Atari game에서 인간을 이긴 처음 모델이라고 한다.
기존의 dreamer에서 약간의 차이만 주었는데 discrete latent와 KL loss의 balancing이라고 한다.
환경을 잘 표현할수록 agent의 성능이 잘나온다고 함.
2 DREAMERV2
2.1 WORLD MODEL LEARNING
world model은 과거를 학습해서 predictive model을 구성한 다음. 환경을 대신해서 agent의 행동을 학습할 수 있다.
Dreamer v1과의 차이점은 world model이 Gaussian latent를 categorical variable로 바꾸었다고 한다.
즉 기존 latent는 확률적으로 sampling하였는데 이를 특정 categorical로 정해진 개수의 embedding으로 표현한다는 것 같다.
Experience dataset
- 이미지
- action
- rewards
- discount factor
여기에서 discount factor은 마지막 step을 제외하고 0.999로 설정. 마지막은 0
batch , sequence len
그리고 각 sequence data를 뽑을 때 각 episode를 내에서 sampling하는데 episode를 초과해서 sampling하지 않도록 한다.
(episode가 종료되는 것을 잘 관찰하기 위해)
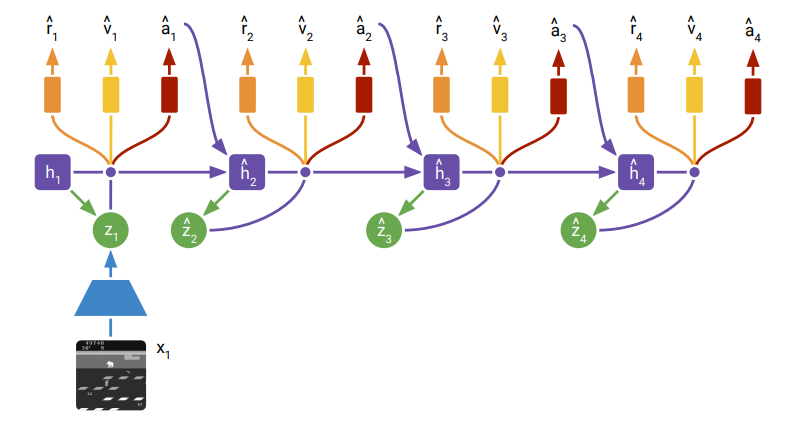
Model components
- image encoder, RSSM
- image, reward, discount predictors
RSSM은 deterministic recurrent state: ,
stochastic: posterior ( current image 활용해서 나오는 값), prior (posterior을 예측하는 값)
여기에서 , 2개를 concat한 것이 compact model state이다.
posterior model state에서 , , 를 예측한다.
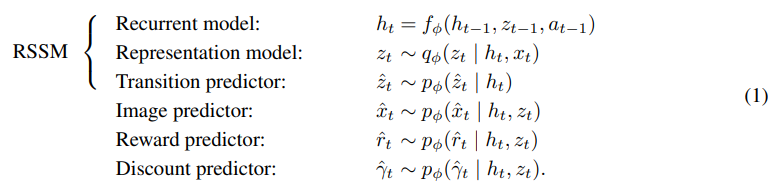 즉 모델은 위와 같이 구성된다.(사실 discount 제외하면 dreamer v1과 사실상 동일한 구조)
즉 모델은 위와 같이 구성된다.(사실 discount 제외하면 dreamer v1과 사실상 동일한 구조)
그리고 모든 world model은 로 동일한 param 묶음으로 학습된다.
discount factor은 episode가 얼만큼 끝에 가까워졌는지 알기 위한 요소이다.
Neural networks
representation model은 CNN + MLP로 구성된다. 이때 MLP가 image embedding, deterministic state의 concat을 입력받는다.
RSSM은 GRU로 deterministic recurrent state를 계산.
image predictor은 transposed CNN
transitoin, reward, discount predictor은 MLP
모든 activation function은 ELU
84x84이미지는 64x64로 줄여서 CNN사용.
Distributions
image predictor은 Gaussian 분포로 분산 1로 샘플링
보상 예측도 동일하게 가우시안 분포를 가지고 분산 1로 샘플링
Discount factor은 베르누이 분포를 예측(1 또는 0)
그리고 이전 dreamer v1의 latent state는 Gaussian에서 reparametrization으로 나온 값을 사용하였는데
v2에서는 categorical variable을 가지고 사용한다.
미분은 straight-Through 즉 아래 그림과 같이 한다.
Loss function
world model은 동시에 학습.
각각 predictor들의 output으로 만들어내는 분포는
log-likelihood를 최대화 하도록 학습이 되어야 한다.
이때 representation model은 이러한 prediction이 쉽게 만드는데 이때 높은 entropy를 가지도록 규제를 한다. -> 이러면 다양한 state에서 robust하게 학습할 수 있기 때문.
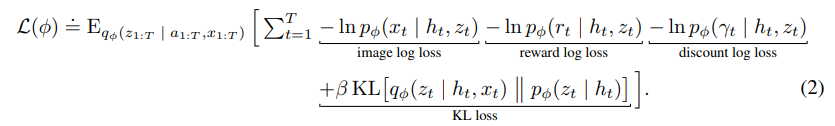 이전논문보다 loss가 훨씬 깔끔해졌다고 생각한다.
이전논문보다 loss가 훨씬 깔끔해졌다고 생각한다.
위와 같다.
KL을 를 설정해줘야 하는데
Atari에서는 을 하였고 continuous control에서는 으로 진행하였다고 한다.
KL balancing
KL을 통해서 prior은 representation(posterior 값)으로 이동하고 representation은 prior을 크게 벗어나지 않게 규제한다.
그러나 이때 prior이 제대로 학습이 되지 않아서 이상한 값을 가지는 상황에서 representation이 규제가 되어 잘 학습되지 않을 수 있는 문제가 발생할 수 있는데
이를 해결하기 위해서 prior과 posterior에 다른 representaion을 사용해서 진행한다.
prior은 , posterior 즉 0.2. 아래와 같이 진행

이렇게 함으로써 정확한 prior을 빠르게 학습할 수 있다.
2.2 BEHAVIOR LEARNING
dreamer은 actor, critic이 오로지 world model을 통해서만 학습이 된다.
그렇기 때문에 world model의 representation에 영향을 많이 받는다.
Imagination MDP
world model학습에 사용한 부터 시작해서 transition predictor 을 이용해서 다음 prior을 예측한다.
horizon은 를 사용했다고 한다.
discount factor은 episode가 끝나는 확률을 감안해서 predict를 조절하게 만든다.
Model components
actor은 stochastic하게 action을 선택하고 ciritc은 deterministic하게 value를 예측한다.
actor과 critic은 imagined state에서 학습을 진행하는데
- actor은 ciritc output을 maximize하게 만들고
- critic은 미래의 reward 합을 정확하게 예측하는 것을 목표로 한다.
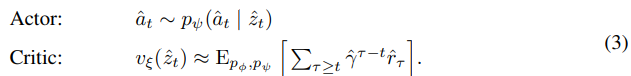 actor과 critic은 위와 같이 각각의 param 묶음으로 구성이 된다.
actor과 critic은 위와 같이 각각의 param 묶음으로 구성이 된다.
actor과 ciritc은 MLP와 ELU로 구성이 된다.
actor은 categorical distribution이고 critic은 determinisitc ouptut을 가진다.
Critic loss function
이전 dreamer v1과 같이 lambda-return을 사용한다.
그런데 수식이 재귀적으로 바뀌었는데
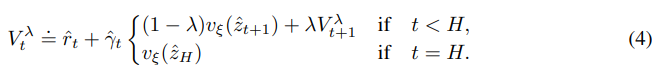 위와 같이 구성이 된다.
위와 같이 구성이 된다.
논문에서 로 설정했다고 한다. 이는 long-horizon target에 집중하기 위함이라고 한다.
어려워 보이는데 의외로 간단하다.
기존 로 구성이 된다.
이를 그대로 사용하지 않고 lambda 비율로 섞는 것인데
인 것이다.
즉 다음 step의 value 예측 값을 이전에 계산한 것을 lambda만큼 유지하면서 진행하는 것이다.
이렇게 weighted average가 된다.
이렇게 reward, discount factor, model_state로부터 lambda return을 구하고
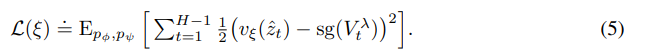 위와 같이 critic의 loss를 설정한다.
위와 같이 critic의 loss를 설정한다.
이때 last time-step(H)에 대한 loss가 없는데 이는 critic과 target이 동일하기 때문
그리고 이때 값을 안정화하기 위해서 stop gradient와 target network를 사용하는데 target network는 critic의 복사본으로 100epoch마다 복사가 된다.
Actor loss function
actor은 미래의 reward를 증가시키는 것이 목표이다.
dreamer v1에서는 간단하게 lambda-return를 미분해서 바로 증가시키는 것으로 활용을 하였는데
lambda return은 actor이 고른 action을 토대로 world model이 state를 예측하면서 진행이 되기 때문에 직접적으로 미분이 가능하다. 이는 기존의 env 대신 world model을 사용하기에 얻을 수 있는 이점이다.
v2에서는 안정성을 위해서 Reinforce 알고리즘과 섞어서 사용을 하였다.
- reinforce는 샘플을 통해 만들어진 action의 확률을 미분해서 진행이 되기에 편향되지 않았지만 분산이 높다.
- straight-through gradient는 바로 gradient를 계산하니까 편향이 되었지만 분산이 낮다.
그리고 entropy regularization term을 추가해서 모델이 robust하게 학습을 할 수 있게 하였다. (entropy를 증가 시키게)
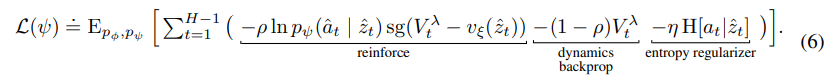 actor의 loss는 위와 같다.
actor의 loss는 위와 같다.
atari의 경우 이고
control problem의 경우 라고 한다.
이때 hyper param을 점점 바꾸는 Anealing으로 성능을 더 향상시킬 수 있지만 논문에서는 간단하게 하기 위해 고정된 값으로 하였다고 한다.
3 EXPERIMENT
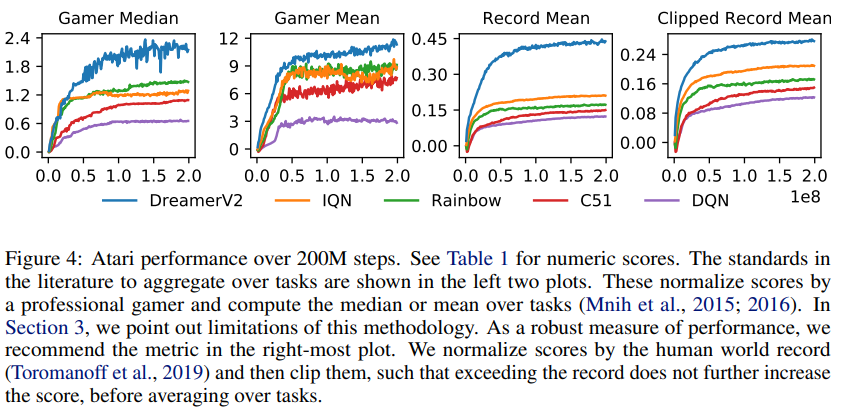
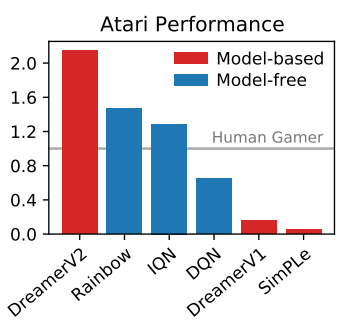
Atari의 55개의 game에 대한 점수인데 dreamer가 다른 model-free를 압도한다.
score의 기준은 사람이 1이다.
55개의 게임이기 때문에 기준을 다양하게 하여서 보았는데
- Gamer Median: agent의 중앙 값들을 나타낸 것.
- Gamer Mean: agent의 평균 값들을 나타낸 것. 몇몇 게임에서 매우 높은 점수를 받아서 높다.(Noise)
- Record Mean: 인간 최고 기록(world record)과 비교해서 평균을 계산한 것
- Clipped Record Mean: 최고기록과 비교를 하는데 clipped된 기록과 비교한 평균 점수. 이때 clipping은 인간의 world record를 넘어선 기록은 더이상 영향을 주지 못하게 하였음.
(확인해보니 특정 몇개의 game에서 world record를 아득히 넘는 경우 존재 예를 들어: UP N Down -> world record 82840, dreamer v2 653662)
이다.
재밌는건 저자들은 reconstruct loss가 meaningful representation을 구축하는데 그다지 큰 도움이 되지 않는다고 가설을 세웠다.
왜냐하면 Atari의 대부분 게임에서 중요한 공, 총알 같은 것들은 1개의 pixel만 차지하기 때문이다.
그러나 dreamerV2는 다른 model-free agent보다 매우 뛰어는 성과를 보였다.
3.2 Ablation study
Dreamer V2가 좋은 성능을 내는 이유를 알아보기 위한 실험.
각각 Dreamer V1과 비교를 하였다.
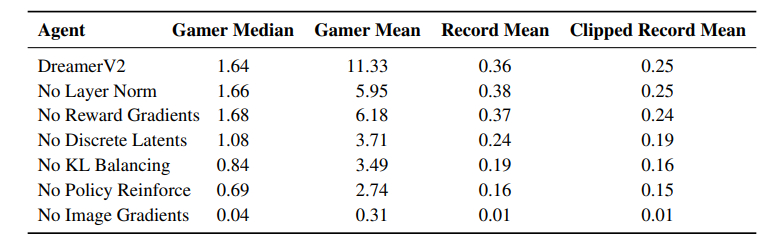
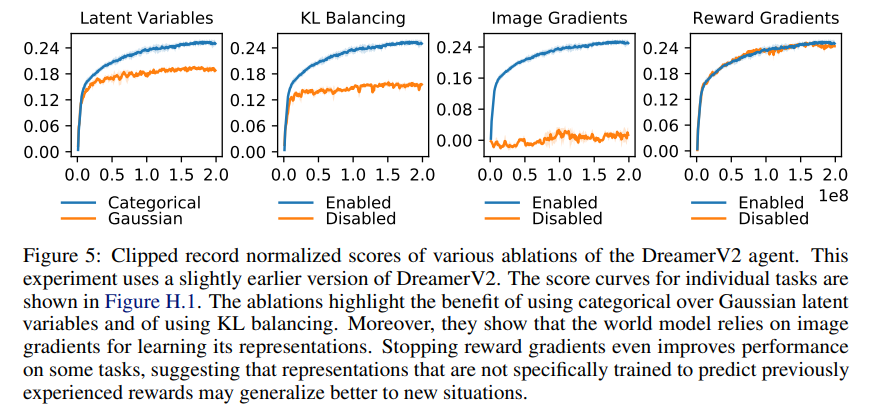 기준은 clipped record이다.
기준은 clipped record이다.
각각 V1에 어떤걸 추가하고 성능을 비교하는 방식.
Categorical latents
categorical latent가 gaussian보다 좋은 성능을 내었는데 이는 저자들도 왜 그런지는 모른다.
저자들이 추측을 하는데
- categorical은 gaussian과는 다르게 posterior을 완벽하게 맞출 수 있음.
- categorical의 희소한 정도가 일반화에 유리할 수 있음.
특정 categorical로 희소하게 제한을 하기 때문에 불필요한 정보가 안들어감. - 직관과는 다르게 categorical이 gaussian보다 최적화가 더 쉬울 수 있음.
straight through gradient가 scaling이 들어가지 않기 때문에 복잡하지 않아서 최적화가 더 쉬울 수 있음. - Atari의 경우 frame이 매끄럽지 않는데 이를 모델링 하기에 이산이 inductive bias를 제공할 수 있음.
출처. 다른 정보를 찾다가 본 그림인데 위 그림과 같이 categorical이 좀 더 세분화한 feature를 합쳐서 보기에 더 표현력이 높아서 정확히 모델링할 수 있다고 한다.
KL balancing
위에서 설명했다시피 prior과 posterior을 비율을 두고 KL을 구하는 식으로 진행을 하는데
매우 차이가 매우 컸다.
Model gradients
Dreamer v1에서도 실험한 내용인데 image의 gradient를 끄면 제대로 학습이 이루어지지 않는다.
반면에 reward를 끄는 것은 의외로 큰 영향을 주지 않았다.
이는 Dreamer V2가 image에 많이 의존을 하고 있다는 것을 알 수 있다.
심지어 reward를 꺼서 성능이 증가한 task도 존재했다.
Policy gradients
위 표를 보면 Dreamer V2에서 policy에 Reinforce gradient를 제외하면 점수가 상당히 감소하였다. 즉 원래의 straight-through 만 미분하는 것은 점수가 상당히 하락한다.
그리고 섞은 것은 특정 game에서 약간의 향상을 보였고 평균 점수가 더 높았다.
구현
