Goal
본 시리즈는 시계열 데이터의 이상을 탐지하기 위한 딥러닝 모델 학습과정에 대해 설명한다.
[1] 개요
대부분의 설비(에스컬레이터, 승강기 등)의 고장은 경제적 손실을 불러일으키고 치명적인 인명 피해를 발생시킬 수 있다. 그렇기 때문에 설비의 고장을 사전에 막는 것은 매우 중요한 문제이다.
설비의 고장을 막기 위한 방법으로 주기적인 점검, 통계 기법을 사용한 이상 탐지, 인공지능을 사용한 이상탐지 등 여러 방법이 있는데, 그 중 인공지능 중 딥러닝 기법을 사용한 설비의 이상탐지(Anomaly Detection) 방법을 다뤄보고자 한다.
이상 탐지란 ??
- 이상 탐지는 설비의 데이터를 통해 이상 패턴(이상징후), 개체 등을 찾아내는 것을 의미한다.
- 아래와 같은 시계열 데이터가 발생하는 설비에서 특정 부품의 이상이 발생하게 되면 그림의 오른쪽 부분과 같이 이상 패턴을 발생하게 되는데, 이런 이상 패턴을 즉각적으로 잡아서 고장을 사전에 방지하는 것이다.
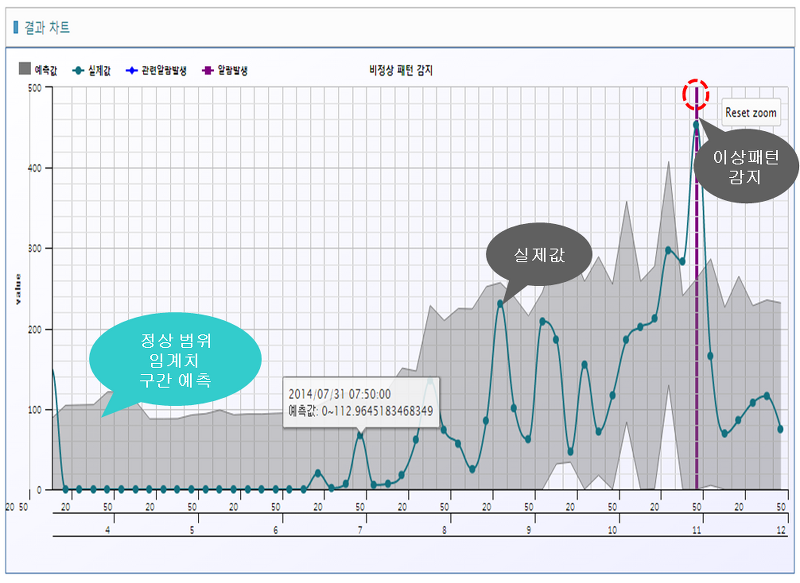
출처 : https://blog.lgcns.com/797?category=515147
알고리즘 선정
이상탐지를 위한 기법으로 통계 기법, 머신러닝, 딥러닝등 여러가지 기법이 있는데, 최근 딥러닝을 사용한 이상 탐지 기법이 활발하게 연구되고 있다.
딥러닝 기법을 사용한 이상 탐지 기법은 학습 데이터에 비정상 데이터 포함 유무와 결과 레이블의 존재 유무에 따라 크게 지도학습, 비지도학습으로 나뉘게 된다. (자세한 내용은 아래 그림 참고)
지도학습 : 정상 데이터 + 비정상 데이터 + 정답 존재
비지도학습 : 정상 데이터 + 정답 존재하지 않음 => 특징을 스스로 학습한다.
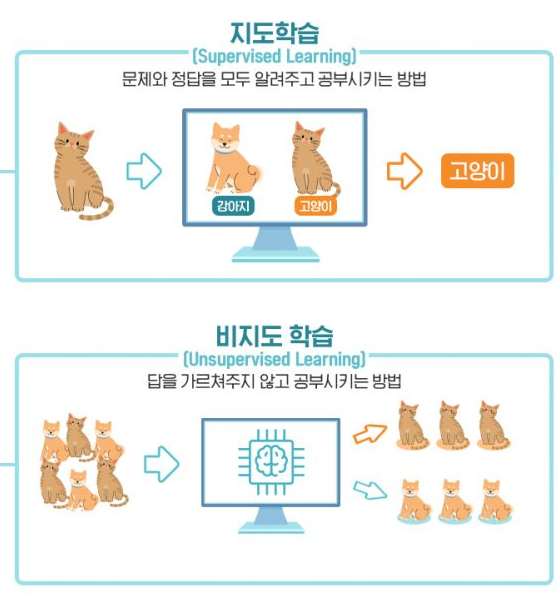
출처 : https://live.lge.co.kr/live_with_ai_01/
지도학습에는 CNN과 같은 알고리즘이 존재하고, 비지도 학습에는 Autoencoder, GAN과 같은 알고리즘이 존재한다.
지도학습이 비지도학습에 비해 학습된 모델의 정확도가 높으나 아래와 같은 단점이 있어서 비지도 학습 분야가 비교적 활발히 연구되고 있다.
1번. 비정상 Sample을 구하기 어렵다.
2번. 새로운 이상패턴이 발생하게되면 새로 학습을 진행해야 한다.
특히 에스컬레이터,승강기 등과 같은 설비의 경우 비정상 데이터를 구하기 매우 어렵기 때문에 본 포스팅에서는 비지도 학습 기법 중 LSTM Autoencoder(이하 AE) 라는 알고리즘을 사용하게 됐다.
[2] LSTM AE
LSTM AE에 대해 알기 전에 Autoencoder에 대한 사전 지식이 필요하다.
Autoencoder
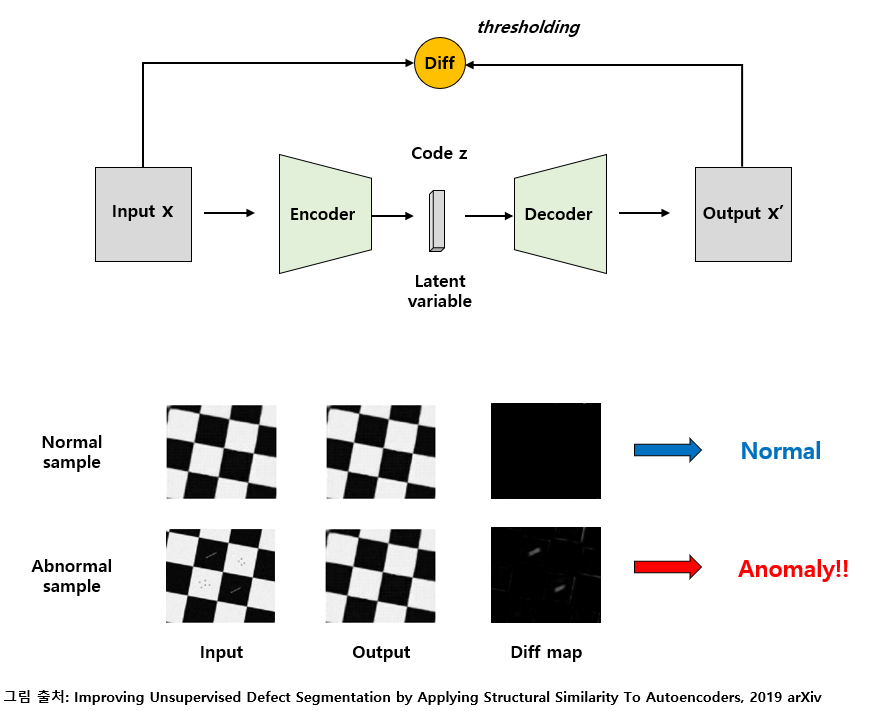
오토인코더는 입력된 데이터를 재구성(복원)해내는 기능을 가진 알고리즘이다.
즉, 입력 데이터인 정상 데이터에 대한 특징을 학습하고 학습된 모델에 데이터를 집어 넣었을 때 재구성한 결과와 학습된 정상 특징과의 차이점을 비교해 이상 여부를 판단하게 된다.
LSTM AE란 ?
설비의 시계열 데이터는 시간 흐름에 영향을 받게 된다.
예를 들면, 에스컬레이터 설비의 체인 고장은 어느 한 시점에 갑자기 고장나지 않는다. 체인의 부속품의 노후 등과 같이 오랜 시간동안 데미지가 누적되다 고장이 나는 것이다.
그렇기 때문에, 시계열 데이터의 고장 진단을 위해서는 데이터의 시간 흐름을 고려해야 좋은 성능의 모델을 만들 수 있다.
본 포스팅에서는 이런 시간적 흐름을 고려하기 위해 Sequence 데이터를 다루는 LSTM과 정상 데이터의 특징을 학습하는 Autoencoder를 섞은 LSTM AE 알고리즘을 사용하게 됐다.
LSTM AE의 구조는 Autoencoder 네트워크의 셀을 LSTM 셀로 대체한 것으로 자세한 구조는 아래와 같다.
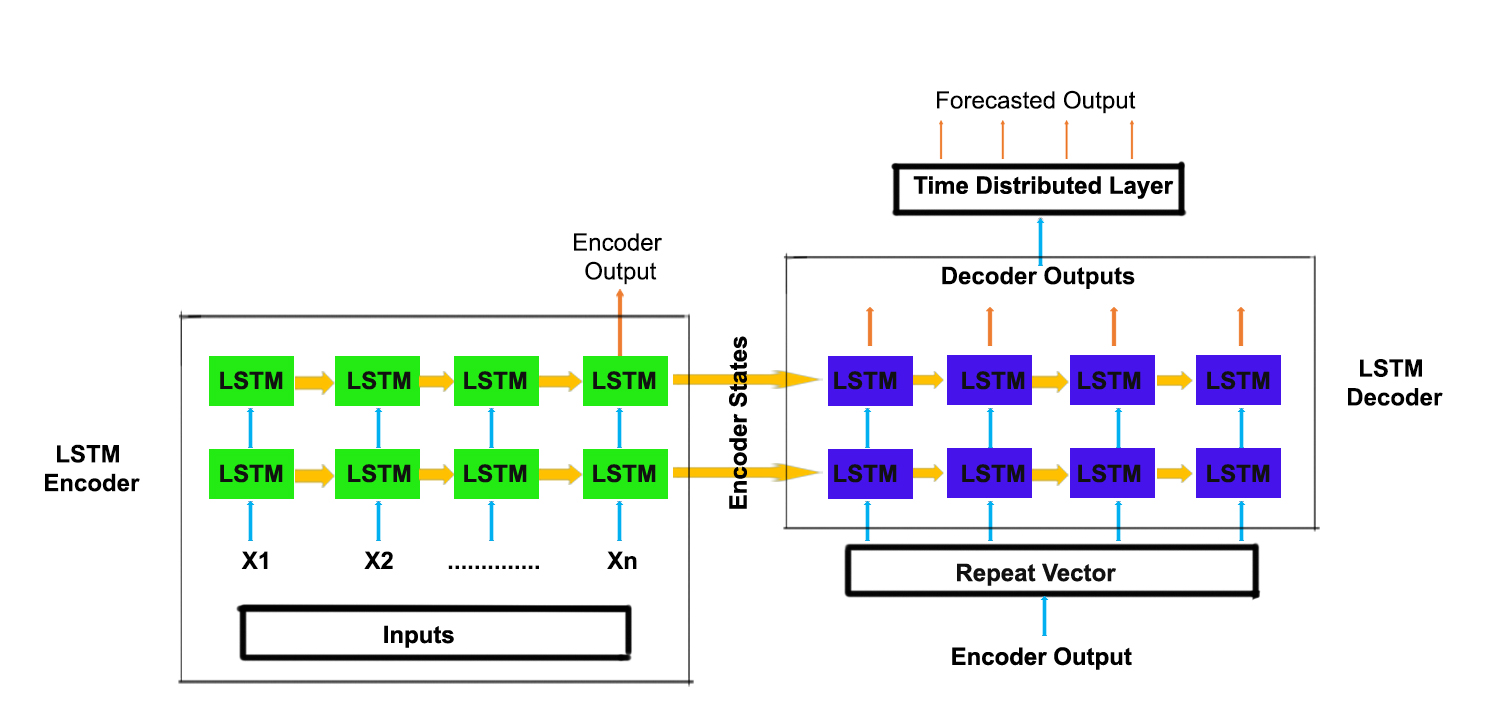
[3] LSTM AE를 사용한 이상탐지 방법
정상 데이터로 학습한 LSTM AE 모델의 이상탐지 흐름은 아래와 같다.
(1) 이상 데이터(설비의 이상 소음/진동 등)이 입력된다.
(2) LSTM AE가 이상 데이터를 재구성한다.
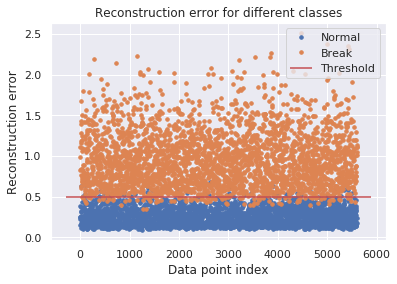
=> 이 때 LSTM AE는 정상 데이터의 특징을 학습했기 때문에, 이상 데이터가 입력됐을 때 재구성 오류(Reconstruction Error)가 정상 데이터를 입력했을 때 보다 크게 발생한다
(3) 재구성 오류를 사전에 정의한 Threshold(임계값)과 비교하여 임계값 초과 시 이상 데이터라고 판단한다.
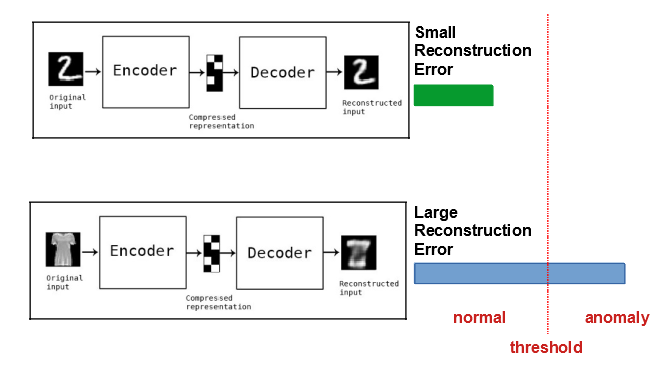
다음 포스팅에는 LSTM AE 모델을 학습하기 위해 에스컬레이터 데이터를 전처리하는 과정을 다룬다.
