이해한 점, 느낀점
간단하게 이해한 내용을 적어보자면
Dreamer는 환경을 model로 학습하는 것은 기존의 mbrl과 동일한데
agent를 오로지 가상으로 만든 환경에서 상상을 기반으로 학습을 진행한다.(논문에서는 Actor-Critic으로)
이때 상상의 환경(network)에서 actor가 활동을 하기 때문에
reward를 직접적으로 미분을 할 수 있고 이 덕분에 actor가 추가적인 loss를 고려하지 않아도 된다는 이점이 있다.
Abstract
학습된 world model은 agent의 경험을 요약해서 복잡한 행동을 쉽게 학습하게 해준다.
딥러닝을 통해서 고차원의 감각 입력으로부터 world model을 학습하는 것이 가능해지고 있지만, 이를 활용해서 행동을 도출 하는 데에는 다양한 방법이 있다.
이 논문에서는 dreamer를 제시한다.
dreamer는 이미지로부터 만들어낸 상상을 통해서 장기적인 task를 해결하는 강화학습 agent이다.
dreamer는 학습된 world model의 압축된 상태 공간의 상상의 궤적?을 통해 학습된state value 값의 분석적 gradient를 전파 함으로써 행동을 효과적으로 배운다.
이러한 dreamer는 이전의 방법들을 뛰어넘는 매우 뛰어난 성능을 보였다.
1 Introduction
지능적인 agent는 동일한 상황을 두번 다시 마주치지 않는 복잡환 상황에서도 좋은 성능을 얻을 수 있다. 이러한 능력은 상황을 일반화할 수 있는 과거의 경험으로부터 world의 representation을 구축하는 것이 필요하다.
world model은 parametric model을 통해서 agent가 생각하고 있는 세상에 대한 지식을 명시적으로 보여준다. 그리고 이를 통해서 future를 예측할 수 있다.
world model 리뷰
이 논문은 dreamer을 제시한다.
dreamer는 long-horizon behavior를 latent imagination으로부터 학습하는 agent이다. 새로운 actor-critic 알고리즘은 상상 너머의 reward를 고려하면서 신경망을 효율적으로 활용한다.
이를 위해 state value와 action을 학습된 latent space에서 예측을 한다.
위 그림과 같이 구성된다고 한다.
- 기존의 online또는 replay memory로 배우는 actor critic과 다른 점은 world model은 과거의 경험을 보간하고 multi-step return의 analytic gradient(식에서 바로 gradient 계산이 가능한 것)을 제공할 수 있다.
2 CONTROL WITH WORLD MODELS
-
Reinforcement Learning.
visual control 문제를 partially observable Markov decision process(POMDP)로 바꿨다.- time step ,
- actor에 의해서 생성되는 continuous vector-valued action
- 모르는 환경이 만들어내는 high-dim observation, scalar reward 로 구성이 된다.
목표는 expected sum of reward 를 최대화 하는 agent를 개발하는 것이다.
 실제 task는 위와 같다.
실제 task는 위와 같다. -
Agent component
imagination으로부터 학습하는 agent의 classic한 구성요소는- dynamic 학습
- behavior을 학습
- environment와 interaction이다.
dreamer의 경우 behavior은 world model의 latent space에서 이론적인 trajectory를 예측함으로써 학습한다.
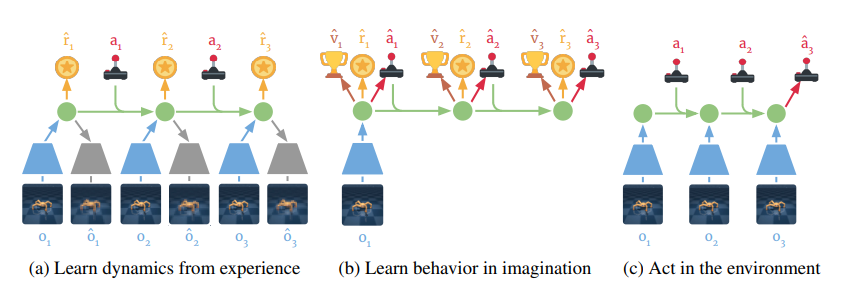
이 과정은 아래 그림과 같다.
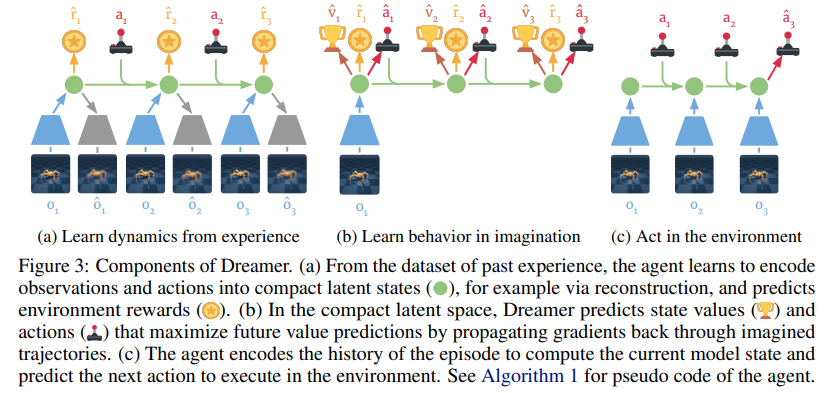
과정은 3가지로 구성이 되는데- 과거 경험으로부터 latent dynamics model을 학습한다. 이를 통해 미래의 reward를 action과 past observation으로부터 예측한다. 이 부분에서 world model의 학습 목표가 dreamer에 통합될 수 있다.
- action과 value model을 예측된 latent trajectory에서 학습한다. 가치 모델은 imagined reward를 가지고 벨만 방정식을 최적화 하고 action model은 가치 추정치의 gradient를 neural network dynamics를 통해 전파해서 학습한다.
- 학습한 action model을 real world에서 실행해서 새로운 경험을 수집한다.
-
Latent dynamic
dreamer은 3가지 구성요소로 구성된 latent dynamic model을 사용한다.- representation model: observation과 action을 encode해서 state를 생성한다.
- transition model: state를 유발하는 해당 관측 값 를 보지 않고도 미래의 model state를 예측한다.
- reward model: 모델 상태를 기반으로 reward를 예측
위에서 실제 환경에서 샘플을 생성하는 분포는 이고 상상을 가능하게 하는 근사 분포는 를 사용하였다. 또한 실제 observation은 이고 model이 만드는 compact state는 이다.
transition model은 해당 이미지들을 관찰하거나 상상하지 않고도 바로 latent space에서 예측할 수 있게 만들어준다. -> 이 부분이 기존 world model과 다른 것 같다.
이러한 모델은 갈만필터, latent state space model 등과 비슷해 보이지만 action에 조건화 되어 있고 보상을 예측하기 때문에 agent가 환경에서 실행하지 않고도 잠재적인 action sequence의 결과를 예측할 수 있다.
3 LEARNING BEHAVIORS BY LATENT IMAGINATION
이 부분을 보면 구체적인 내용을 알 수있다.
 위는 알고리즘 의사 코드이다.
위는 알고리즘 의사 코드이다.
간단하게 설명하자면
1. real environment로부터 S개의 random episode를 담는다.
2. 이를 활용해서 dynamics를 학습한다. 구체적으로는 Representation, Transition, Reward 등 에 관련된 param들을 더 잘 예측할 수 있도록 update 한다.
3. 이렇게 만든 world model을 이용해서 imagination을 통해 action, value를 학습한다.
4. 학습한 actor을 활용해서 실제 environment에서 data를 모은다.
5. 수렴할 때까지 2~4 반복
Action and value models
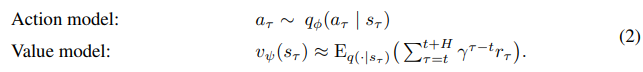 각 모델은 위와 같이 구성이 된다.
각 모델은 위와 같이 구성이 된다.
dreamer는 actor-critic 방법으로 behavior을 학습하는데 trajectory를 finite horizon 까지 학습한다.
이때 action이 연속된 값일 때 미분이 가능하게하기 위해서 reparameterized trick을 사용하는데 이는 VAE에 적용된 것과 비슷하다고 한다.
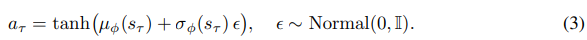 간단하게 sampling을 하게 되면 미분을 할 수 없으니 평균과 분산을 출력한 다음 gaussian noise를 이용해서 구성하면 미분이 가능해진다.
간단하게 sampling을 하게 되면 미분을 할 수 없으니 평균과 분산을 출력한 다음 gaussian noise를 이용해서 구성하면 미분이 가능해진다.
Value estimation
imagined trajectories 에서 value를 계산하는 방법은 여러가지가 있다.
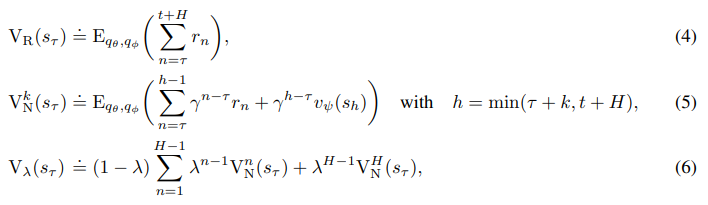 위 3가지 인데
위 3가지 인데
- 그냥 몬테카를로 방법으로 까지 reward를 더한 평균 값이다.
- k-step 방법으로 부터 h-1 step까지 진행한 다음 그 다음 step은 value model을이용한다.
- 위 k-step을 1~H step까지 가중치를 넣어서 평균낸 것이다.
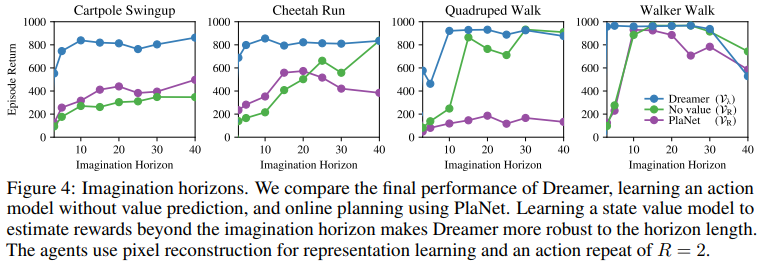
3번째 방법으로 dreamer를 학습하기 때문에 더 긴 long-horizon task에서도 좋은 행동을 할 수 있다고 한다.
Learning objective
학습 목표는 아래와 같다.
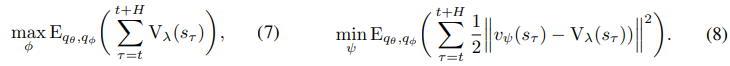 왼쪽은 actor의 목표이고 오른쪽은 critic의 목표이다.
왼쪽은 actor의 목표이고 오른쪽은 critic의 목표이다.
여기에서 엄청나게 재밌는 게 나오는데 actor을 보면 단순하게 계산한 value를 다 더하고 이를 maximization하는 것이 목표이다.
그냥 이게 왜? 라고 할 수 있겠지만 재밌는건 이 value-lambda가 미분이 가능하다.
계산된 value-lambda는 reward와 value 예측 모델로 구성이 되어 있는데 이는 imagined state에 의존적이고 그 imagined state는 actor의 action에 의존적이기 때문이다.
즉 바로 value-lambda를 미분해서
로 업데이트가 된다.
만약 action이 연속된 값이 아니라서 이전의 reparameterized trick등을 이용한 미분이 불가능하다면 straight-through gradient를 사용한다고 한다.
value는 그냥 imagine 예측 값이랑 value model 값이랑 MSE 처럼 업데이트 한다.
이때 world model은 학습되지 않고 fix되어있다.
만약 task가 early termination이 가능한 경우에 world model은 또한 discount factor도 예측한다. 즉 termination에 가까우면 점점 0에 가깝게 예측하는 것이다.
이를 곱셈으로 중첩해서 위 objective의 timestep t일 때의 weight를 만들어 주는 것이다.
즉 마지막에 가까울수록 영향력이 점점 작아질 것이다. 이는 조기종료를 막아 다양한 탐색을 가능하게 만들어준다.
Comparison to actor critic methods
Reinforce gradient를 사용하는 A3C나 PPO와의 가장 큰 차이는 agent가 value model을 이용해서 gradient를 사용하는 것으로생각된다.
또한 전이를 이용한 gradient 또한 사용한다.
4 LEARNING LATENT DYNAMICS
compact latent space에서 미래를 예측할 수 있는 latent dynamics model에 집중하였다.
learning representation의 여러 접근 방법을 reward prediction, image reconstruction, contrastive estimation의 방법으로 리뷰하였다.
Reward prediction
Latent imagination은 representation model , transition model , reward model 이 필요한데 이것들은 단순하게 과거의 관측치와 action에서 주어진 reward를 예측하는 것으로 학습이 가능하다.
그러니까 image reconstruction 없이 reward를 예측하는 것 만으로도 충분히 Latent imagination이 가능하다는 이야기
실제로 large하고 diverse한 dataset에서 이러한 Reward에 대한 representation은 control task를 풀기에 충분하다.
하지만 유한하고 특히 reward가 sparse하면 reward와 관련된 observation을 할습하는 것은 world model을 improve할 수도 있다.
Reconstruction
논문저자가 이전에 만들었던 PlaNet의 구조로 world model을 묘사하였다.
PlaNet은 reconstruction loss와 state에 대해서 encoder, model의 KL loss가 합쳐진 구조였다. 아래 그림은 Planet의 observation reconstruction에 대한 loss인데 reward도 비슷하다.

dreamer은 다음 그림과 같은데
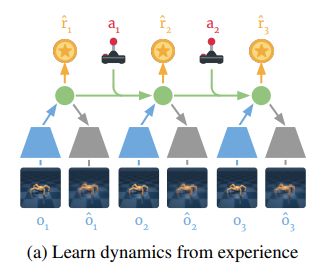
world model은 다음과 같이 구성이 된다.
- Representation model: ,
- Observation model:
- Reward model:
- Transition model: ,
Loss는 아래와 같다.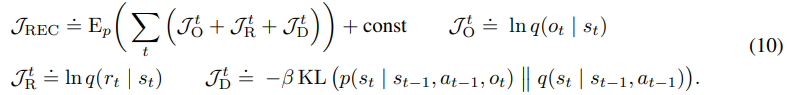 어려워 보이지만 사실상 위의 PlaNet의 loss와 동일하다.
어려워 보이지만 사실상 위의 PlaNet의 loss와 동일하다.
state로부터 observation, reward를 잘 복구할 수 있도록 하고 imagination에서 사용되는 Transition model과 observation으로부터 만드는 Representation model의 차이가 없도록 한다.
이후 transition model은 recurrent state space model(RSSM)으로 구현을 하였고 representation model은 RSSM+CNN으로 구현하였다고 한다.
이후 복구하는 observation model은 transposed CNN, reward model은 dense network로 구현하였다고 한다.
combine된 param 는 SGD로 학습이 된다고 한다.
 실제 학습이 되면 위와 같이 거의 잘 예측하는 것을 알 수 있다.
실제 학습이 되면 위와 같이 거의 잘 예측하는 것을 알 수 있다.
Contrastive estimation
간단하게 지금 우리는 Observation model을 통해서 state to image의 학습을 진행하는데
이를 반대로 할 수 있다.
state model: 를 사용해서 image to state로 학습이 가능하다.
그런데 이전의 state to image의 경우 state에서 복구하는 image는 정해져있다.
하지만 image to state에서 만드는 state는 어떻게 다른 state들과 다르게 만들지 유동적이다.
이 때문에 우리가 기존에 image 분야에서 사용하던 contrastive term을 추가할 수 있는데
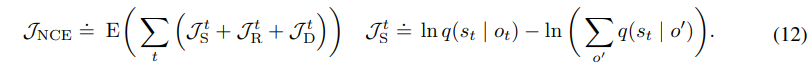 위 그림과 같다.
위 그림과 같다.
는 기존과 같이 state를 image로부터 predictable하게 만드는 term이고
은 전체 batch 에서 state를 predictable할 확률을 줄이게 된다(-니까 내부를 감소시켜야 하기 때문)
state model은 CNN으로 구현하였고 combined param 와 결합해서 진행.
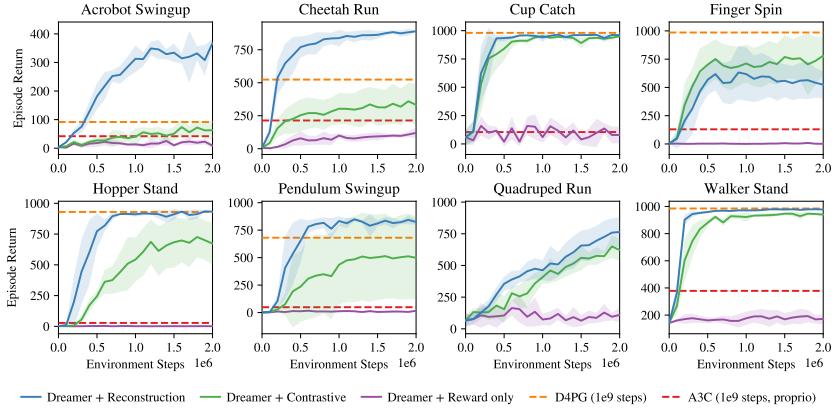 위 그림이 실험 결과인데 Reconstruction Dreamer가 그냥 제일 좋고 Constrastive를 접목한 것은 대부분 안좋았으나 Finget spin에서는 좋았다.
위 그림이 실험 결과인데 Reconstruction Dreamer가 그냥 제일 좋고 Constrastive를 접목한 것은 대부분 안좋았으나 Finget spin에서는 좋았다.
이는 task가 image분야와 비슷해서 그렇다는 듯하다.
이때 reward만 사용하는 것은 매우 성능이 떨어졌는데 sparse한 reward에서는 reward를 제대로 정보를 담을 수 없어 image가 좋은 정보가 되는 듯하다.
위 결과가 보여주는 중요한 뜻은 representation을 잘 학습하는 것은 Dreamer의 성능에 직접적으로 좋은 효과를 준다는 것이다.
구현
