
어찌저찌 프로젝트를 진행하고 있는 삐약이들🐣
나는 중간 프로젝트 때 해보지 않은 DB를 해보고 싶어 Opensearch를 맡았고, 모델에 관심이 많아서 모델 쪽을 함께 하기로 했다
모델을 선정하기 전에 기본 틀을 만들어두고
그 안에서 RAG 방식을 구현한 챗봇을 제작하였는데
이때까지만 해도 langchain을 몰랐기도 하고, 시간 또한 촉박했다😅
인프라 구축, 모델 선정, DB 적재 및 연결, 웹 제작 까지 한번에 작업이 되었으니 말이다
원래 현업에서도 이런식으로 작업하나? 싶긴했지만
일단 내가 할 수 있는 일을 해야 했다👊
그래서 RAG 방식을 이해하고 쌩코딩을 하기 시작했다🎉
1. RAG(Retrieval-Augmented Generation)란?
- 자연어 처리(NLP)에서 질문에 대한 답을 생성할 때 외부 데이터를 검색해 이를 활용하는 기술로, 주로 LLM(대형 언어 모델)이 정보를 직접 생성하는 대신, 외부 데이터베이스나 문서에서 관련 정보를 검색한 후 그 정보를 바탕으로 더 정확하고 관련성 높은 답변을 제공한다.
RAG 단계
- Retrieval (검색): 질문과 관련된 문서나 데이터를 외부 소스에서 검색함. 이때 검색할 수 있는 데이터는 사전 학습된 모델에 포함되지 않은 외부 지식임.
- Generation (생성): LLM은 검색된 내용을 기반으로 질문에 대한 자연스럽고 유용한 답변을 생성한다.
- LLM은 사전에 학습된 내용을 토대로 답변을 생성하게 되는데, 해당 정보를 갖고 있지 않더라도 어떻게든 답변을 '생성' 해 낸다. LLM은 다음에 나올 단어를 확률적으로 예측해 문장을 생성하는 방식이므로 어떤 경우에는 잘못된 정보를 제공하게 되는데, 이를 환각현상(hallucination) 이라고 한다.
- 이 환각현상에 대응해서 나온게 RAG 방식으로, 사전에 학습된 LLM 모델에게 관련된 정보를 함께 주는 것(또는 신뢰할 수 있는 데이터베이스에서 '검색' 하게 만드는 것)이다.
- RAG 방식은 실시간으로 정확한 정보를 제공해야 할 때 유용하게 사용할 수 있다.
2. Fine-tuning VS RAG
- 모델의 성능을 향상시키기 위한 방법으로 많이 사용되는 파인튜닝과 RAG의 차이는 뭘까?
👩💻 파인튜닝: 사전 학습된 모델에 새로운 데이터나 특정 도메인에 맞춘 데이터를 추가 학습시켜, 특정 작업이나 도메인에 대해 더 잘 작동하도록 모델을 맞춤화하는 과정.
모델이 이미 학습한 내용을 기반으로 추가 학습을 수행하여 더 세밀한 조정이 이루어진다. 이 과정에서 모델의 파라미터가 업데이트되고, 모델이 새로운 데이터를 "기억"하게 되는 것🕵️♂️ RAG: 모델 자체의 매개변수를 수정하지 않고, 외부 데이터베이스나 문서에서 실시간으로 정보를 검색한 후 이를 기반으로 답을 생성.
모델이 질문을 받을 때마다 외부 데이터 소스를 실시간으로 검색하여 정보를 사용한다. 이 과정에서 모델의 파라미터는 수정되지 않으며, 외부 데이터를 단지 "참고"하는 것.
🎈 처음 RAG를 공부했을 때 많이 참고했던 Youtube
https://youtu.be/WWaPGDS7ZQs?si=o89ZDsPCsL2cmBwE
자세하고 친절하게 알려주신다 🤗
3. 어떻게 구현했을까 ?
전 시리즈를 보았다면 알겠지만 우리 팀의 경우는 외부 데이터베이스를 opensearch로 정하고, 그 쪽에서 문서를 검색해 LLM에 던져주는 프로세스를 짜게 되었다.
1) project architecture
프로젝트를 진행하면서 세웠던 아키텍처
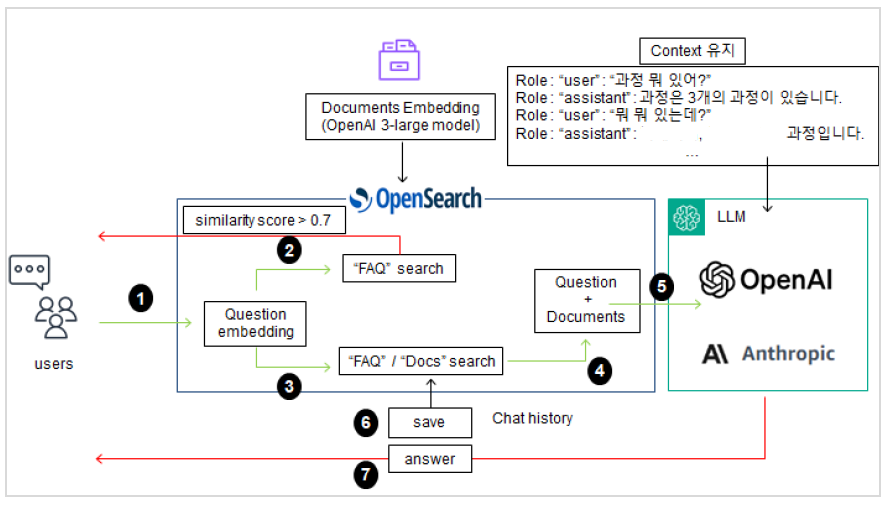
유저가 질문을 던지면 먼저 질문을 임베딩시키고, 질문과 답변이 있는 FAQ 문서를 검색한다. 거기에 질문이 0.7 이상 유사한 값을 보이면 LLM을 거치지 않고 바로 답변을 출력한다.
유사도가 0.7 미만이면 FAQ와 DOCS 문서를 함께 검색하여 관련된 문서를 최대 6개 (유사도는 0.2 이하로 cut-off를 지정하여 관련 없는 내용을 가져오지 못하게 구현)를 LLM에 함께 던지게 된다. 질문과 문서를 함께 받은 LLM은 이에 맞게 답변을 출력한다.
from chatbot.settings import OPENSEARCH_SEARCH_SIZE, INDEXNAME
from chatbot.models import BedrockManager
from settings import bedrock_region, Bedrock_model_id
import re
# 로거 설정
from chatbot.custom_logging import logger
################# 답변 포맷팅 함수 #################
def add_paragraph_breaks(answer):
"""
한글 뒤에 오는 점에 개행 문자 추가
숫자 뒤의 점은 개행 문자가 추가되지 않도록 처리
"""
# 한글 뒤에 오는 점에 개행 문자를 추가
formatted_answer = re.sub(r'(?<=[가-힣])\.\s*(?=\S)', '.\n', answer)
return formatted_answer
def format_answer(answer):
return f"{answer} \n 추가적인 문의사항이 있으시면 언제든 이야기해 주세요😊."
################# 답변 관리 함수 #################
def generate_answer(query, opensearch_client, model_manager, system_prompt, model_name, previous_history=None):
"""
질문 쿼리를 받아 답변을 생성하고 인덱싱하는 함수
"""
try:
documents = [] # 검색된 문서 내용을 저장할 리스트
# FAQ 인덱스에서 유사 문서 검색
faq_documents = opensearch_client.chat_his_search_similar_documents(query, k=1, index_name='faq', similarity_threshold=0.7)
if faq_documents:
# FAQ에서 유사 문서를 찾은 경우 해당 문서를 포맷팅하여 반환
faq_answer = faq_documents[0]['text'] # 첫 번째 문서의 텍스트 추출
formatted_answer = format_answer(faq_answer)
breaks_format_answer = add_paragraph_breaks(formatted_answer)
return breaks_format_answer, [faq_answer]
# 유사 문서 검색 및 검색 결과에서 컨텍스트 추출
start_time = time.time()
# chathistory 인덱스에서 이전 답변 검색
previous_answers = opensearch_client.chat_his_search_similar_documents(query, k=3, index_name='faq', similarity_threshold=0.2)
context = ""
if previous_answers:
previous = [doc['text'] for doc in previous_answers]
documents.extend(previous)
context += " ".join(previous) + " "
search_results = opensearch_client.search_similar_documents(query, OPENSEARCH_SEARCH_SIZE, INDEXNAME)
if search_results:
new_documents = [doc['text'] for doc in search_results]
documents.extend(new_documents)
context += " ".join(new_documents)
else:
logger.warning("No relevant documents found.")
end_time = time.time()
elapsed_time = end_time - start_time
logger.info(f"search_documents_time: {elapsed_time:.2f} seconds")
# 모델 매니저를 통해 답변 생성
start_time = time.time()
if previous_history:
# 이전 대화 기록이 있는 경우
result = model_manager.ModelSelector(query, context, system_prompt, model_name, previous_history)
else:
# 이전 대화 기록이 없는 경우
result = model_manager.ModelSelector(query, context, system_prompt, model_name, [])
# 반환값 체크
if isinstance(result, tuple) and len(result) == 2:
answer, _ = result
else:
logger.error("ModelSelector returned an unexpected number of values.")
return "An error occurred during answer generation.", None
end_time = time.time()
elapsed_time = end_time - start_time
logger.info(f"LLM_answer_time: {elapsed_time:.2f} seconds")
return answer, documents
except Exception as e:
logger.error(f"An error occurred(generate_answer): {str(e)}")
return "An unexpected error occurred.", None답변을 생성할 때 문맥유지를 고려해서 코드를 작성하다보니 굉장히 길어졌다..^0^;;
TMI 🙄 : 해당 프로젝트에서 파인튜닝을 하지 않고 RAG 방식을 사용한 이유
- 교육 운영은 정보가 자주 바뀌고, 정확한 답변을 내야 한다
- 모델을 훈련시키는 것이 아닌, 문서가 저장된 DB를 수정해 지식 수정을 효율적으로 할 수 있음
- 큰 모델을 파인튜닝하는 것은 많은 리소스가 필요하고, 학습과 저장에 많은 비용이 들지만 RAG는 사전 학습된 모델을 활용하고 검색 시스템 최적화에 집중할 수 있음
실제로 우리는 문서를 한번에 받은 것이 아니라 여러번 나누어서 받았다.
이런 상황에서 모델을 그 때마다 학습시킬 수 없었고, 문서를 받는 대로 opensearch에 삽입해 성능을 끌어올렸다.
보안상 어쩔 수 없는 조치였지만 교육생의 신분으로서 할 수 있는 범위가 한정되어 있다는 것은 프로젝트를 할 때 많은 아쉬움이 있었다.
2) 코드로 구현하기
- pipeline
/root/ai/myapi/backend/
├── main.py
├── generate_chatbot_response.py
├── custom_logging.py
├── insert_data.py
├── settings.py
├── chatbot/
│ ├── answer.py
│ ├── IndexManager.py
│ ├── models.py
│ ├── opensearch_client.py
│ ├── PromptManager.py
│ └──TextEmbeddingManager.py
├── logs/
│ └── *chatbot_server.log.py
├── requirments.txt
└── .env
파일이 참 많은데, 랭체인으로 구현하지 않으면 어쩔 수 없다. 임베딩 안할거에요? 데이터 안넣을거에요?(눈물)
📚파일 설명(backend)
| 파일명 | 설명 |
|---|---|
main | FASTAPI 실행 |
generate_chatbot_response | Chatbot 폴더에 정의된 class 실행 |
custom_logging | 로그 데이터 기록을 위한 파일 |
insert_data | 데이터 삽입을 위한 파일 |
settings | 민감정보 등 정의 |
requirments | 필수 라이브러리 정의 |
.env | 환경변수 정의 |
chat | |
answer | 답변 생성 클래스 |
IndexManager | 인덱스 생성, 삭제, 삽입 클래스 |
models | 모델 별 클래스 정의 |
opensearch_client | Search class 정의 |
PromptManager | System prompt, User prompt 정의 |
TextEmbeddingManager | 임베딩 class |
내가 깃허브에 정리해둔 파일 설명
엄청 많은데 결국에는 모델파일, DB(opensearch)파일, 답변파일, 실행 파일 정도로 나누었다고 보면 된다.
기능 별로 나누려고 하다보니 좀 많아진 느낌이 없지 않아 있다.
PromptManager 파일도 있는데 이건 다음에 포스팅하도록 한다😎 !
import os import requests import json from chatbot.custom_logging import logger class TextEmbeddingManager: def __init__(self, api_key, client, EMBEDDING_MODEL): self.api_key = api_key self.client = client self.EMBEDDING_MODEL = EMBEDDING_MODEL def get_embedding(self, text): """ 지정된 모델을 사용하여 주어진 텍스트의 임베딩을 가져오기 """ url = "https://api.openai.com/v1/embeddings" # OpenAI 임베딩 API URL headers = { "Authorization": f"Bearer {self.api_key}", # API 인증 헤더 "Content-Type": "application/json" # 요청 본문 형식 } data = {"input": text, "model": self.EMBEDDING_MODEL} # 요청 데이터 try: response = requests.post(url, headers=headers, json=data) # POST 요청 response.raise_for_status() # HTTP 상태 코드 검사 response_data = response.json() # 응답 JSON 파싱 embeddings = response_data.get('data', []) # 임베딩 데이터 추출 if embeddings: return embeddings[0]['embedding'] # 첫 번째 임베딩 반환 else: logger.error("API 응답에서 임베딩을 찾을 수 없습니다.") # 임베딩이 없을 경우 예외 발생 ######## HTTP 오류 발생 시 메시지 출력 ######## except requests.exceptions.HTTPError as http_err: logger.error(f"HTTP 오류 발생: {http_err}") if response.status_code >= 400 and response.status_code < 500: logger.error("클라이언트 오류입니다. 요청을 다시 확인해주세요.") elif response.status_code >= 500 and response.status_code < 600: logger.error("서버 오류입니다. 잠시 후 다시 시도해주세요.") return None except requests.exceptions.RequestException as e: logger.error(f"요청 오류: {e}") return None
opensearch 관련 코드와 model에 관련된 코드는 저번 포스팅에 적었으니 이번에는 임베딩 코드를 가져왔다.
우리 팀은 openai의 3-large 모델을 썼다. ada도 고려하였으나 텍스트 임베딩의 경우 의도, 문맥에 따른 다양한 특징이 많기 때문에 차원이 클수록 좋다(실제 3-large는 3,072차원을 가지고 있다. ada는 1,536차원이다. 실제 테스트 해보면 3-large 모델로 임베딩한 텍스트가 더 성능이 좋았다)
def faq_load_and_create_embeddings(self, file_paths): """ 자주 묻는 질문(크롤링 파일) 데이터 임베딩 질문(question)을 임베딩하여 받은 질문과 유사도 계산 """ all_data = [] # 모든 데이터를 저장할 리스트 if isinstance(file_paths, str): # 단일 파일 경로가 전달된 경우 리스트로 변환 file_paths = [file_paths] for file_path in file_paths: with open(file_path, 'r', encoding='utf-8') as file: # JSON 파일 열기 data = json.load(file) # JSON 데이터 로드 for item in data: content = item.get('question') if content: embedding = self.get_embedding(content) # 임베딩 생성 if embedding: item['embedding'] = embedding # 임베딩 추가 item['file_name'] = os.path.basename(file_path) # 파일 이름 추가 all_data.append(item) # 데이터 리스트에 추가 else: logger.error(f"Failed to get embedding for an item in {file_path}. Skipping.") # 임베딩 생성 실패 시 메시지 출력 file.close() # 파일 닫기 return all_data # 모든 데이터 반환
물론, 문서도 임베딩해야 했기 때문에 코드를 다르게 작성해줬다. json 파일로 전처리한 파일을 불러와 임베딩 시켰다.
그 후 indexmanager.py로 데이터를 삽입하고,
answer.py로 답변을 생성하는 로직을 만들고,
generate_chatbot_response.py에서 모든 파일을 실행하게 만들었다. 실제 main.py의 역할을 생각하면 되겠다
코드가 생각보다 길어져서 (드디어) 깃허브 주소를 올려본다🥰✨
https://github.com/PlutoJoshua/GenieNavi_chatbot_Project

4. 더 좋은 방법은 없었나?
1) RAG 이외 방식
-
앞서 파인 튜닝을 사용하지 않았다고 했지만 파인튜닝도 장점이 있다.
파인 튜닝으로 했다면 모델에 질문과 답변을 학습시키고, 하이퍼 파라미터를 수정해가면서 최적의 성능을 찾는 식으로 구축하지 않았을까 하는 생각. -
두 번째는 그렇게 울부짖었던 langchain😥😢😭
이 프로젝트를 계기로 랭체인에 한이 맺혀 열심히 책으로 공부하고 있다
(모델 API 지원해주실 때 했으면 더 자유롭게 했을 텐데)
import os from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.llms import OpenAI from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain.document_loaders import TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter # OpenAI API 키 설정 os.environ["OPENAI_API_KEY"] = "api-key" ################ 문서(임베딩) 관리 ################ # 문서 로더 설정 (FAQ 파일을 불러오기) loader = TextLoader('faq_data.txt') # FAQ가 들어있는 텍스트 파일 documents = loader.load() # 문서 분할기 (문서가 길면 여러 조각으로 나눔) text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) split_docs = text_splitter.split_documents(documents) # 문서 임베딩 생성 embedding_model = OpenAIEmbeddings() # FAISS 벡터 스토어에 임베딩 저장 vector_store = FAISS.from_documents(split_docs, embedding_model) ################ 검색 관리 ################ # FAQ 검색을 위한 쿼리 (질문에 대한 임베딩 생성) query = "예시 질문을 여기에 입력하세요" query_embedding = embedding_model.embed_query(query) # 유사한 문서 검색 (유사도 0.7 기준) docs_with_scores = vector_store.similarity_search_with_score(query, k=5) # 상위 5개 문서 검색 matching_docs = [doc for doc, score in docs_with_scores if score > 0.7] if matching_docs: # 유사도 0.7 이상인 답변이 있을 경우, 그 답변 출력 print("FAQ에서 유사한 답변 찾음:") for doc in matching_docs: print(doc.page_content) else: print("FAQ에서 적절한 답변을 찾지 못했습니다. 추가 문서 검색을 진행합니다.") # FAQ에서 유사한 문서를 찾지 못했을 때 추가 문서 검색 (유사도 0.2 커트 적용) related_docs_with_scores = vector_store.similarity_search_with_score(query, k=6) related_docs = [doc for doc, score in related_docs_with_scores if score > 0.2] ################ LLM 답변 관리 ################ # 검색된 문서와 함께 LLM에 전달하여 답변 생성 llm = OpenAI(temperature=0.7) # OpenAI GPT 모델 # 답변을 위한 Prompt 템플릿 정의 prompt_template = PromptTemplate( input_variables=["question", "context"], template=""" 질문: {question} 참고 문서: {context} 참고 문서 기반으로 질문에 답변하세요. """ ) # 검색된 문서의 내용을 하나로 병합 context = "\n".join([doc.page_content for doc in related_docs]) # 답변 생성 chain = RetrievalQA.from_chain_type(llm, retriever=vector_store.as_retriever()) answer = chain.run({"question": query, "context": context}) print("LLM의 답변:") print(answer)
내가 여러 파일로 작성한 내용이 꽤나 압축되어(?) 들어가있다
물론 위의 내용은 간단하게 작업한 내용이라 더 적겠지만 랭체인 만세 ㅠㅠ
2) 코드 정리
부끄러운 이야기지만 프로젝트 끝나기 일주일 전까지도 나는 내 코드를 이해하기 바빴다
기능을 너무 여기저기 세부적으로 나눠놨는지 어떤 기능을 수정하고자 할 때 파일을 하나하나 찾아야 했고, 주석을 열심히 적었다고 생각했는데 결론적으로는 줄이 길어져 더 찾기 어려워졌다
앞으로 코드를 작성할 때는 규칙성을 부여해야겠다는 생각이 들었다
3) stream 방식 구현
Ollama 포스팅에서 stream 방식을 구현하면서 괜시리 뿌듯하다는 이야기를 했는데, 그도 그럴 것이 내가 했던 프로젝트에서는 stream 방식을 구현해내지 못했다
원인으로는 여러가지가 있었는데,...
1) 유사도 0.7 이상은 LLM을 거치지 않음 -> 별도의 방식으로 구현해야 함
2) 모델에서는 구현하는 방법이 어렵지 않으나, 웹에서 stream 형식으로 받은 내용을 한 글자씩 띄우게 해야 함
웹 쪽은 챗봇 페이지를 만드는 것만으로도 벅차 stream 방식으로 구현함에 있어 시간적인 한계가 있었다. 마지막에 나라도 해볼까 싶어 한 글자씩 받는 것 까지는 구현했으나 LLM을 거치지 않는 답변에 대해서도 처리해야 했기 때문에 굉장히 이상한 모양이 되었다 ㅠ 결국 stream은 하지 않기로 했다. 다음에 제작할 챗봇은 꼭 stream 방식으로 구현하고 싶다.
/
/
이렇게 열심히 프로젝트에 대한 이야기를 했는데 내가 맡았던 부분 중 가장 핵심적인 내용이라 코드도 많고, 푸념(?)도 많았다
그만큼 내 자식같은 녀석들이다👶
개발자 양성 과정을 들으면서 "공부만 할 때보다 프로젝트를 진행할 때 더 성장했다"는 이야기를 들었는데, 백번 천번 맞는 말이다
탄탄한 기초도 중요하지만 실제로 내가 해보지 않으면 온연히 내 것으로 만들기에는 힘들다는 사실을 프로젝트 하면서 많이 느꼈다
앞으로 다양한 실무를 경험해면서 나를 더욱 성장시켜야겠다!


안녕하세요! 글 재밌게 보았고, 현재 RAG 구현 중인데 큰 도움이 되었습니다. 감사합니다!!
궁금한 점이 있는데, 실제 현업에서도 langchain을 많이 쓰나요? 향후 제가 서비스를 수정하지 못하는 상황인데(담당자가 바뀌어서) 이 경우에도 파이썬을 이용하는 것이 아니라 랭체인을 사용하는게 좋을 지 궁금합니다.