
오늘은 LLM 모델 선정을 위한 모델 비교 !
챗봇의 가장 핵심이자, 대화 성능에 지대한 영향을 미치기 때문에 다양한 부분에서 비교와 테스트가 필요하다
내가 프로젝트를 진행했던 곳은 모델을 자유롭게 쓸 수 있도록 지원해주셔서, 정말 핫한 모델들을 거진 다 써본 것 같다🤗(대신 비용 산정이 겁나 힘들었다)
OpenAI - GPT-4o / 4o-mini
Anthropic - Claude 3.5 sonnet
AWS bedrock - 3.0 sonnet, haiku, llama3

1. OpenAI - GPT-4o / 4o-mini
그 당시 OpenAI의 최신 모델이었던 GPT-4o와 2024년 7월 18일 출시된 GPT-4o-mini를 활용했다.
- GPT-4o-mini: 소형 모델 중 뛰어난 성능, GPT-4보다 더 최신 훈련데이터(4o: 21년 9월, 4o-mini: 23년 10월)
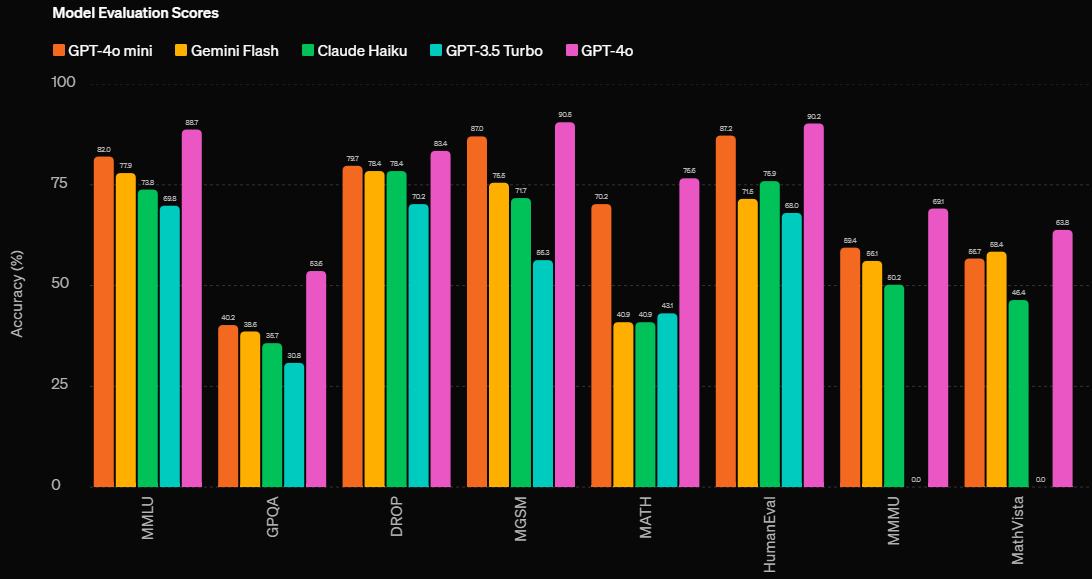
발표 당시 openai에서 발표한 소형 LLM 성능 비교. GPT-4o와 견줄 정도로 뛰어나다 !
2. Claude 3.5 sonnet
2024년 6월 21일 출시된 Claude 3.5 Sonnet은 딱 내가 프로젝트를 진행하고 있을 때 등장했다.
LLM에 대해 잘 알지 못했을 때는 "어, 새로운 LLM이다 한번 써볼까?" 했는데,
LLM은 워낙 자주 새로운 모델이 나오기 때문에 굳이 할 필요는 없었다.
"그치만 ! 이렇게 할 수 있는 기회가 얼마나 있겠어🧐!" 를 외치며 테스트에 넣었다
"Claude 3.5 Sonnet: 기존 Claude 3 Opus보다 두 배 빠른 속도로 작동, 다른 LLM 모델과 비교하여 좋은 성능과 저렴한 토큰 당 가격(이전 모델인 Claude 3 Sonnet과 가격이 동일함), 이번 프로젝트에서 신 기술을 파악하고 사용해보기 위해 해당 모델을 테스트 해보기로 함"
-> 제작 보고서에 이렇게 적음ㅋㅋㅋㅋㅋㅋㅋ 엌
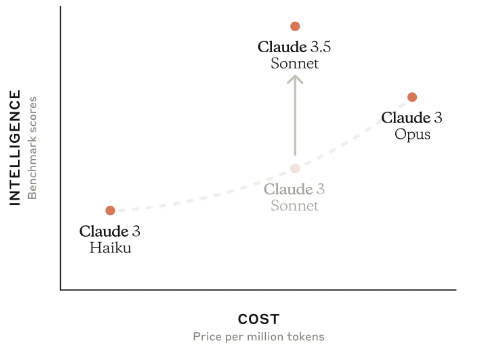
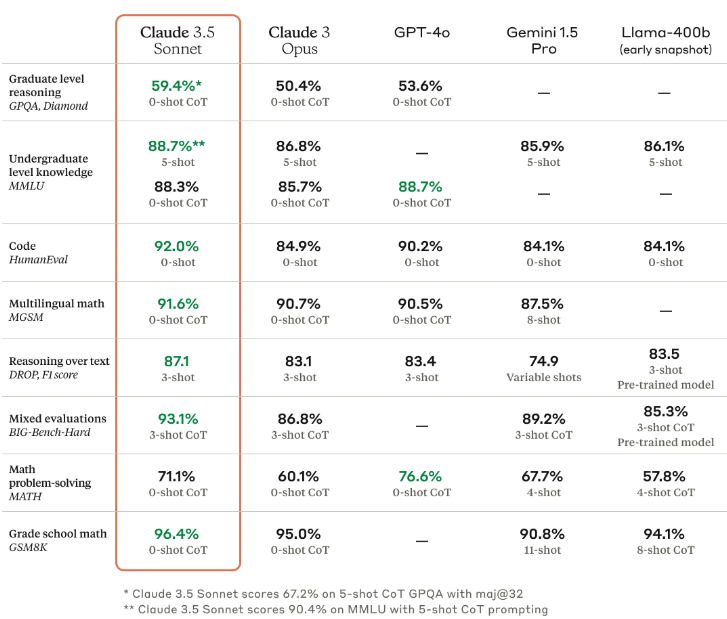
Anthropic에서 발표한 자료. cost는 그대로인데 더 좋아진 성능이었다
아마 LLM은 점점 저렴해지지 않을까. 기존보다 좋은 성능, 저렴한 가격
3. AWS bedrock
이 중 3.0 sonnet, haiku, llama3은 AWS계정을 연동하고, bedrock로 모델을 불러서 테스트를 진행해봤는데 답변 평균 시간이 25초 였다.
개인적으로 llama를 꼭 써보고 싶었는데 챗봇이 답변을 내는 데 이렇게 긴 시간을 쓰게 할 수는 없으니
열심히 코드를 작성했지만 눈물을 머금고 보내줬다😭

4. 성능 비교
모델의 성능을 어떻게 비교할 것인지는 도메인과 챗봇의 활용에 따라 달라지겠지만,
우리가 생각했을 때 성능을 비교하기 위해 필요하다고 느낀 기준은 세 가지 였다.
1. 지연 시간
2. 가격
3. 답변 품질
LLM 성능 비교를 위해 사전 준비된 KDT 교육 운영 관련 10가지 질문으로 테스트를 진행하였다.
| 번호 | 질문 |
|---|---|
| 1 | 각 과정에 대해서 설명해주세요. |
| 2 | 훈련장려금 얼마 받을 수 있나요? |
| 3 | 내일배움카드에 대해서 설명해줘 |
| 4 | 교육을 수료하면 무조건 인턴 될 수 있나요? |
| 5 | 제적 기준이 뭐야? |
| 6 | 교육비가 따로 드나요? |
| 7 | 예전에 KDT 과정을 들었으면 이 과정 못 듣나요? |
| 8 | PC 지원 뭐 해줘요? |
| 9 | 온라인 과정은 따로 없는 거죠? |
| 10 | 휴가 이틀 연속 써도 돼요? |
답변 품질에 대한 기준은 전문가의 의견을 담았으면 좋았을 테지만,
프로젝트 때는 기한이 촉박했다 ㅠㅠ
그래서 관련 논문을 참고해서 3가지의 구분 기준을 만들었다.
| 번호 | 구분 기준 |
|---|---|
| 1 | 질문의 답을 포함하고 있는가? |
| 2 | 질문의 의도를 파악하였는가? |
| (그래서 질문의 답만 간결히 내놓았는가?) | |
| 3 | 사람이 말하는 것처럼 자연스러운가? |
그래서 만들어진 LLM 간 비교 그래프 📊
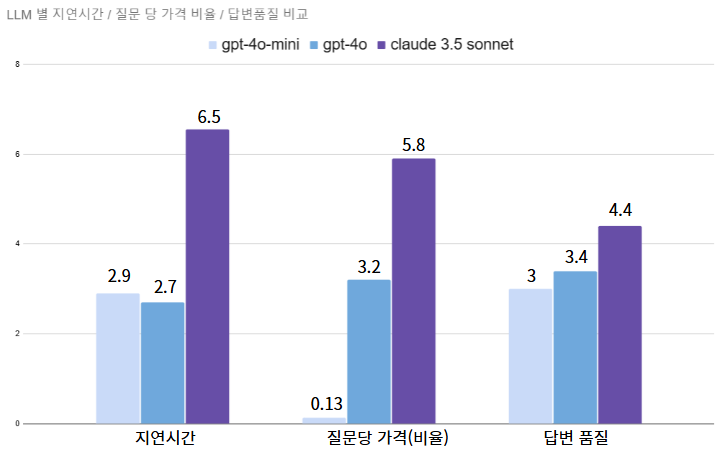
- 지연시간은 클로드가 가장 오래 걸렸고, 그 뒤로 4o-mini, 4o 순이었다.
- 질문당 가격*은 그래프 비교를 위해 비율로 계산하였다. 4o-mini가 월등하게 저렴한 가격이었고, 클로드가 가장 비쌌다.
/* 질문당 가격(가격당 비율)
질문당 가격을 어떻게 산정했을까?
우리 팀은 이런 순서로 진행 했다
1) 질문 10개의 출력 값 기준
→ 모델의 입력 값 보다 출력 값이 비싸기 때문에 !
2) 출력에 대한 평균 토큰 수 계산(각 모델의 토크나이저를 통해 계산함)
3) 평균 토큰 수에서 4o-mini에만 1/33(4o 보다 33배 저렴함)을 곱해줌
내가 그냥 무거운 모델을 좋아하는 건가? 개인적으로 claude 3.5를 쓰고 싶었는데 그래프에서 보다시피 시간이 무려 6.5초 였다 ㅠㅠ
그래프를 보고 우리는 GPT-4o-mini를 선택할 수 밖에 없었다.... 토큰당 가격이 0.13 이라니 ㅠㅠ
다른 모델들과 너무나도 비교되는 가격에 주저앉을 수밖에 없었다😥
답변 테스트📑
하지만 테스트를 멈출 수 없지. 이번엔 똑같은 질문을 던졌을 때 답변의 차이가 얼마나 나는지 테스트 했다
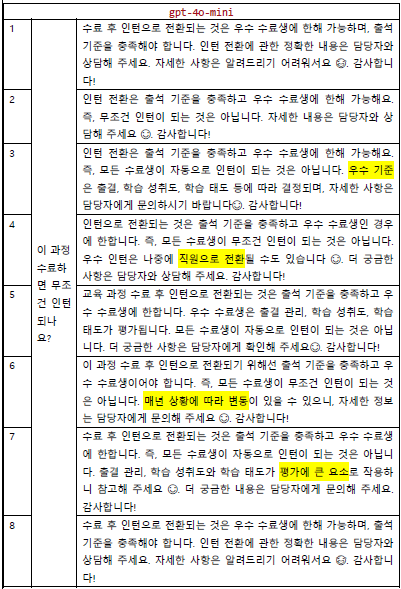
- 4o-mini
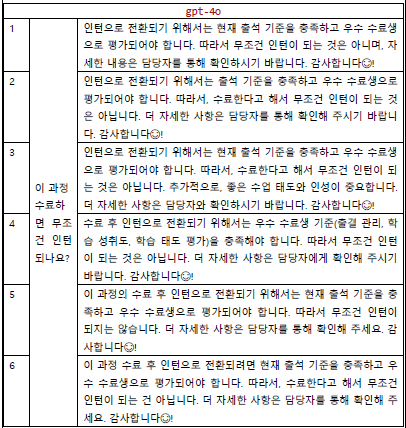
- 4o

- claude
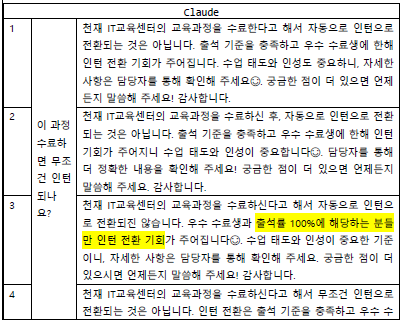
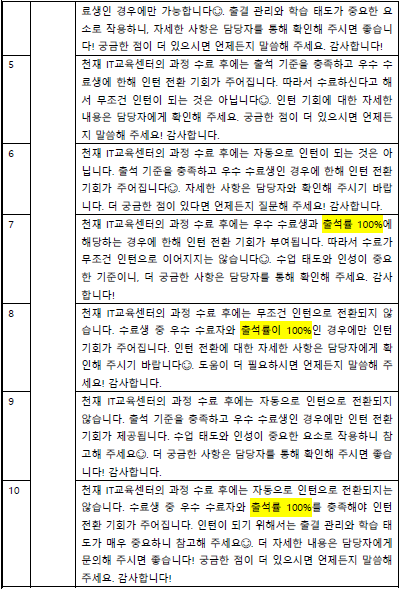
동일한 질문을 10번 던졌을 때 (실제로는 20-30번 정도는 해야한다고 함) 세 모델 다 답변이 크게 벗어나지 않았다.
더 자세하고 쉽게 풀어준다? 라는 느낌을 준건 claude 였다.
이렇게 모델을 써보면서 비교해볼 때, 이건 랭체인으로 한게 아니라서 모델을 불러오는 코드를 하나하나 다 짰더란다
어쩐지 "모델들을 불러오는게 조금씩 다른데 다들 어떻게 비교하지?" 했는데
랭체인을 먼저 배웠으면 좋았을걸 ㅠㅠ
하지만 랭체인으로 하지 않고 내 손으로 모델을 불러오고, 답변을 출력해보면서 모델의 구조를 잘 알게 되었다🥰
###################### Claude 모델 관리 ###################### class ClaudeManager: def __init__(self, api_key, model_id): self.client = anthropic.Anthropic(api_key=api_key) self.model_id = model_id self.context = None # 초기화 def set_context(self, context): self.context = context def generate_answer(self, messages, system_prompt): try: # Claude API는 system_prompt를 별도로 전달받으므로 제거 filtered_messages = [ message for message in messages if message["role"] != "system" ] for msg in messages: logger.info(f"Role: {msg['role']}, Content: {msg['content']}") # Claude API 호출 response = self.client.messages.create( model=self.model_id, max_tokens=1000, temperature=0, system=system_prompt, messages=filtered_messages ) # 응답 처리 answer = response.content[0].text return answer, messages except Exception as e: logger.error(f"Error invoking Claude model: {e}") return None, messages ###################### GPT 모델 관리 ###################### class GPTManager: def __init__(self, api_key, model_id): self.api_key = api_key self.model_id = model_id def generate_answer(self, messages): try: # 로그에 메시지 출력 # logger.info("GPTManager - Messages:") for msg in messages: logger.info(f"Role: {msg['role']}, Content: {msg['content']}") body = { "model": self.model_id, "messages": messages, "max_tokens": 1000 } url = "https://api.openai.com/v1/chat/completions" headers = { "Content-Type": "application/json", "Authorization": f"Bearer {self.api_key}" } response = requests.post(url, headers=headers, json=body) response_data = response.json() if 'choices' in response_data and len(response_data['choices']) > 0: answer = response_data['choices'][0]['message']['content'].strip() else: logger.error(f"'choices' not found in response: {response_data}") answer = None return answer, messages except Exception as e: logger.error(f"Error invoking OpenAI GPT-4 model: {e}") return None, messages
실제로 내가 작업했던 모델 class.
같아 보여도 실제로는 조금 다르게 생겼다
하지만 랭체인에서는 그냥 모델 라이브러리만 선택하면 된다는 ㅠㅠ 슬픈 이야기 ㅠㅠ
이렇게 모델의 성능을 비교하면서
"와... 재밌다...!🫡"
라는 생각을 정말 많이 했다
그리고 이렇게 모델을 알아가는 과정이 LLM으로 진로를 결정한 계기가 되었다고 생각한다
아직 공부할게 더 많지만 하나씩 차근차근 해나가자 !!!

