Machine Learning
1.[ML] 지도학습, 비지도학습, 강화학습
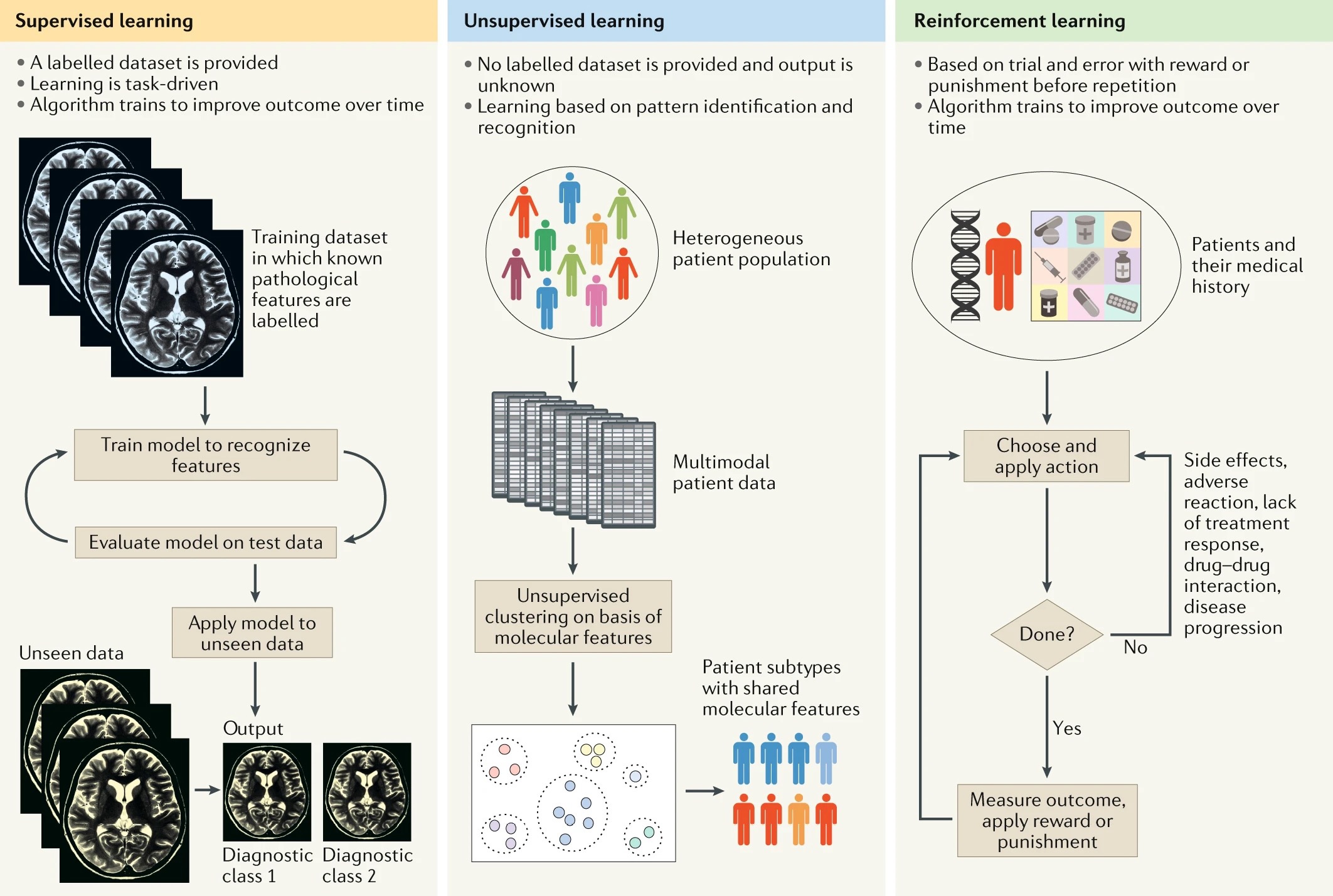
머신러닝 시스템의 종류 1. 지도학습 (Supervised Learning) 훈련 데이터에 레이블(label)이라는 답이 포함되어있는 모델 주어진 input으로부터 label을 예측하는 일을 학습 분류(classification) : 전형적인 지도학습 회귀(Regr
2.[ML] Training Set, Validation Set, Test Set
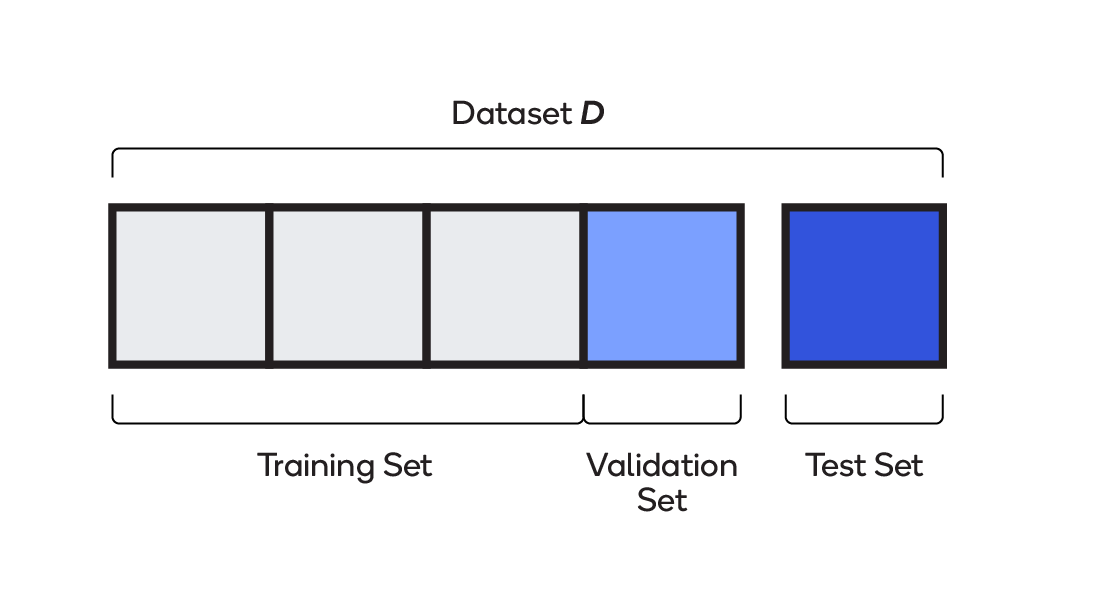
모델을 학습하는데 사용하는 Dataset모델의 parameter들을 업데이트 할 때 사용학습이 끝난 모델을 검증 하는데 사용하는 Dataset모델의 성능을 평가하는데 사용다양한 parameter와 모델을 사용해보면서 validation set으로 가장 좋은 모델을 선택
3.[ML] K-fold Cross Validation (K-겹 교차검증)
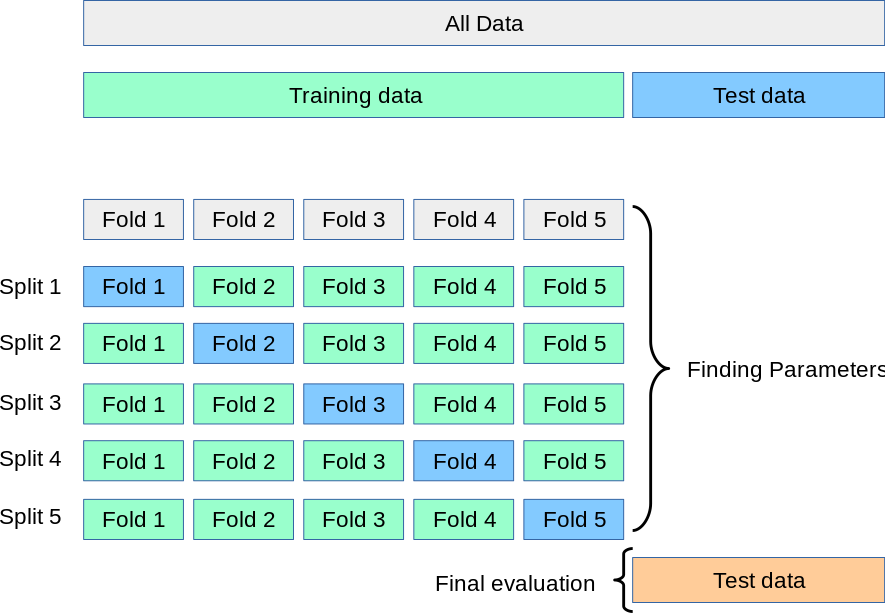
모델을 학습시킬 때, 데이터셋을 크게 Training Set과 Test Set으로 나누어 수행Training Set으로 모델 학습, Test Set으로 모델 검증이렇게 데이터셋을 나눌 경우 Training Set에서는 정확도가 높지만, Test Set에서는 정확도가 높
4.[ML] Overfitting, Underfitting
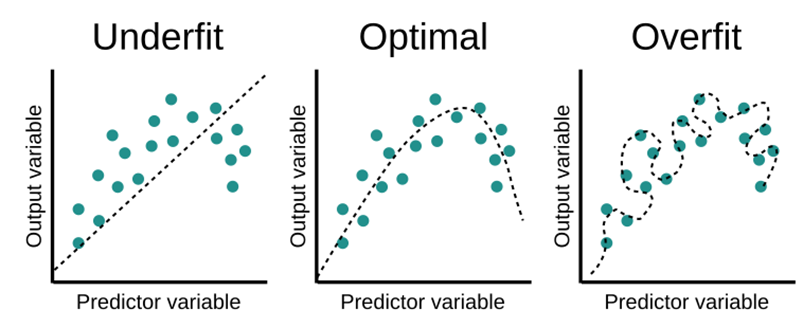
너무 과도하게 데이터 모델을 학습한 경우Training Data에는 잘 맞지만, Test Data에는 잘 맞지 않는 것복잡한 모델이거나 데이터가 적을수록 과적합(overfitting)이 일어나기 쉬움과적합(overfitting)의 반대개념Training Data도 학습
5.[ML] Objective Function (목적함수) / Loss Function (손실함수) / Cost Function (비용함수)

Objective Function (목적함수) & Loss Function (손실함수) & Cost Function (비용함수) 기계가 스스로 모델의 성능 향상 정도를 판단하기 위해서 사용되는 함수 학습을 통해 최적화(optimization)시키려는 함수 일반적으로
6.[ML] Grdient Descent (경사하강법)
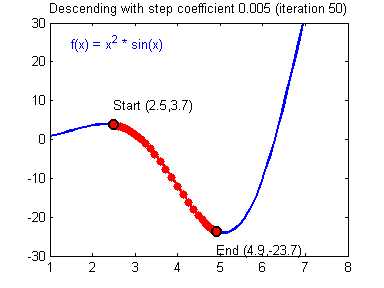
딥러닝 알고리즘을 학습할 때 사용되는 최적화 방법(optimizer)중 하나Loss Function의 크기를 최소화시키는 파라미터를 찾는 것Loss Function의 변화에 따라 가중치(w)와 편향(b)를 업데이트해야 할 때, 최적의 가중치를 찾는 방법으로 사용됨함수의
7.[ML] Epoch, Iteration, Batch Size 개념
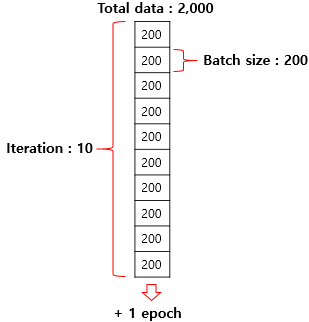
모델 학습 중 parameter를 업데이트할 때 사용할 데이터의 개수Batch size만큼의 데이터를 활용해 loss function을 계산한 후 parameter update전체 데이터셋에 대한 Batch의 개수전체 데이터셋을 학습한 횟수Training Data를 모
8.[ML] 분류 성능 평가
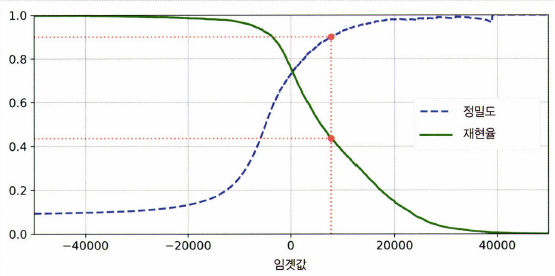
1. Accuracy (정확도) $$ Accuracy = \frac{TP+TN} {TP+TN+FP+FN}$$ 분류 모델이 전체 데이터셋 중에서 정답을 맞춘 비율을 보여주는 단순 지표 만약 데이터가 불균형하다면 (ex. 500개의 데이터 중 490개 데이터 레이블이 이
9.[ML] Binary Classification 실습코드
핸즈온 머신러닝 2판 Ch03 분류
10.[ML] Multiclass Classifier (다중 분류)
둘 이상의 class 구별SGD Classifier, Randomforest Classifier, Naive Bayes Classifier는 여러 개의 class를 직접 처리 가능Logistic Regression, Support Vecter Machine Classi