프로그래머스
1.프로그래머스 인공지능 데브코스

본론으로 들어가기 전에 좋은 기회로 프로그래머스에서 진행하는 인공지능 데브코스 6기에 합격하게 되었어요.😃그런데 개인 블로그가 필요하다고 해서 교육 받는 것도 정리할 겸 개발 블로그를 시작하게 되었어요. 부족하지만 점차 발전해가는 모습 지켜봐주세요👊👊첫째날은 OT
2.📕Week1 day2(14-16)

큐(queue)는 데이터 원소를 한 줄로 늘어세우는 자료 구조📒큐 또한 선형구조라는 점에서 스택과 유사하지만 반대의 성질을 가지고 있습니다. 어느 시점에서 큐에 들어 있는 데이터 원소를 꺼내면 큐에 들어 있는 원소들 중 가장 먼저 넣었던 것이 꺼내집니다. 따라서 큐를
3.📕Week1 day2(17-19)

트리(tree)는 이차원의 자료구조로 노드와 엣지를 이용하여 데이터의 배치형태를 추상화한 자료구조이다.모든 노드의 차수가 2 이하인 트리입니다.\*재귀적으로 정의할 수 있음size: 노드의 수 depth 트리의 깊이 순회(traversal) \-깊이 우선 순회 1
4.📕Week1 day2(20-21)

모든 노드에 대해서 왼쪽 서브트리에 있는 데이터는 모두 현재 노드의 값보다 작고 오른쪽은 모두 큰 성질을 만족하는 이진트리.이진탐색과 유사한 점이 많아 이진탐색과 비교해보았습니다.장점 : 데이터 원소의 추가, 삭제가 용이하다.단점 : 공간 소요가 큼데이터 표현- 각 노
5.📕Week1 day2(22-23)

📒힙은 이진트리의 한 종류로 루트노드가 언제나 최댓값또는 최솟값을 가집니다.(최대 힙, 최소 힙 이라고 한다.) 그리고 트리는 완전이진트리여야합니다.여기서는 최대 힙만 구현해 보았습니다.최대 힙을 구현하기 전에 성질과 특징에 대해 얘기하고자 합니다.루트 노드가 항상
6.📕Week1 day3(코테 연습)

해시 테이블은 키(key)와 값(value)으로 구성된 자료 구조다.프로그래머스 코딩테스트 연습에 있는 문제입니다.https://school.programmers.co.kr/learn/courses/30/lessons/42576그리디알고리즘은 알고리즘의 각 단
7.📕Week1 day4(코테 연습)

힙은 이진트리의 한 종류로 루트노드가 언제나 최댓값또는 최솟값을 가집니다.day2에서 배운 힙을 이용한 코딩문제에요!매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌
8.📕Week2 day1(웹스크래핑 기초)

requests는 Python을 이용해서 간단히 HTTP 통신을 진행할 수 있는 라이브러리입니다.GET : 정보를 달라고 요청한다.웹 스크래핑: 특정한 목적으로 특정 웹 페이지에서 데이터를 추출하는 것웹 크롤링: URL을 타고다니며 반복적으로 데이터를 가져오는 과정ro
9.📕Week2 day2(웹스크래핑 기초)

HTML 코드를 분석해주는, HTML Parser찾아온 데이터들은 모두 객체이므로, 저희가 익숙한 방식대로 데이터를 추출할 수 있습니다.태그는 자신의 이름 뿐만 아니라 고유한 속성 또한 가질 수 있습니다.이 중에서 id와 class는 Locator로서, 특정 태그를 지
10.📕Week2 day3(웹스크래핑 기초)

selenium은 Python을 이용해서 웹 브라우저를 조작할 수 있는 자동화 프레임워크입니다.Web Driver웹 브라우저와 연동을 위해서는 WebDriver가 필요합니다.WebDriver는 웹 브라우저를 제어할 수 있는 자동화 프레임워크입니다.그 다음 불러온 모듈
11.📕Week2 day4(웹스크래핑 기초)

seaborn은 파이썬의 데이터 시각화 라이브러리입니다. 이를 기반으로 수려한 그래프를 그릴 수 있습니다.꺾은선 그래프(Line Plot)두 변수의 값에 따른 추이를 선으로 이은 그래프입니다. .lineplot()를 이용해서 이를 그릴 수 있습니다.위의 명령어를 작성하
12.📕Week2 day5(인공지능 수학)

가우스 소거법가우스 소거법은 임의의 M\*n선형시스템의 해를 구하는 가장 대표적인 방법이다.두단계로 수행1.Forward elimination(전방소거법): 주어진 선형 시스템을 아래로 갈수록 더 단순한 혀애의 선형방정식을 가지도록 변형한다.2.back_substitu
13.📕Week3 day1(Numpy)

행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리이다.먼저 numpy라이브러리를 import한다.1.벡터와 스칼라 연산벡터의 각 원소에 대해 연산을 진행한다.2.벡터와 벡터 연산각 벡터의 같은 인덱스끼리 연산한다.python의
14.📕Week3 day2(Numpy 실습예제1)

\*day2에 했던 내용들은 제외하고 작성했습니다.numpy의 random함수를 이용하여 랜덤 배열을 생성해봤습니다.randn()에 모양을 인자로 주어 배열을 생성합니다. 이때, randn()에 들어간 인자의 순서대로 차원의 크기가 정해집니다.normal()은 정규 분
15.📕Week3 day2(Numpy 실습예제2)

같은 차원이지만 다른 모양을 가진 배열 간의 연산에서 어떻게 브로드캐스팅이 적용되는지 살펴보았습니다.2차원 배열(행렬) 간의 덧셈 연산을 해봅시다. 예시로 3 x 3 배열(A)과 1 x 3 배열(B) 사이에 덧셈 연산, 그리고 3 x 3 배열(A)과 2 x 3 배열(C
16.📕Week3 day3(Pandas)

pandas는 데이터 조작 및 분석을 위한 파이썬 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리이다. 출처 : 위키피디아pandas라이브러리를 import한다.1-D(1차원) labeled array인덱스를 지정해줄 수 있음series는 numpy와 유사하다.딕셔
17.📕Week3 day4(Matplotlib)

matplotlib은 파이썬에서 데이터를 시각화해주는 라이브러리이다.1.라이브러리 임포트matplotlib라이브러리를 import하는데 주로 matplotlib.pyplot을 많이 사용합니다.2.자주 사용되는 Plotting의 Options크기 : figsize제목 :
18.📕Week4 day1(Flask)

flask를 사용하기 전에 파이썬 가상환경에서 진행하기 위해 가상환경을 설정한다.CLI환경에서 가상환경을 만들고 싶은 디렉토리로 움직인다.Programmers/flask-proj 나는 이경로에 설정했다.가상환경 생성 모듈 설치pip install virtualenvve
19.📕Week4 day3(EDA)

EDA(탐색적 데이터분석) EDA의 Process 분석의 목적과 변수 확인 데이터 전체적으로 살펴보기 데이터의 개별 속성 파악하기 1. 분석의 목적과 변수 확인 먼저 분석할 데이터를 먼저 불러옵니다. 분석 목적 : 살아남은 사람들은 어떤 특징을 가지고 있었는가
20.📕Week5 day1(Django)
Django는 파이썬으로 만들어진 무료 오픈소스 웹 애플리케이션 프레임워크(web application framework)이다.이번에도 CLI환경에서 만든 가상환경에 진행한다.가상환경 생성 방법은 이전 포스트를 확인하자!먼저 pip install을 통해 django를
21.📕Week5 day2(Django 동적 웹페이지 만들기)
django에서 어떤 정보의 요청에 대해 DB를 관리하는 곳이 Model이다. Template과 View에 요청된 정보를 제공한다.django는 SQL을 사용할 수 있지만 내장되어 있는ORM object을 사용해서 DB를 다룰 수 있다.models.py를 작성해서 Mo
22.9월 인공지능 데브코스 회고

프로그래밍, 개발이라는 것에 관련된 것들을 공부한 지는 20년도 군대에 있을 때 시작했지만 얼마 전까지 제대로 열심히 뭔가를 해본 적이 없었던 것 같다. 그래서 이번 인공지능 데브코스를 시작하게 되면서 적어도 이 정도는 해야 공부했다고 말할 수 있을 것 같았다.처음 데
23.📕Week12 day1(SQL)
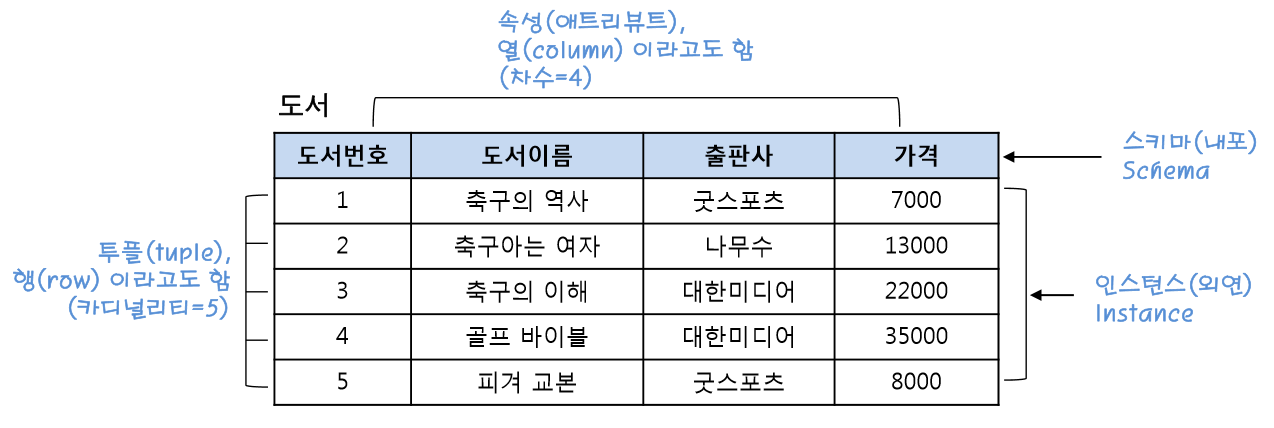
구조화된 데이터를 저장하는 스토리지엑셀 스프레드시트 형태의 테이블로 데이터를 정의하고 저장한다.가장 밑단에는 테이블들이 존재테이블은 데이터베이스(or스키마)라는 폴더 밑으로 구성레코드들로 구성(행)레코드는 하나 이상의 필드(컬럼)로 구성(열)필드는 이름과 타입과 속성(
24.📕Week12 day2(DDL,DML)
다수의 SQL 문을 실행한다면 세미콜론으로 분리한다.ex) sql문1;sql문2SQL 주석: -- 인라인 한줄짜리 주석, /--/ 여러 줄 주석SQL 키워드는 대문자를 사용한다던지 하는 나름의 포맷팅이 필요팀프로젝트라면 팀에서 사용하는 공통 포맷이 필요테이블/필드 이름
25.📕Week12 day3(DDL,DML)

테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산한다.두 단계로 이루어짐1.먼저 그룹핑을 할 필드를 지정(하나 이상의 필드가 될 수 있음)GROUP BY로 지정(필드 이름을 사용하거나 필드 일련번호를 사용)2.다음 그룹별로 계산할 내용을 지정여기서 AGGREGA
26.📕Week12 day4(JOIN)
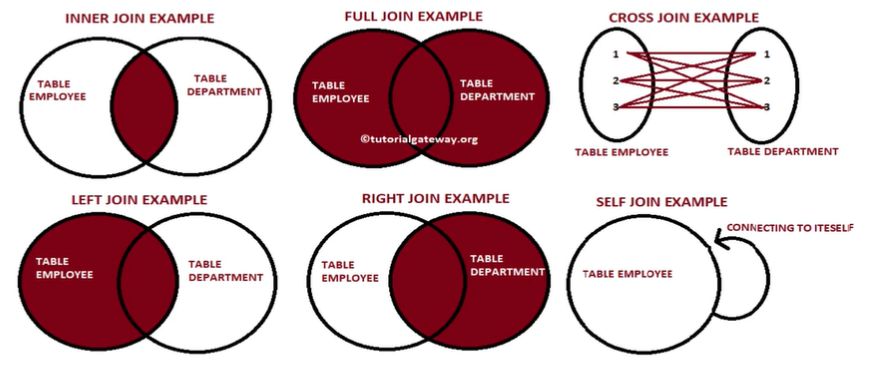
SQL JOIN은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 merge하는 것.이는 star schema로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용된다.왼쪽 테이블을 LEFT, 오른쪽 테이블을 RIGHT라고 하면 JOIN의 결과는 양쪽의 필드를
27.📕Week13 day1(데이터 팀의 역할)

데이터 팀의 Mission신뢰할 수 있는 데이터를 바탕으로 부가가치 생성데이터의 품질이 보장되어야! (garbage in garbage out)데이터를 빠르게 가져올 수 있어야 한다.많은 경우 데이터 분석은 회사의 주력 사업이 아니라 부가적인 가치를 생성해내는 일데이터
28.📕Week13 day3(SparkSQL)

구조화된 데이터 처리를 위한 Spark 모듈대화형 Spark 셸이 제공됨하둡 상의 데이터를 기반으로 작성된 Hive 쿼리의 경우 변경없이 최대 100배까지 빠른 성능을 가능하게 해줌데이터프레임을 SQL로 처리 가능RDD 데이터는 데이터프레임으로 변환한 후 처리 가능외부