
중간프로젝트 때 못해본 DB에 손을 댄 나😊
처음보는 Opensearch에 익숙해 지느라 정말 고생했는데,
익숙해지고 나면 이보다 쉬운게 없다(NoSQL만세)
RAG 방식으로 챗봇을 구현하려면 유사도 검색과 DB의 중요도가 커질 수 밖에 없다
그래서 사용한게 opensearch!
1. opensearch 란?
참고로 오픈서치는 한국 자료가 정말 없다 그냥 없다 정말정말 없다
그래서 docs 보면서 일일히 알아보고, 해보고, 코드 짜보고, 던져도 보고, 했음🤣
✨간단한 opensearch 설명
- OpenSearch: Elasticsearch에서 포크된 프로젝트로 검색, 시각화, 데이터 탐색 등 다양한 용도로 사용
- 대규모 데이터의 실시간 검색과 분석을 지원
- OpenSearch Dashboards 를 통해 데이터 실시간 관리 가능
- 임베딩* 값을 vectorDB로 저장하여 유사도 검색
/* 임베딩(embedding): 자연어 처리(NLP)와 기계 학습에서 단어, 문장, 문서 등의 텍스트 데이터를 고차원 벡터 공간으로 변환하는 기술
OpenSearch는 Apache 2.0 라이선스 하에 제공되는 분산형 커뮤니티 기반 100% 오픈 소스 검색 및 분석 제품군으로, 실시간 애플리케이션 모니터링, 로그 분석 및 웹 사이트 검색과 같이 다양한 사용 사례에 사용됩니다. 시각화 도구 OpenSearch 대시보드와 함께 대량 데이터 볼륨에 빠르게 액세스하고 응답하며 뛰어난 확장성을 지닌 시스템을 제공합니다. k-nearest neighbors(KNN) 검색, SQL, Anomaly Detection, Machine Learning Commons, Trace Analytics, 전체 텍스트 검색 등 다수의 검색 및 분석 기능을 지원합니다.
AWS에 있는 opensearch 내용을 가져왔다.
😕Elasticsearch도 있던데🧐
맞다. 확실히 opensearch보다 Elasticsearch를 더 많이 쓰고, 관련 정보도 많은데
가장 큰 차이..... Elasticsearch는 유료다
Elasticsearch는 원래 오프소스였는데, 2.0인가 이후부터는 유료서비스로 전환되었다.
그래서 기존 무료 버전인 Elasticsearch를 포크해와서 오픈소스로 내놓은 게 opensearch이다.
프로젝트를 진행할 때 비용 절감이 최우선이었기 때문에 서버에 opensearch를 docker로 올리고 사용했다.
2. opensearch 사용하기
opensearch는 다운로드 받을 수도 있고 쉽게 yml 파일을 받아서 docker로 올릴 수 있다
교육생때는 이것마저 어디서 해야할지 몰라 우왕좌왕 했었는데,
https://opensearch.org/downloads.html
- 를 보면 다운로드라고 쓰여있다 ㅠㅠ
이걸 알았더라면... 좋았을 텐데...^^
신나게 빌드중인 나의 docker🐳
오랜만에 해보니 기억이 새록새록하다
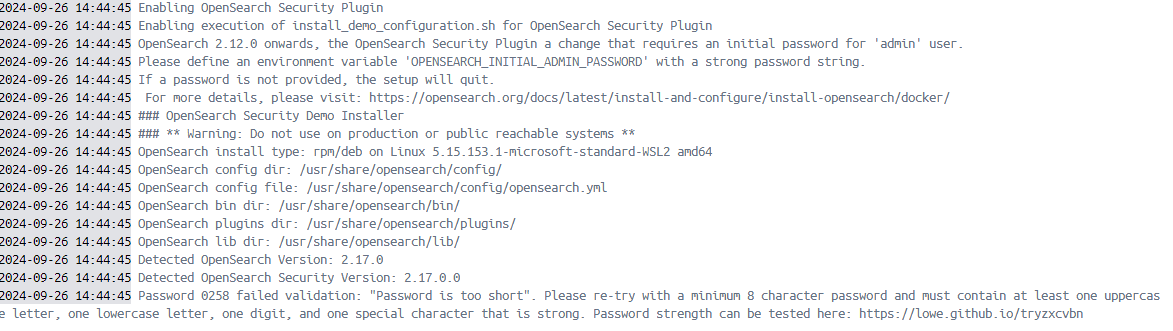
머야 근데 왜 안돼
에러메시지를 읽어보니 비밀번호가 너무 짧다고 한다😥
yml파일에서 고쳐주고 다시 빌드했다
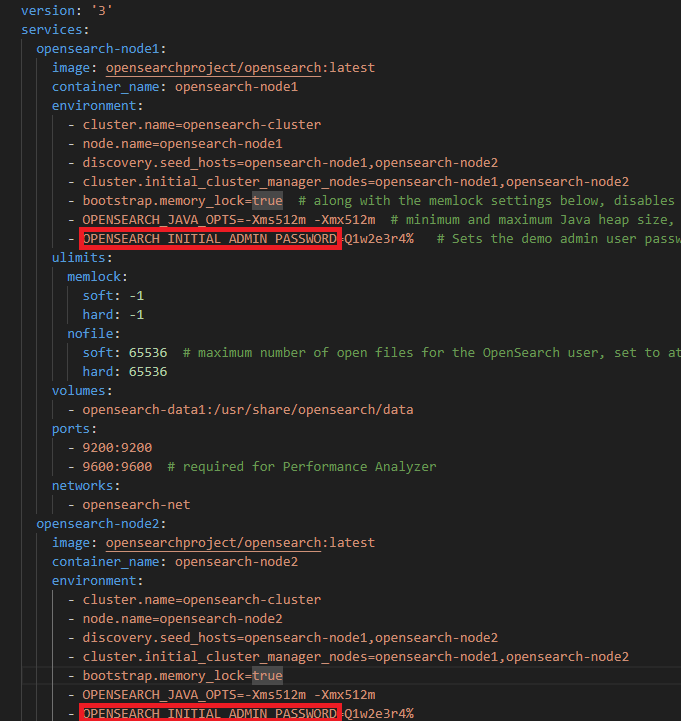
참고로 yml 파일에서 OPENSEARCH INITIAL ADMIN PASSWORD이 부분을 찾아 수정해주면 된다
대시보드에 접속할 때 로그인 해야 하기 때문에 잘 알아둬야 함
참고로 저기 써있는 비밀번호 입력하면
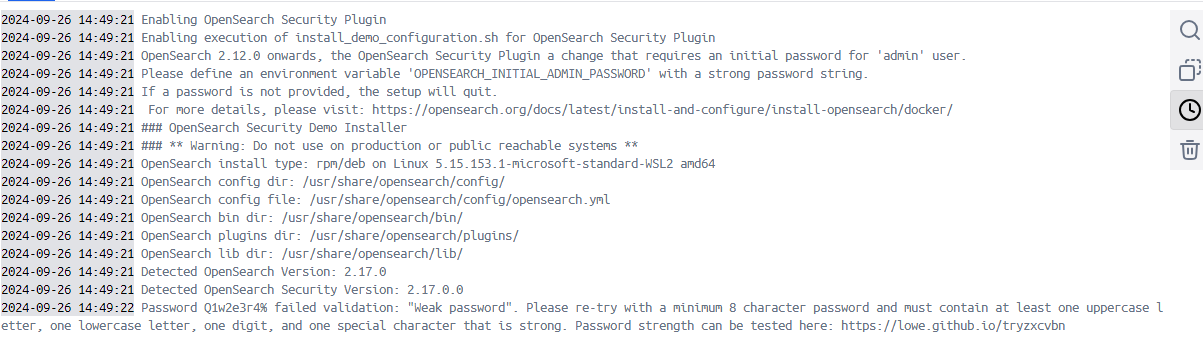
"응 너무 위험한 패스워드야 ~ 다른걸로 바꿔~^ㅠ^"
이렇게 하니 첨부터 어려운 비번을 걸어두는게 좋다
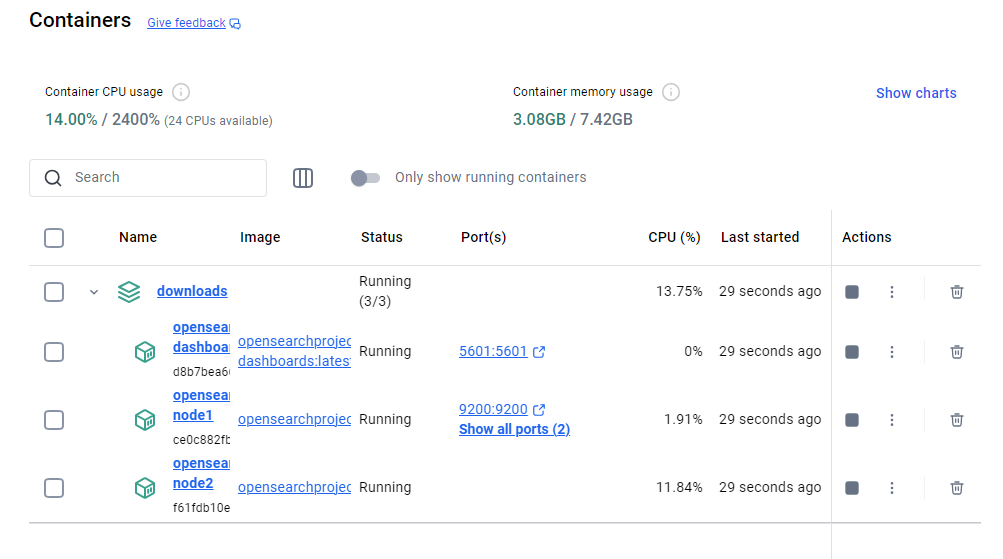
docker desktop에서 확인해보니 아주 잘 올라갔다👍
9200나 9600은 opensearch 서버 연결 포트고
데이터를 보고 싶으면 5601인 dashboards에 접속해야 한다
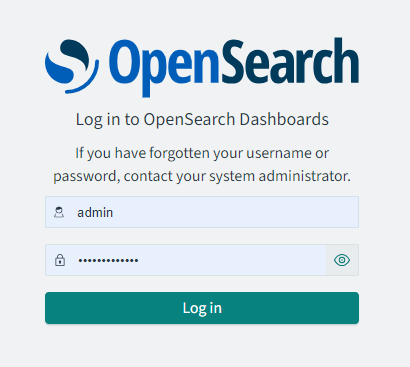
짜잔 ~
로그인은 admin / yml에서 변경한 패스워드로 하면 된다

opensearch 메인 화면 오른쪽 상단에 Dev-tools를 클릭하면 이런 콘솔 창이 나온다
쿼리를 날리면 바로 확인할 수 있다😊
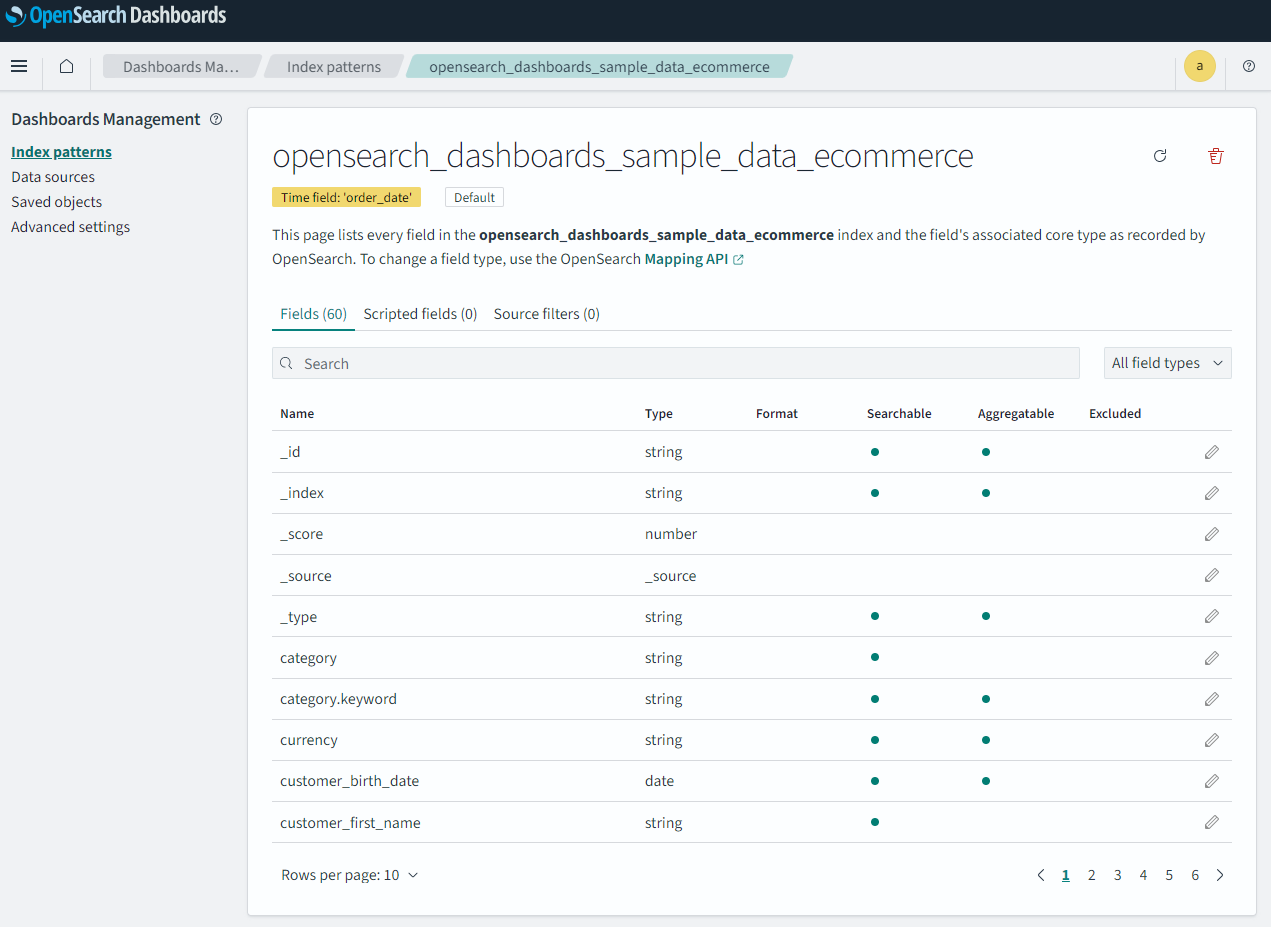
인덱스도 확인할 수 있고
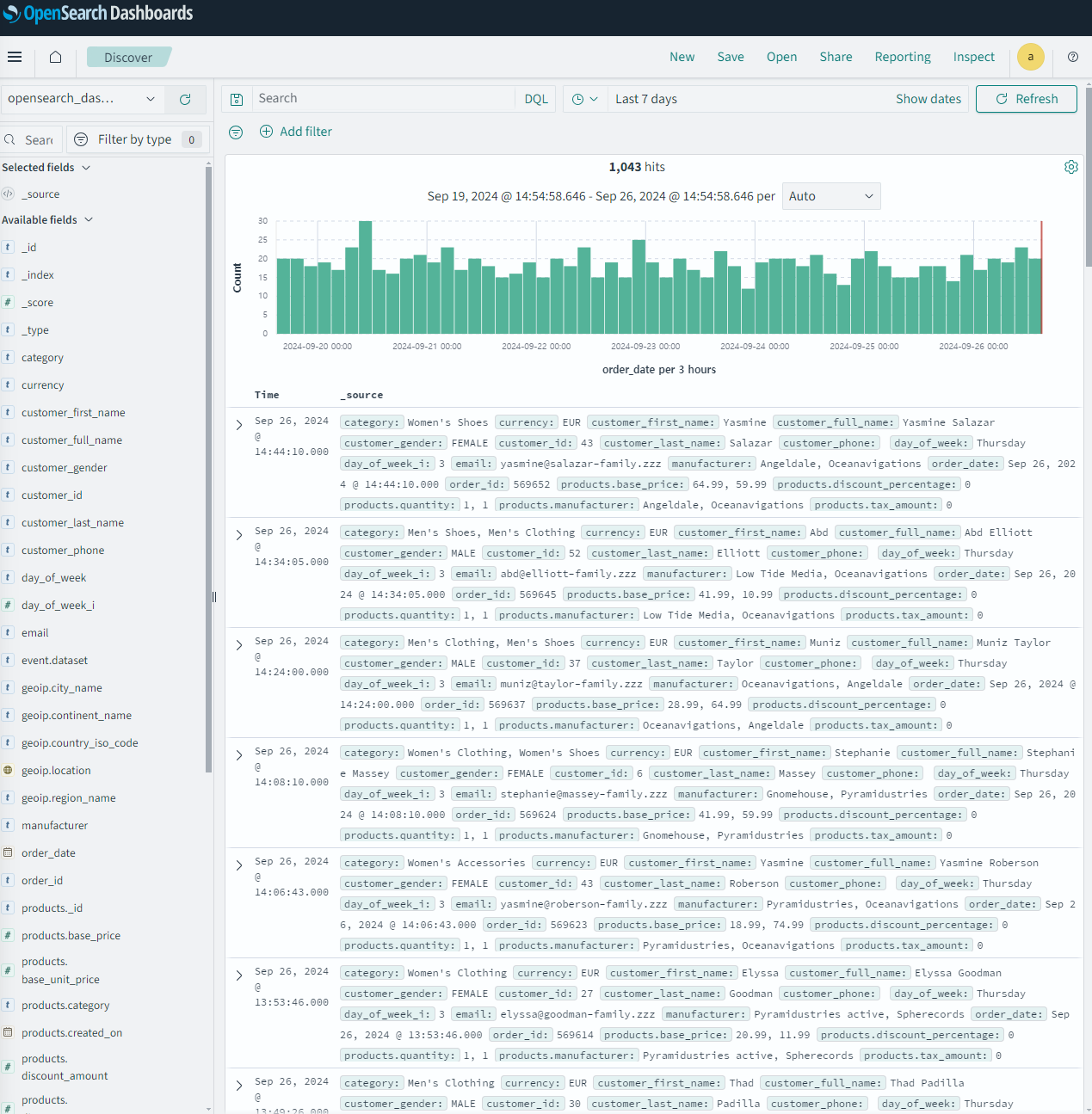
Discover에서 데이터도 직접 확인할 수 있다🖥️
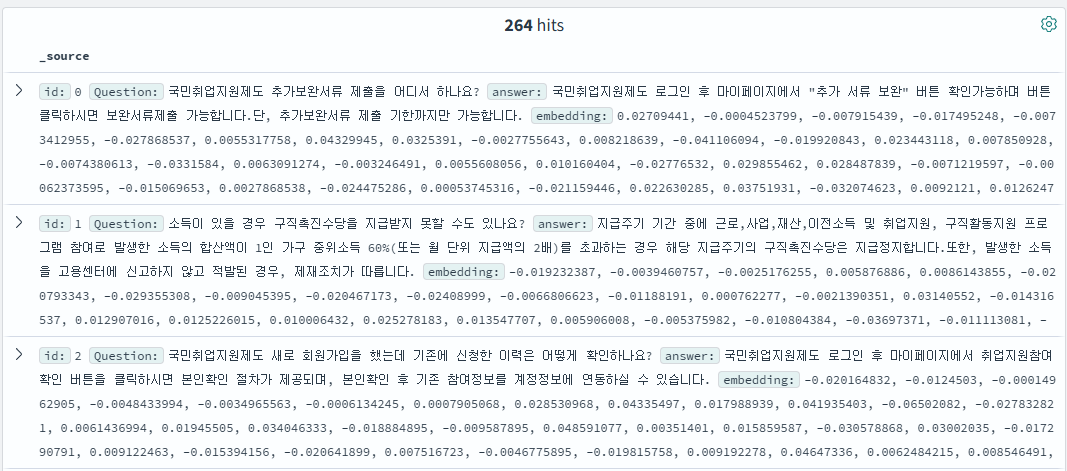
이건 내가 직접 넣은 자료인데 자랑하구 싶어서 헤헿🤭
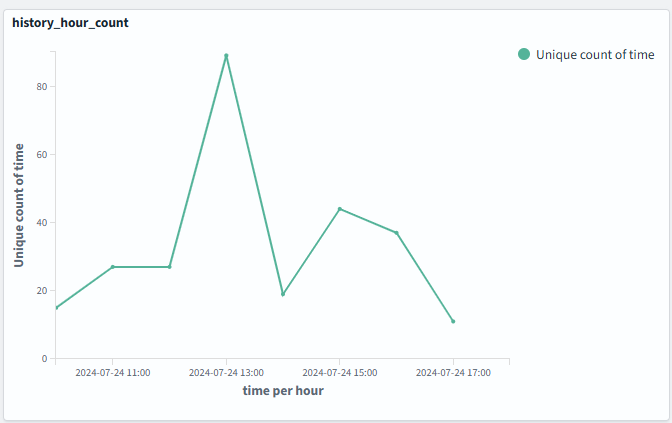
또, dashboard에서 데이터 시각화도 할 수 있다 이것도 내가 직접 시각화한 자료🤗 !
이걸로 log를 분석하는 블로그도 있었는데 못찾겠다 ㅠㅠ
3. 기본적인 코드 작성해보기
1) index 설정
오픈서치는 정말 다양한 검색 환경을 제공하는데, 특이한 점은 컬럼을 index라고 칭한다는 것이다.
그래서 초기에 인덱스를 설정해줘야 하는데, 기본값으로 설정된 값이 있어 쿼리만 변경하면 된다.
# 인덱스 생성
def create_index(self, dimension=3072):
# 인덱스 세부 정보 정의
index_config = {
"settings": {
"index": {
"knn": True # k-NN 검색 활성화
}
},
"mappings": {
"properties": {
"text": {
"type": "text",
"similarity": "BM25" # BM25 알고리즘
},
"embedding": {
"type": "knn_vector", # k-NN 벡터로 설정
"dimension": dimension, # 임베딩 벡터의 차원 수
"method": {
"name": "hnsw", # HNSW 알고리즘 사용
"space_type": "l2", # L2 거리 측정
"engine": "nmslib", # NMSLIB 엔진 사용
"parameters": {
"ef_construction": 128, # 인덱스 정확성과 속도 조절
"m": 24 # 그래프의 최대 연결 개수
}
}
},
"file_name": {
"type": "keyword" # 키워드 타입
},
"documents": {
"type": "text" # documents 필드를 text 타입으로 설정
},
"TID": {
"type": "integer" # TID 필드를 integer 타입으로 설정
},
"CID": {
"type": "keyword" # CID 필드를 keyword 타입으로 설정
}
}
}
}겁먹지 않아도 된다. 우리가 변경할 사항은 많이 없으니까.
모두 기본적으로 세팅 되어 있는 부분인데, similarity 알고리즘을 변경하거나, embedding의 타입과 dimension을 정의할 수 있다. method의 space_type으로 유사도 거리를 계산하는 방법을 조정할 수도 있다.(기본값은 유클리드 거리인 l2. 코사인 유사도로도 가능하다)
유사도는 낮은 게 좋아 높은 게 좋아?
프로젝트를 진행하면서 받은 질문이었는데, 이런것도 하나 고려 안하고 "무조건 1에 가까울수록 좋은거지!" 했더란다.
결론부터 말하자면 opensearch는 유사도가 높을수록 좋다✈️
왜 ? => 일반적인 검색 시스템에서는 점수가 높을수록 더 관련성이 높은 문서라고 판단한다. 거리 함수의 값은 거리가 가까울수록(유사도가 높을수록) 작아지므로, 이를 반대로 변환하여 점수가 높을수록 관련성이 높도록 맞추는 것!!

매개변수마다 어떤 방식이 지원되는지는 docs에 자세히 나와있다📚!
https://opensearch.org/docs/latest/search-plugins/knn/knn-index/
https://opensearch.org/docs/latest/search-plugins/knn/knn-score-script/#spaces
file_name, documents, TID, CID는 내가 넣을 데이터의 타입을 정의하는 건데,
따로 정의하지 않아도 opesearch가 데이터를 보고 알아서 정해주기 때문에 꼭 지켜줬으면 하는 타입만 지정해줘도 된다(만세)
어지럽죠 ? 저도 그랬답니다. 인덱스만 공부해도 머리터짐 ㅋ
2) 검색 기능 정의
나는 opensearch_Client class를 만들어 그 안에서 vectorDB를 관리했다.
처음에는 어떤 액션을 취할 때 마다 계속 http host를 호출했는데, 멘토님이 다른 방법으로 해보라고 하셔서 열심히 알아봤다🥲
근데 opensearchpy가 있더라구요? 진짜 좋더라구요?
from opensearchpy import OpenSearch
class OpenSearchClient:
def __init__(self, host, port, auth, embedding_manager):
self.host = host
self.port = port
self.auth = auth
self.embedding_manager = embedding_manager # TextEmbeddingManager 인스턴스
# OpenSearch 클라이언트 설정
self.client = OpenSearch(
hosts = [{'host': host, 'port': port}],
http_compress = True,
http_auth = auth,
use_ssl = True,
verify_certs = False,
ssl_assert_hostname = False,
ssl_show_warn = False,
)이렇게 클래스로 클라이언트를 설정하면, 검색할 때나 인덱스를 수정, 삭제할 때도 그냥 "client.search" 이런식으로 사용이 가능하다.
def chat_his_search_similar_documents(self, query_text, k, index_name, similarity_threshold):
"""
유사도 기반 chathistory 검색 쿼리 수행 함수 (여러 인덱스 지원 및 유사도 임계값 추가)
"""
# 질문 텍스트 임베딩
query_embedding = self.embedding_manager.get_embedding(query_text)
search_query = {
"size": k,
"query": {
"knn": {
"embedding": {
"vector": query_embedding,
"k": k
}
}
}
}
try:
response = self.client.search(index=index_name, body=search_query) # 검색 쿼리 실행
hits = response.get('hits', {}).get('hits', [])
# 유사도 임계값을 초과하는 문서들만 선택
filtered_answers = []
for hit in hits:
similarity_score = hit['_score'] # OpenSearch에서 반환하는 유사도 점수 사용
if similarity_score >= similarity_threshold:
answer = hit['_source']['answer'] # 문서 소스에서 관련 답변 추출
filtered_answers.append({
'text': answer,
'score': similarity_score
})
logger.info(f"Index: {index_name}, similarity_score: {similarity_score}")
return filtered_answers
except Exception as e:
logger.error(f"Error searching OpenSearch in index {index_name}: {e}") # 실패 시 메시지 출력
return []프로젝트 때 진행한 챗봇은 생각보다(?) 복잡하게 짜여 있는데,
1) 질문 -> 임베딩 -> o.s에서 검색 -> 0.7(similarity_threshold)이상 비슷한 QnA정보가 있음 -> 답변 그대로 출력
2) 질문 -> 임베딩 -> o.s에서 검색 -> 0.7(similarity_threshold)이상 비슷한 질문정보가 없음 -> o.s에서 문서 검색 -> 유사도가 높은 최대 6개 문서와 질문을 함께 llm에 던짐 -> 답변 출력
이런 2가지 루트가 있었다.
그래서 오픈서치에도 각 상황에 맞는 검색 함수가 필요했다.
위에 있는 함수는 오픈서치에서 검색하기 위한 검색 쿼리를 작성하고, 유사도 점수를 활용해 데이터를 return하는 데 쓰였다.
오늘은 opensearch에 대해 공부했던 내용을 정리해봤다📑
프로젝트 때 했던 내용들을 꺼내보니 정말 열심히 공부했구나 싶다
그러나 고작 두 달 안했다고 약간 버벅이는 내 모습을 보니
이렇게 벨로그에 정리하기로 마음먹어서 정말 다행이라는 생각이 들었다🤗
opensearch 깐김에 KNN 검색 말고 다른 기능들도 한번 써볼까
다음은 정말 LLM 포스팅을 해야지✊

