Multiclass Classification이란 무엇일까?
Target이 3개 이상인 경우이다.
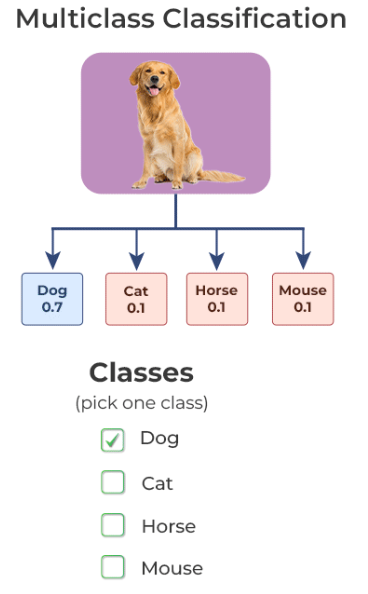
최근 AI가 많은 관심을 받고 있기 때문에, Multiclass Classification에 대한 자세한 내용들이 여러 블로그에 기술되어 있으니 내용을 기술하지 않으려고 한다.
코드 여행을 떠나보자.
Multiclass Classfication CODE
# main.py
import torch
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
print(DEVICE)코드 작성 전에 DEVICE를 꼭 확인해보자. 우리가 앞으로 나아갈 여행에서 가장 필수품은 CUDA이다. CUDA가 출력되지 않는다면 GPU를 먼저 연동시키자.
# main.py
from torchvision import datasets, transforms
train_transform = transforms.ToTensor()
test_transform = transforms.ToTensor()
train_DS = datasets.STL10(root='원하는 경로', split='train', download=True, transform=train_transform
test_DS = datasets.STL10(root='원하는 경로', split='test', download=True, transform=test_transform)
여기서 transform에 대한 개념을 정확히 알아야 한다. transform은 그냥 해주는 것이 아니다.
transforms.ToTensor()의 역할
- (row, column, channel)로 되어 있는 이미지를 (channel, row, column)형태로 바꿔준다.
- Tensor 형태로 바꿔준다.
- 이미지의 픽셀 값을 0 ~ 1 사이로 바꿔준다. (255로 나눠져서 normalize를 해준다고 생각하면 된다.)
하나의 코드에 여러 과정이 들어가 있다.
다음은 좀 생소할 수도 있는데, hyperparameter를 코드에 작성하는 것보다 yaml파일에 관리하여 좀더 유지보수를 쉽게하는 방법을 알아두는 것이 좋다.
# hyperparameter.yaml
TRAIN_RATIO : 0.8
BATCH_SIZE : 64
EPOCH : 1000
.
.
.이처럼 관리해주면 hyperparameter 버전 관리에 용이해 진다. yaml 파일을 불러오는 건 main.py에 불러오는 건 어렵지 않다.
# main.py
import yaml
with open('hyperparameter.yaml') as f
params = yaml.safe_load(f)
TRAIN_RATIO = params['TRAIN_RATIO']
BATCH_SIZE = params['BATCH_SIZE]
EPOCH = params['EPOCH]
print(f"train_ration : {TRAIN_RATIO}",
f"epoch : {EPOCH}",
f"BATCH_SIZE : {BATCH_SIZE}")항상 출력하라.
pytorch에서는 random_split이라는 메소드를 사용해서 학습 데이터셋을 쉽게 train, valid로 나눌 수 있게 해준다.
그러기 위해선 몇가지 방법을 사용해야 한다.
#main.py
NoT = int(len(train_DS) * TRAIN_RATIO)
NoV = len(train_DS) - NoTSTL10 데이터를 살펴보면 train_DS는 총 5000개의 데이터셋을 가지고 있다. 여기서 중요한 점은 데이터가 아닌 '데이터셋에 집중'하라.
train_DS는 단순히 이미지 5000장만 갖고 있는 것이 아니다. mapping되는 라벨값도 같이 갖고 있다.
즉, (image, label) 형식을 갖는다.
변수 NoT 값을 구하는데에 있어 int로 형변환을 한 것은 TRAIN_RATIO가 float 형식이기 때문에, int * float의 출력은 float이 나온다는 것을 기억하라.
# main.py
train_DS, valid_DS = torch.utils.data.random_split(train_DS, [NoT, NoV])NoT = 4000, NoV = 1000이기 때문에, train_DS에는 4000개의 데이터셋이 valid_DS에는 1000개의 데이터셋이 각각 할당된다.
데이터를 준비하는 과정은 여기서 끝이 아니다. DataLoader가 남아있다.
# main.py
train_DL = torch.utils.data.DataLoader(train_DS, batch_size=BATCH_SIZE, shuffle=True)
valid_DL = torch.utils.data.DataLoader(valid_DS, batch_size=BATCH_SIZE, shuffle=True)
test_DL = torch.utils.data.DataLoader(test_DS, batch_size=BATCH_SIZE, shuffle=False)왜 굳이 DataLoader를 사용하는 걸까? 위의 train_DS, valid_DS, test_DS로 사용하면 안될까? 된다. 안될건 없다. 다만 이미지의 갯수가 많거나 이미지의 크기가 커지면 커질수록 불가능하다는 것을 알 것이다.
하드웨어를 보면 RAM과 GPU가 갖는 RAM이 있다. 일정 메모리를 넘어가게 되면 OOM(Out Of Memory)라는 문장이 뜨며 컴퓨터가 다운되거나 학습이 중단되는 상황이 발생하는데, 이를 방지하기 위해 사용하는 것이 DataLoader이다.
전체 이미지를 한번에 학습하는 것이 아니라 위에 yaml 파일의 BATCH_SIZE라는 변수에 할당한 값만큼 데이터셋의 갯수를 가져와 학습한다. BATCH_SIZE=64 라고 작성했다면 64개의 train dataset을 가져오는 것이다.
학습할 데이터 셋은 준비됐으니 이제 모델을 설계해보자.
# model.py
import torch
from torch import nn
class CNN(nn.Module):
def __init__(self): # 인스턴스 메소드,
super().__init__() # 부모 클래스의 __init__ 호출
self.layer1 = nn.Sequential(nn.Conv2d(3, 32, 3, padding=1),
nn.BatchNorm2d(32)
nn.ReLU())
self.maxpool1 = nn.Maxpool(kernel_size=2)
self.layer2 = nn.Sequential(nn.Conv2d(32, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU())
self.maxpool2 = nn.Maxpool(kernel_size=2)
self.layer3 = nn.Sequential(nn.Conv2d(128, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU())
self.avgpool1 = nn.AvgPool2d(kernel_size=2)
self.layer4 = nn.Sequentail(nn.Conv2d(256, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU())
self.avgpoo2 = nn.AvgPool2d(kernel_size=2)
self.fc = nn.Linear(512*6*6, 10)
def forward(self, x):
x = self.layer1(x)
x = self.maxpool1(x)
x = self.layer2(x)
x = self.maxpool2(x)
x = self.layer3(x)
x = self.avgpool1(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
model = CNN()
u_input = torch.randn(32, 3, 96, 96)
print(model(u_input).shape)간단한 CNN모델을 완성했다. 모델을 설계하는데에는 그리 어렵지 않은데, 코드하나씩 확인해보자.
nn.Sequential()은 하나의 블록으로 만든다고 생각하라.
torch.flatten(x, start_dim=1)을 하는 이유에 대해서 정확히 알아야 한다. 우리가 하는 task는 Multiclass Classification이다. 이 분류라는 task를 진행하기 위해서는 결국 마지막 출력단은 Fully connected로 모두 연결하여 일렬로 쭉 세워야 한다. 그 과정을 하기 위해 해당 코드를 사용한다.
start_dim=1을 반드시 넣어야 하는 이유는 torch.flatten(x, start_dim=1)에 들어가기 전의 x의 shape는 (32, 512, 6, 6)이기 때문이다. 여기서 32는 batch_size를 의미하며 512는 channel, 6은 각각 row와 column을 의미한다. Batch_size의 갯수는 특징과는 전혀 관련이 없으므로 dimension은 1부터 시작하여 channel, row, column만 flatten을 하여야 유의미한 결과값을 얻을 수 있다.
내용이 길어지니 2편에서 이어쓰도록 하겠다.
